請教各位python先進
小弟在爬goodinfo的股利欄位時,是以一個row代表一個年度,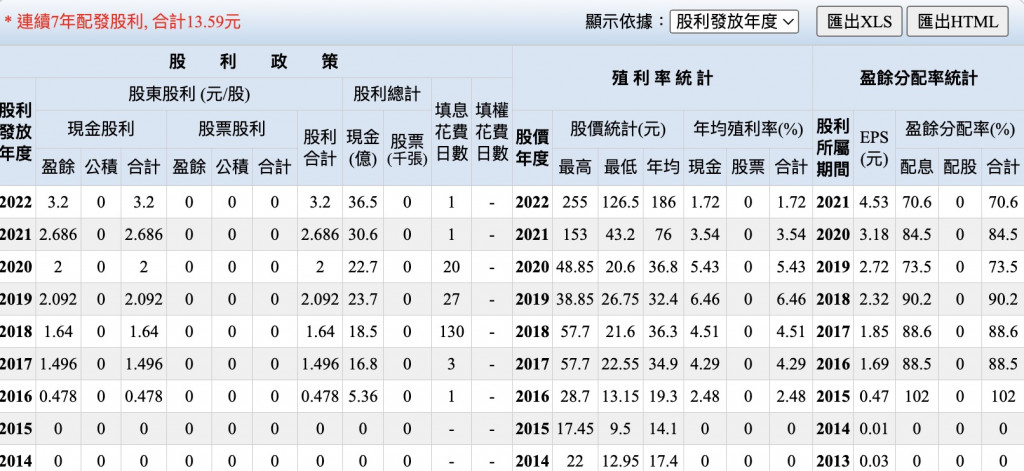
但後來發現goodinfo的股利會有季配股利會有不規則的欄位出現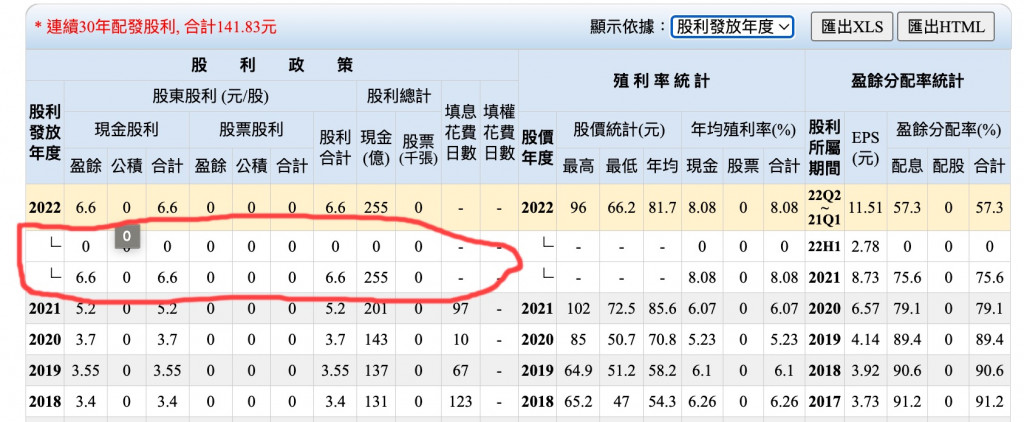
以下是我的程式碼,爬一般欄位沒問題,但爬股利有分季配發時就掛了,請問有沒有好的解法呢?
def yield_func(stock_code,sheet_name):
#目標網站。
url = "https://goodinfo.tw/tw/StockDividendPolicy.asp?STOCK_ID="+stock_code
#設定headers
headers = {
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Mobile Safari/537.36'
}
#使用headers讓網站辨識我們是存在的使用者
res = requests.post(url,headers = headers)
#更改資料的字元編碼
res.encoding = 'utf-8'
temp = res.text
yield_table = pd.read_html(temp)
# print(len(eps_table))
yield_df = yield_table[17]
# print(yield_df.columns)
# #整理表格的標頭
yield_df.columns = yield_df.columns.get_level_values(1)
# judge the number of years
if (len(yield_df)) >= 10:
get_row_num = 8
else:
get_row_num = len(yield_df) - 1
# get the data of select years
yield_df = yield_df.head(get_row_num)
# 將dataframe轉成list
yield_data_list = yield_df.values.tolist()
# 依照年份反排序
yield_data_list.reverse()
# print(yield_data_list)
# 準備寫進google試算表
sheet_test = sheet.worksheet(sheet_name)
letter_list = ["A","B","C", "D", "E", "F", "G", "H", "I", "J", "K"]
# for price
number = 2 # point google sheet column number
for yield_data in yield_data_list:
letter = letter_list[number]
print(yield_data[13])
sheet_test.update(letter + '29', yield_data[0]) # YEAR
sheet_test.update(letter + '31', float(yield_data[13])) # HIGH PRICE 13
sheet_test.update(letter + '32', float(yield_data[15])) # AVERAGE PRICE 15
sheet_test.update(letter + '33', float(yield_data[14])) # LOW PRICE 14
number = number + 1
# for yield
del[yield_data_list[0]] #del first row
number = 2 # point google sheet column number
for yield_data in yield_data_list:
letter = letter_list[number]
sheet_test.update(letter + '30', float(yield_data[7]))
number = number + 1
已邀請的邦友 {{ invite_list.length }}/5
以0050為例:
import pandas as pd
import requests
#目標網站。
url = "https://goodinfo.tw/tw/StockDividendPolicy.asp?STOCK_ID=%22+0050"
#設定headers
headers = {
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Mobile Safari/537.36'
}
#使用headers讓網站辨識我們是存在的使用者
res = requests.post(url,headers = headers)
#更改資料的字元編碼
res.encoding = 'utf-8'
temp = res.text
df = pd.read_html(temp)[17]
print(df.columns)
df

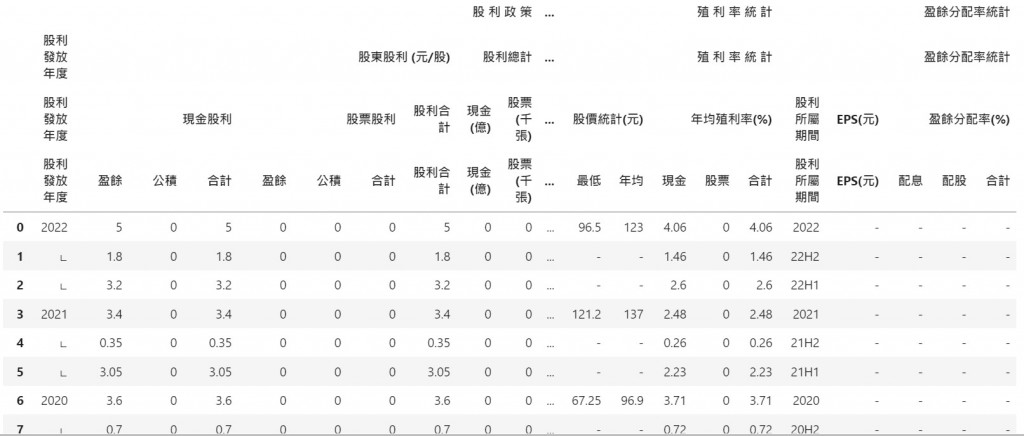
欄位又是MultiIndex。
目標是把年度非數字的欄位去除,年度的欄位名稱是「('股 利 政 策', '股利發放年度', '股利發放年度', '股利發放年度')」
# 第一種方法:
col = ('股 利 政 策', '股利發放年度', '股利發放年度', '股利發放年度')
df[pd.to_numeric(df[col], errors='coerce').notnull()]
# 第二種方法:
col = ('股 利 政 策', '股利發放年度', '股利發放年度', '股利發放年度')
df[df[col].apply(lambda x: x.isnumeric())]
# 第三種方法:
col = ('股 利 政 策', '股利發放年度', '股利發放年度', '股利發放年度')
df[df[col].str.isnumeric()]
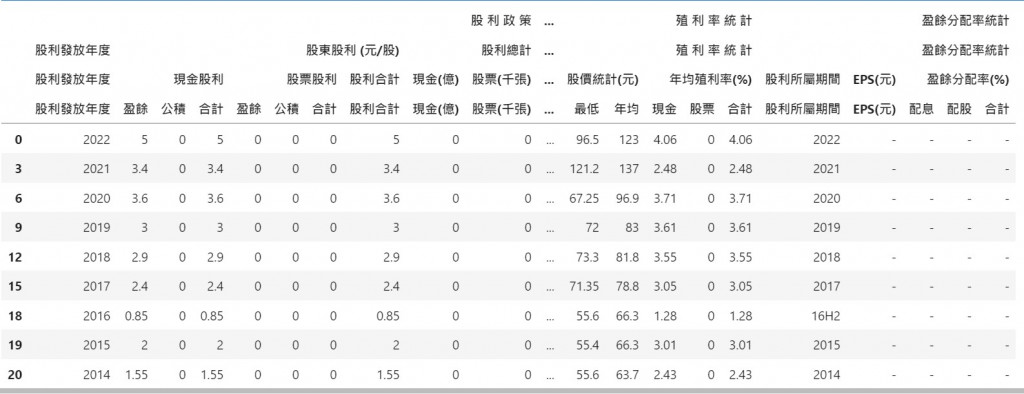
再次謝謝mackuo兄的回覆,有爬過一些pandas的MultiIndex的文章,但還不是很了解,請問mackuo兄有沒有推薦的學習網站?
Pandas MultiIndex的教學大部份都是針對索引的部份,很少講到columns的MultiIndex,但原理應該是一樣的,我也是有需要才去google。Pandas的文件應該是寫最多的。
https://pandas.pydata.org/docs/user_guide/advanced.html
mackuo兄,我試了這三種方法,但還是不行耶
程式碼:
import pandas as pd
import requests
#目標網站。
url = "https://goodinfo.tw/tw/StockDividendPolicy.asp?STOCK_ID=%22+0050"
#設定headers
headers = {
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Mobile Safari/537.36'
}
#使用headers讓網站辨識我們是存在的使用者
res = requests.post(url,headers = headers)
#更改資料的字元編碼
res.encoding = 'utf-8'
temp = res.text
df = pd.read_html(temp)[17]
print(df.columns)
col = ('股 利 政 策', '股利 發放 年度', '股利 發放 年度', '股利 發放 年度')
df[pd.to_numeric(df[col], errors='coerce').notnull()]
# df[df[col].apply(lambda x: x.isnumeric())]
# df[df[col].str.isnumeric()]
print(df)

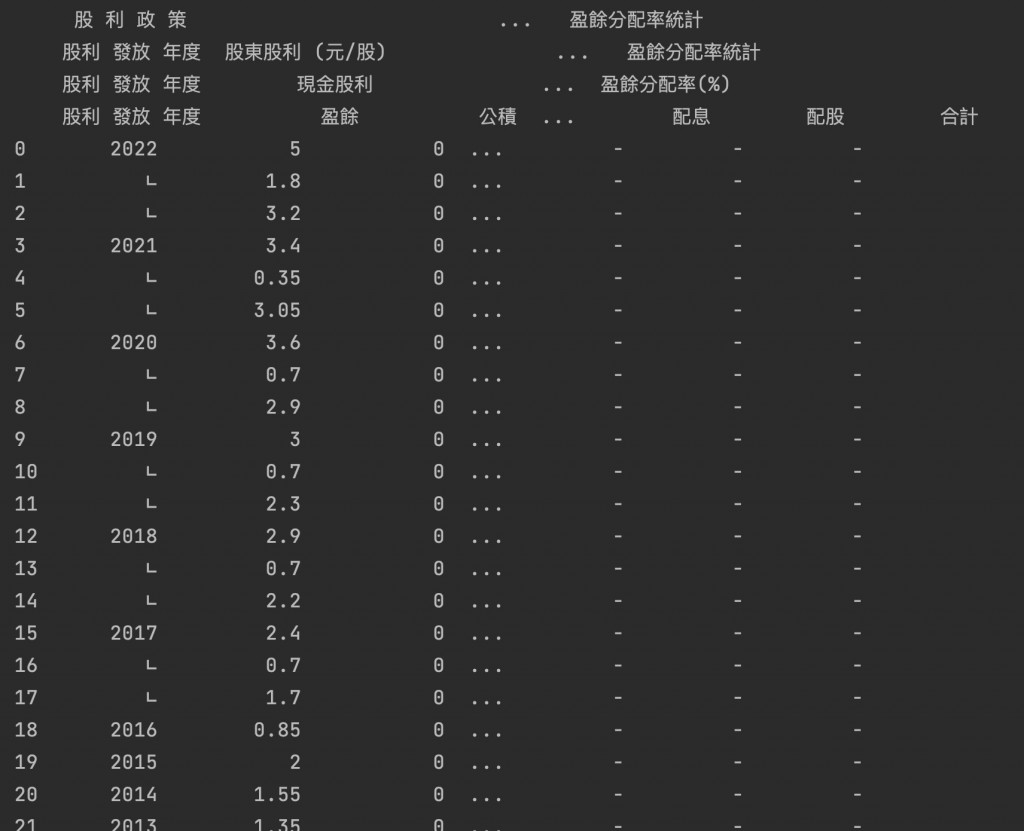
第19行程式要改成存入df。
因為示範的關係,不存入df,
但你確定用第幾種方法後,要存入df。
迷糊的錯誤~~~~~,謝謝mackuo兄耐心的教導和指正,收穫滿滿,感謝
