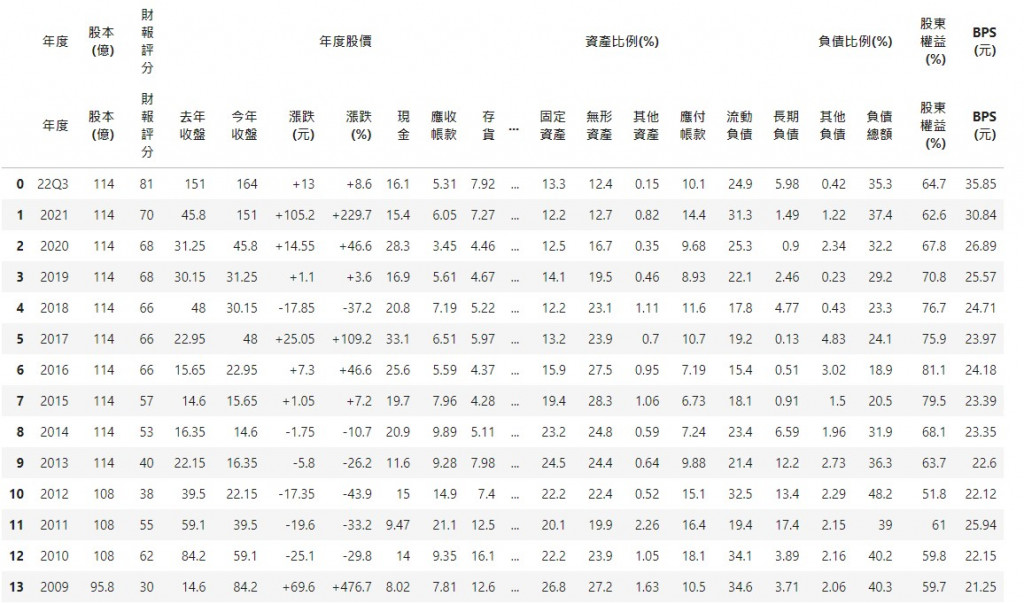
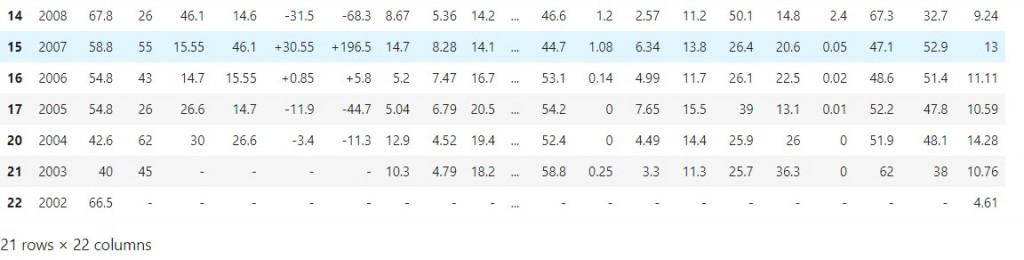
python新手請教
從goodinfo爬出表格的資料後,發現有重覆的標題欄位,請教各位高手如何刪除呢?
程式碼如下:
import requests
import bs4
import pandas as pd
#目標網站。
url = "https://goodinfo.tw/tw/StockAssetsStatus.asp?STOCK_ID=8069"
#設定headers
headers = {
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Mobile Safari/537.36'
}
res = requests.post(url,headers = headers)
res.encoding = 'utf-8'
temp = res.text
soup = bs4.BeautifulSoup(res.text,'lxml')
bus_table = pd.read_html(temp)
print(len(bus_table))
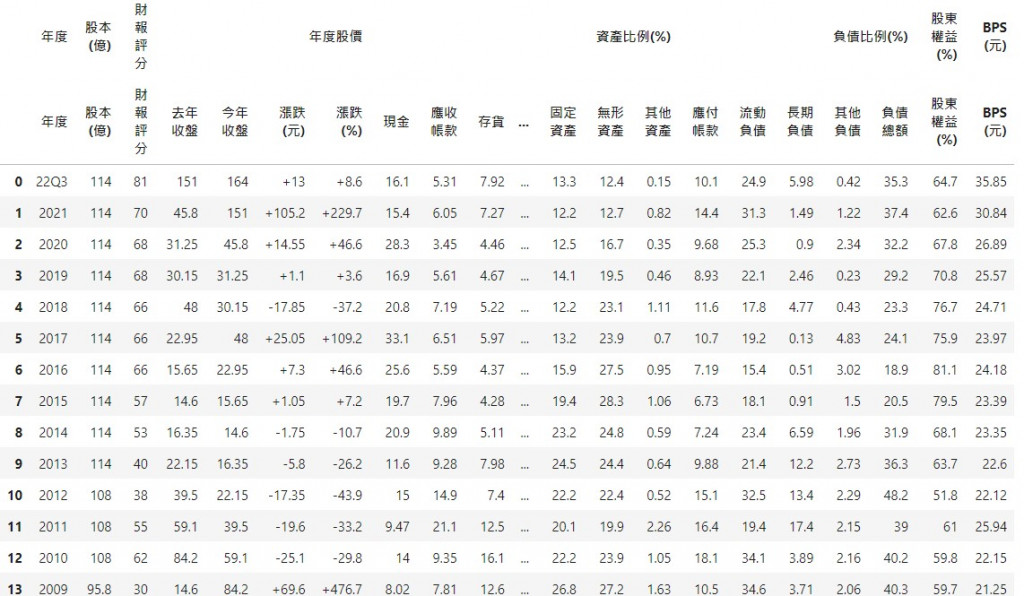
print(bus_table[14])
欲刪掉的欄位如下圖: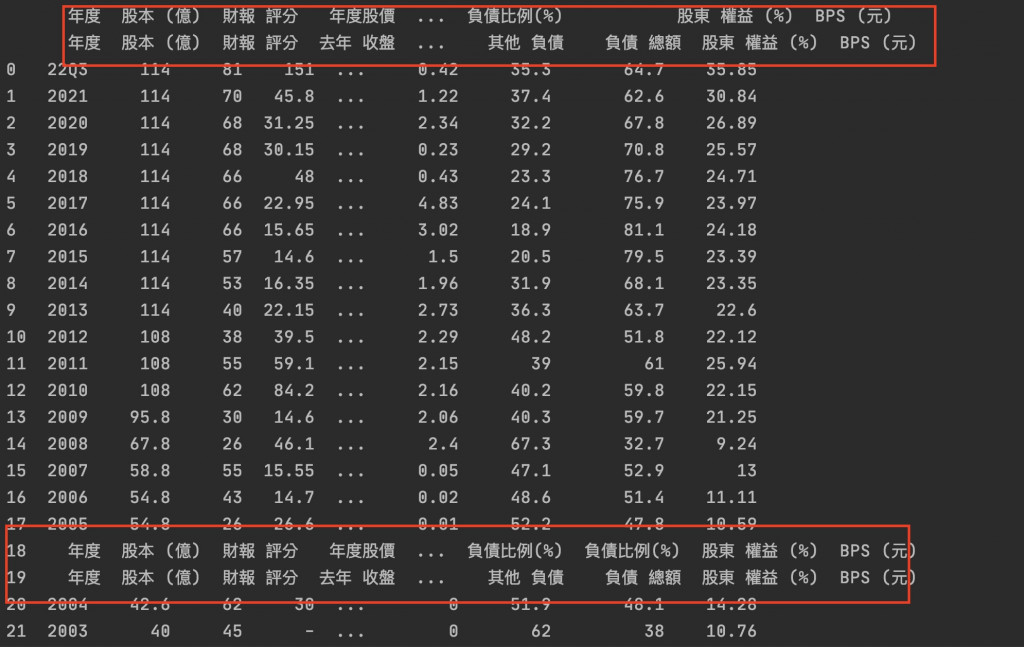
已邀請的邦友 {{ invite_list.length }}/5
import requests
import bs4
import pandas as pd
#目標網站。
url = "https://goodinfo.tw/tw/StockAssetsStatus.asp?STOCK_ID=8069"
#設定headers
headers = {
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Mobile Safari/537.36'
}
res = requests.post(url,headers = headers)
res.encoding = 'utf-8'
temp = res.text
#soup = bs4.BeautifulSoup(res.text,'lxml')
bus_table = pd.read_html(temp)
print(len(bus_table))
df = bus_table[14]
print(len(df))
print(df.columns)
df

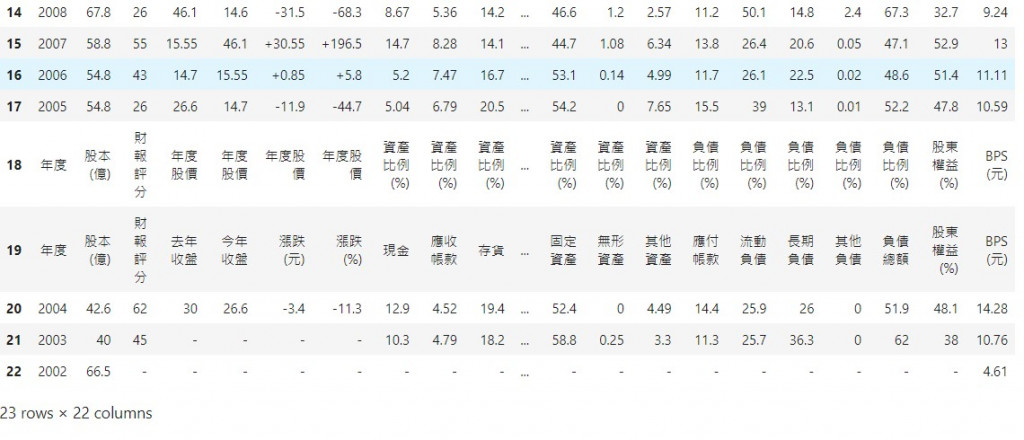
上面資料爬出來後的欄位名稱是MultiIndex
# 剔除「'年度', '年度'」這個欄位的值等於「年度」的所有列。
df = df[df['年度', '年度'] != '年度']
df