我正在了解bioGPT該如何使用,但是有一些問題想請教
bioGPT-文章:https://academic.oup.com/bib/article/23/6/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9&login=false
bioGPT-github:https://github.com/microsoft/BioGPT
論文中有提到三個Downstream Tasks
1.relation extraction
2.question answering
3.document classification
而這些任務似乎需要用對應的model去對pre-trained BioGPT做fine-tune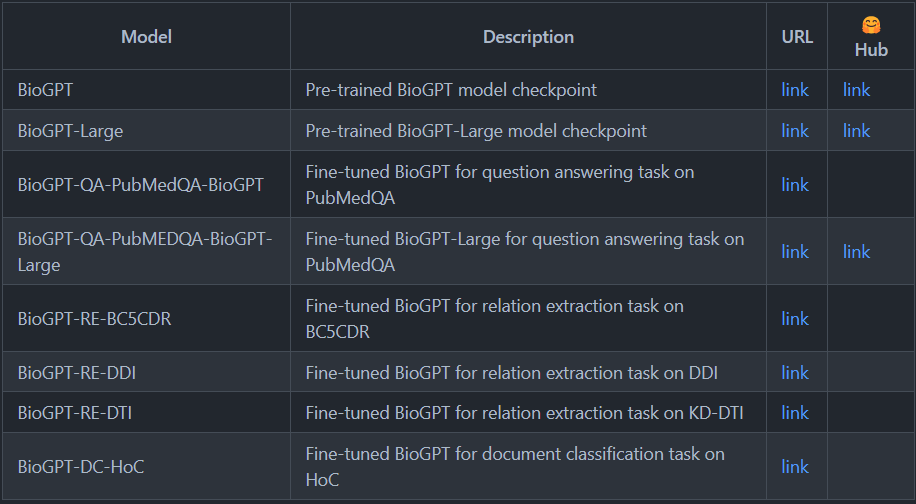
想問是否有人做過類似的事情,例如fine-tune過其它模型(例如ChatGPT或BERT),可以大概教我一下要怎麼做fine-tune?
bioGPT上寫的 "Download them and extract them to the checkpoints folder of this project." ,有點不太明白它的意思
謝謝
已邀請的邦友 {{ invite_list.length }}/5
『Download them and extract them to the checkpoints folder of this project.』是指將作者訓練好的模型下載下來並解壓縮,各種模型檔案在上面的表格,使用方法如下:
mkdir checkpoints
cd checkpoints
wget https://msramllasc.blob.core.windows.net/modelrelease/BioGPT/checkpoints/Pre-trained-BioGPT.tgz
tar -zxvf Pre-trained-BioGPT.tgz
import torch
from fairseq.models.transformer_lm import TransformerLanguageModel
m = TransformerLanguageModel.from_pretrained(
"checkpoints/Pre-trained-BioGPT",
"checkpoint.pt",
"data",
tokenizer='moses',
bpe='fastbpe',
bpe_codes="data/bpecodes",
min_len=100,
max_len_b=1024)
m.cuda()
src_tokens = m.encode("COVID-19 is")
generate = m.generate([src_tokens], beam=5)[0]
output = m.decode(generate[0]["tokens"])
print(output)
簡單使用與微調、ChatGPT無關。
有些套件要從source code建置,使用Linux會比較順。
