以下是我Tensorflow 的Object Detection物件辨識
目前都可以正常辨識
但是我也想做灰階圖的測試
想問問有沒有大大知道裡面內容
何處要修訂成程式
能讀取灰階的格式
我看網路上寫讀取灰階圖檔的程式如下img_gray = cv2.imread('image.jpg' , cv2.IMREAD_GRAYSCALE)
請問我該如何把這個修訂到我下面的內容裡?????
#!/usr/bin/env python
# coding: utf-8
#(問題)灰階圖該程式無法讀取,因為之後也要訓練灰階,這個也會干擾後續問題
"""
Object Detection From TF1 Saved Model
=====================================
"""
# %%
# This demo will take you through the steps of running an "out-of-the-box" TensorFlow 1 compatible
# detection model on a collection of images. More specifically, in this example we will be using
# the `Saved Model Format <https://www.tensorflow.org/guide/saved_model>`__ to load the model.
# %%
# Download the test images
# ~~~~~~~~~~~~~~~~~~~~~~~~
# First we will download the images that we will use throughout this tutorial. The code snippet
# shown bellow will download the test images from the `TensorFlow Model Garden <https://github.com/tensorflow/models/tree/master/research/object_detection/test_images>`_
# and save them inside the ``data/images`` folder.
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # Suppress TensorFlow logging (1)
import pathlib
import tensorflow as tf
tf.get_logger().setLevel('ERROR') # Suppress TensorFlow logging (2)
# Enable GPU dynamic memory allocation
gpus = tf.config.experimental.list_physical_devices('GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
def download_images():
base_url = 'https://raw.githubusercontent.com/tensorflow/models/master/research/object_detection/test_images/'
filenames = ['image1.jpg', 'image2.jpg']
image_paths = []
for filename in filenames:
image_path = tf.keras.utils.get_file(fname=filename,
origin=base_url + filename,
untar=False)
image_path = pathlib.Path(image_path)
image_paths.append(str(image_path))
return image_paths
#(問題)E2K_Test_7.jpg是灰階無法讀取
#IMAGE_PATHS = download_images()
IMAGE_PATHS=[]
#myBasePath = r'D:\TensorFlow\workspace\training_demo\images\test\RGB'
#灰階路徑 r'D:\TensorFlow\workspace\training_demo\images\test\GRAY'
myBasePath = r'D:\TensorFlow\workspace\training_demo\images\test\GRAY'
myOutputPath = os.path.join(myBasePath, 'RGBOutput')
#myFileNames = ['C130_Test_1.jpg','C130_test_2.jpg']
myFileNames = ['C130_Test_1.jpg','C130_test_2.jpg']
for i in myFileNames:
IMAGE_PATHS.append(os.path.join(myBasePath, i))
# %%
# Download the model
# ~~~~~~~~~~~~~~~~~~
# The code snippet shown below is used to download the pre-trained object detection model we shall
# use to perform inference. The particular detection algorithm we will use is the
# `SSD MobileNet v2`. More models can be found in the `TensorFlow 1 Detection Model Zoo <https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf1_detection_zoo.md>`_.
# To use a different model you will need the URL name of the specific model. This can be done as
# follows:
#
# 1. Right click on the `Model name` of the model you would like to use;
# 2. Click on `Copy link address` to copy the download link of the model;
# 3. Paste the link in a text editor of your choice. You should observe a link similar to ``download.tensorflow.org/models/object_detection/XXXXXXXXX.tar.gz``;
# 4. Copy the ``XXXXXXXXX`` part of the link and use it to replace the value of the ``MODEL_NAME`` variable in the code shown below;
#
# For example, the download link for the model used below is: ``download.tensorflow.org/models/object_detection/ssd_mobilenet_v2_coco_2018_03_29.tar.gz``
#下載模型的程式
# Download and extract model
def download_model(model_name):
base_url = 'http://download.tensorflow.org/models/object_detection/'
model_file = model_name + '.tar.gz'
model_dir = tf.keras.utils.get_file(fname=model_name,
origin=base_url + model_file,
untar=True)
return str(model_dir)
MODEL_NAME = 'faster_rcnn_resnet101_coco_2018_01_28'
PATH_TO_MODEL_DIR = download_model(MODEL_NAME)
# %%
# Download the labels
# ~~~~~~~~~~~~~~~~~~~
# The coode snippet shown below is used to download the labels file (.pbtxt) which contains a list
# of strings used to add the correct label to each detection (e.g. person). Since the pre-trained
# model we will use has been trained on the COCO dataset, we will need to download the labels file
# corresponding to this dataset, named ``mscoco_label_map.pbtxt``. A full list of the labels files
# included in the TensorFlow Models Garden can be found `here <https://github.com/tensorflow/models/tree/master/research/object_detection/data>`__.
'''
#下載 labels程式
# Download labels file
def download_labels(filename):
base_url = 'https://raw.githubusercontent.com/tensorflow/models/master/research/object_detection/data/'
label_dir = tf.keras.utils.get_file(fname=filename,
origin=base_url + filename,
untar=False)
label_dir = pathlib.Path(label_dir)
return str(label_dir)
LABEL_FILENAME = 'mscoco_label_map.pbtxt'
PATH_TO_LABELS = download_labels(LABEL_FILENAME)
'''
PATH_TO_LABELS = r'D:\TensorFlow\workspace\training_demo\annotations\label_map.pbtxt'
# %%
# Load the model
# ~~~~~~~~~~~~~~
# Next we load the downloaded model
import time
from object_detection.utils import label_map_util
from object_detection.utils import visualization_utils as viz_utils
#PATH_TO_SAVED_MODEL = PATH_TO_MODEL_DIR + "/saved_model"
#訓練完的位置 r'D:\TensorFlow\workspace\training_demo\trained-inference-graphs\output_inference_graph_faster_rcnn_resnet50_RGB\saved_model\saved_model.pb'
#D:\TensorFlow\workspace\training_demo\trained-inference-graphs\output_inference_graph_faster_rcnn_resnet101_RGB.pb\saved_model
#PATH_TO_SAVED_MODEL = r'D:\TensorFlow\workspace\training_demo\trained-inference-graphs\output_inference_graph_faster_rcnn_resnet101_RGB.pb' + "/saved_model"
PATH_TO_SAVED_MODEL =r'D:\TensorFlow\workspace\training_demo\trained-inference-graphs\GRAY_faster_rcnn_resnet101_inference.pb' + "/saved_model"
print('Loading model...', end='')
start_time = time.time()
# Load saved model and build the detection function
model = tf.saved_model.load(PATH_TO_SAVED_MODEL)
detect_fn = model.signatures['serving_default']
end_time = time.time()
elapsed_time = end_time - start_time
print('Done! Took {} seconds'.format(elapsed_time))
# %%
# Load label map data (for plotting)
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# Label maps correspond index numbers to category names, so that when our convolution network
# predicts `5`, we know that this corresponds to `airplane`. Here we use internal utility
# functions, but anything that returns a dictionary mapping integers to appropriate string labels
# would be fine.
category_index = label_map_util.create_category_index_from_labelmap(PATH_TO_LABELS,
use_display_name=True)
# %%
# Putting everything together
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~
# The code shown below loads an image, runs it through the detection model and visualizes the
# detection results, including the keypoints.
#
# Note that this will take a long time (several minutes) the first time you run this code due to
# tf.function's trace-compilation --- on subsequent runs (e.g. on new images), things will be
# faster.
#
# Here are some simple things to try out if you are curious:
#
# * Modify some of the input images and see if detection still works. Some simple things to try out here (just uncomment the relevant portions of code) include flipping the image horizontally, or converting to grayscale (note that we still expect the input image to have 3 channels).
# * Print out `detections['detection_boxes']` and try to match the box locations to the boxes in the image. Notice that coordinates are given in normalized form (i.e., in the interval [0, 1]).
# * Set ``min_score_thresh`` to other values (between 0 and 1) to allow more detections in or to filter out more detections.
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore') # Suppress Matplotlib warnings
def load_image_into_numpy_array(path):
"""Load an image from file into a numpy array.
Puts image into numpy array to feed into tensorflow graph.
Note that by convention we put it into a numpy array with shape
(height, width, channels), where channels=3 for RGB.
Args:
path: the file path to the image
Returns:
uint8 numpy array with shape (img_height, img_width, 3)
"""
return np.array(Image.open(path))
for image_path in IMAGE_PATHS:
print('Running inference for {}... '.format(image_path), end='')
image_np = load_image_into_numpy_array(image_path)
# Things to try:
# Flip horizontally
# image_np = np.fliplr(image_np).copy()
# Convert image to grayscale
# image_np = np.tile(
# np.mean(image_np, 2, keepdims=True), (1, 1, 3)).astype(np.uint8)
# The input needs to be a tensor, convert it using `tf.convert_to_tensor`.
input_tensor = tf.convert_to_tensor(image_np)
# The model expects a batch of images, so add an axis with `tf.newaxis`.
input_tensor = input_tensor[tf.newaxis, ...]
detections = detect_fn(input_tensor)
# All outputs are batches tensors.
# Convert to numpy arrays, and take index [0] to remove the batch dimension.
# We're only interested in the first num_detections.
num_detections = int(detections.pop('num_detections'))
detections = {key: value[0, :num_detections].numpy()
for key, value in detections.items()}
detections['num_detections'] = num_detections
# detection_classes should be ints.
detections['detection_classes'] = detections['detection_classes'].astype(np.int64)
image_np_with_detections = image_np.copy()
viz_utils.visualize_boxes_and_labels_on_image_array(
image_np_with_detections,
detections['detection_boxes'],
detections['detection_classes'],
detections['detection_scores'],
category_index,
use_normalized_coordinates=True,
max_boxes_to_draw=200,
min_score_thresh=.30,
agnostic_mode=False)
plt.figure() ## 建立圖形(figure);
plt.imshow(image_np_with_detections) ## 將資料顯示為影像;
plt.savefig(f'{image_path}.gray101_1.png') ## 多這行而已: 將圖形存入檔案;
print('Done')
plt.show()
# sphinx_gallery_thumbnail_number = 2
以上程式碼改成灰階資料後,執行程式後得到以下問題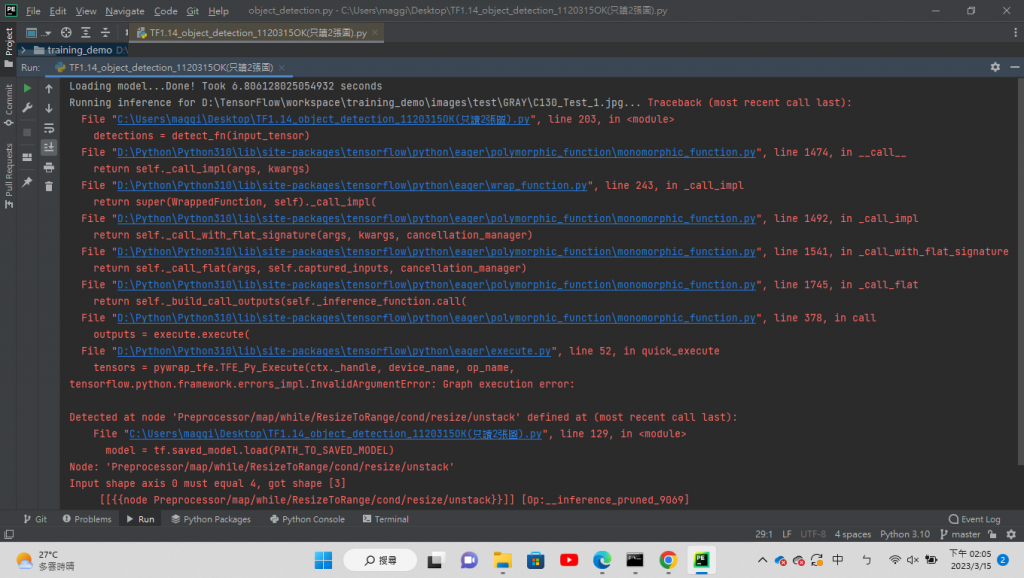
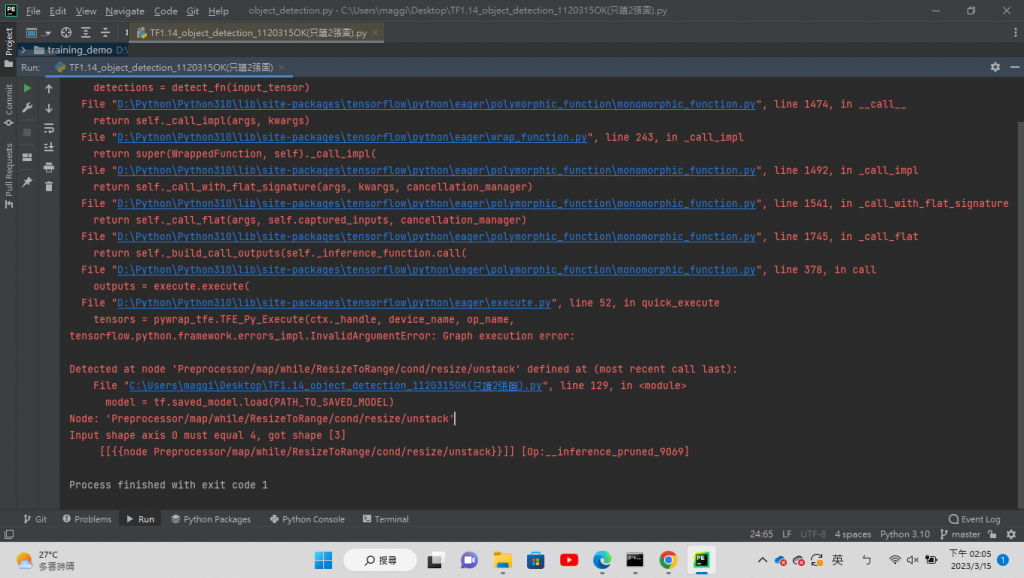
目前狀況就是
我已經把所有圖片轉成灰階了
也要透過Object Detection物件辨識程式去辨識
但問題出現 無法讀灰階圖
請有大大知道如何修改嗎
已邀請的邦友 {{ invite_list.length }}/5
看過 froce大 在問題討論給的資料後,
我建議把你的程式碼的 Line181:
return np.array(Image.open(path))
改為這個試試:
return np.array(Image.open(path).convert("RGB"))
這是利用 Pillow (PIL Fork) 的 PIL.Image.Image.convert() 進行影像物件的模式轉換功能, 嘗試將各種模式轉為 "RGB"。
( 煩死了~ 通通都轉 "RGB" 啦! )
P.s. 因為沒做初始模式的檢查,就算影像物件的初始模式是 "RGB",也會呼叫 Image.convert(); 至於 Image.convert() 內有沒模式檢查我就懶得查了~
另, 因為有資料轉換, 把非目標類型(彩色/灰階)的資料丟入處理, 一定會在辨識過程或結果上有所影響, 這點得注意一下。
另 + 另, 就像 froce大 所言, 你 Coding 基礎不夠, 沒 同學/同事 負責 Coding 等部分,根本困難模式啊。
( 這只是我的感嘆, 沒想了解你的背景情境, 不用回應我這句~ )

 iThome鐵人賽
iThome鐵人賽