如何利用迴圈重複同樣動作,然後再將擷取出的字串做成新的或是放回原本的串列中呢
只會單筆修改,現在有200筆資料,嘗試用迴圈失敗了可以怎麼寫呢?
假設
data ={'id': ['A','B','C'],
'address':['Tapei','Taichung','Kaohsiung'],
'date': ['2022-11-21T11:23:00',
'2022-11-19T12:34.99',
'2022-11-14T11:34:22.3'],
'status': ['completed', 'hold','completed'],
'telephone':['0988123123','09121234234','0987654321'],
'total': [2199,9399,6099]}
data1=pd.DataFrame(data)
date2=data1.loc[:,['id','date','status','total']]
#print(date2['date'][1])
#只需要長度10 顯示成2022-11-19
data3 = (date2['date'][1][:10])
#將字串改成時間
data4 = datetime.strptime(data3, '%Y-%m-%d')
print(data4)
後續需要抓出日期為昨天的資料
時間格式寫了%Y-%m-%d,print(data4) 顯示2022-11-19 00:00:00
抓取時會碰到問題嗎?
主要是想將字串轉成時間方便後續篩選再放回去,如過有更好的方法在麻煩大神們幫幫忙了
不好意思用詞什麼的不太會問,如有說明不清楚地再麻煩指教,謝謝~
已邀請的邦友 {{ invite_list.length }}/5
import pandas as pd
data ={'id': ['A','B','C'],
'address':['Tapei','Taichung','Kaohsiung'],
'date': ['2022-11-21T11:23:00',
'2022-11-19T12:34.99',
'2022-11-14T11:34:22.3'],
'status': ['completed', 'hold','completed'],
'telephone':['0988123123','09121234234','0987654321'],
'total': [2199,9399,6099]}
df = pd.DataFrame(data)
df['date'] = pd.to_datetime(df['date'])
看不太懂你要什麼,不過這樣date那欄就都是datetime了
跟樓上一樣不太確定樓主的需求。
假設最後的需求是日期只留下「年-月-日」,那就繼續往下看:
import pandas as pd
data ={'id': ['A','B','C'],
'address':['Tapei','Taichung','Kaohsiung'],
'date': ['2022-11-21T11:23:00',
'2022-11-19T12:34.99',
'2022-11-14T11:34:22.3'],
'status': ['completed', 'hold','completed'],
'telephone':['0988123123','09121234234','0987654321'],
'total': [2199,9399,6099]}
df = pd.DataFrame(data)
df
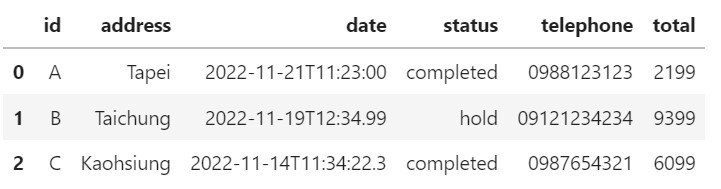
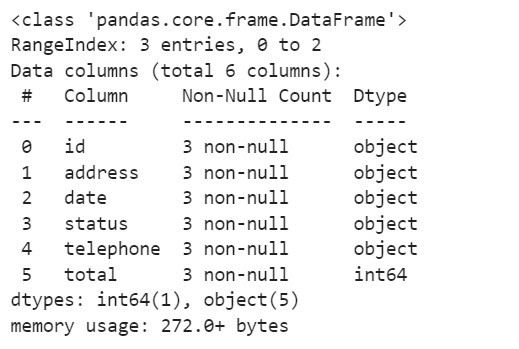
# 先看一下資料的類型
df.info()
df['date']是文字類型,要先處理成datetime類型,然後只取年月日。
df['date'] = pd.to_datetime(df['date'], format='%Y-%m-%d')
df
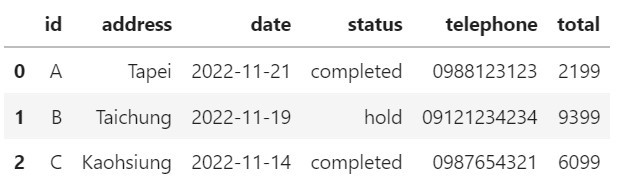
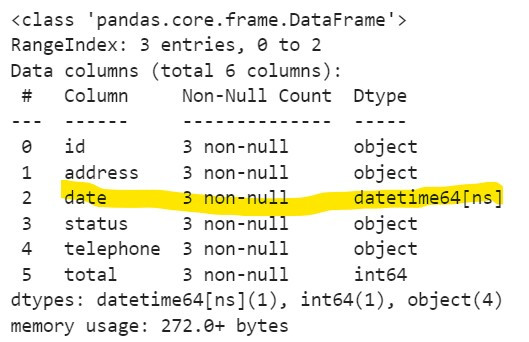
再看一下df['date'],確認一下是datetime類型。
df.info()
謝謝你的解答
照著操做:
import pandas as pd
data ={'id': ['A','B','C'],
'address':['Tapei','Taichung','Kaohsiung'],
'date': ['2022-11-21T11:23:00',
'2022-11-14T11:34:22.3',
'2022-11-19T11:34:21.3'],
'status': ['completed', 'hold','completed'],
'telephone':['0988123123','09121234234',
'0987654321'],
'total': [2199,9399,6099]}
df = pd.DataFrame(data)
df['date'] = pd.to_datetime(df['date'])
df1=df.loc[:,['id','date','status','total']]
df1['date'] = pd.to_datetime(df1['date'], format='%Y-%m-%d')
print(df1)
得到的結果: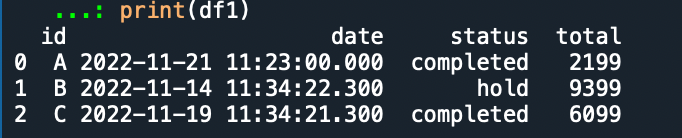
date還是顯示到秒 不知道哪裡錯了
對於篩選來說,後面有沒有到秒其實意義不是很大,datetime物件取出來後你也能輕易地轉換成日期去顯示。不用糾結在這,真的要就多一欄就好。
df['dateSTR'] = df['date'].apply(lambda x: x.strftime("%Y/%m/%d"))
可以看樓上的前輩建議。
如果真的還是想改原來的程式,那就參考下面:
import pandas as pd
data ={'id': ['A','B','C'],
'address':['Tapei','Taichung','Kaohsiung'],
'date': ['2022-11-21T11:23:00',
'2022-11-14T11:34:22.3',
'2022-11-19T11:34:21.3'],
'status': ['completed', 'hold','completed'],
'telephone':['0988123123','09121234234',
'0987654321'],
'total': [2199,9399,6099]}
df = pd.DataFrame(data)
df['date'] = pd.to_datetime(df['date'])
df1=df.loc[:,['id','date','status','total']]
df1['date'] = pd.to_datetime(df1['date']).dt.date
print(df1)
把原先程式的這一行:
df1['date'] = pd.to_datetime(df1['date'], format='%Y-%m-%d')
改成下面這一行應該就行:
df1['date'] = pd.to_datetime(df1['date']).dt.date

