不好意思想請教各位大大一下我今天是想要截圖後去辨識東西,然後辨識到物品後產生相關連結到我的終端機下方,但現在是有辨識到物品,但沒跑出連結而出現這個錯誤TypeError: list indices must be integers or slices, not tuple
不知道是哪部分設錯了,再麻煩各位大大解惑一下。
辨識CODE: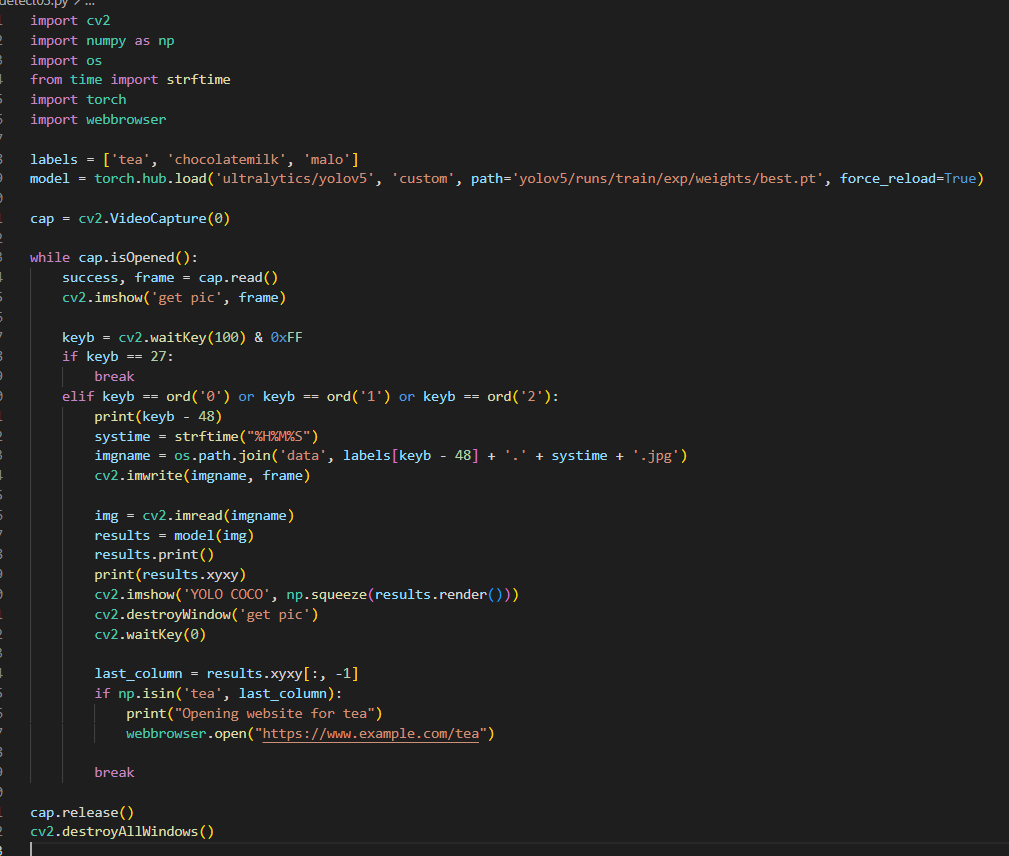
成功辨識到物品: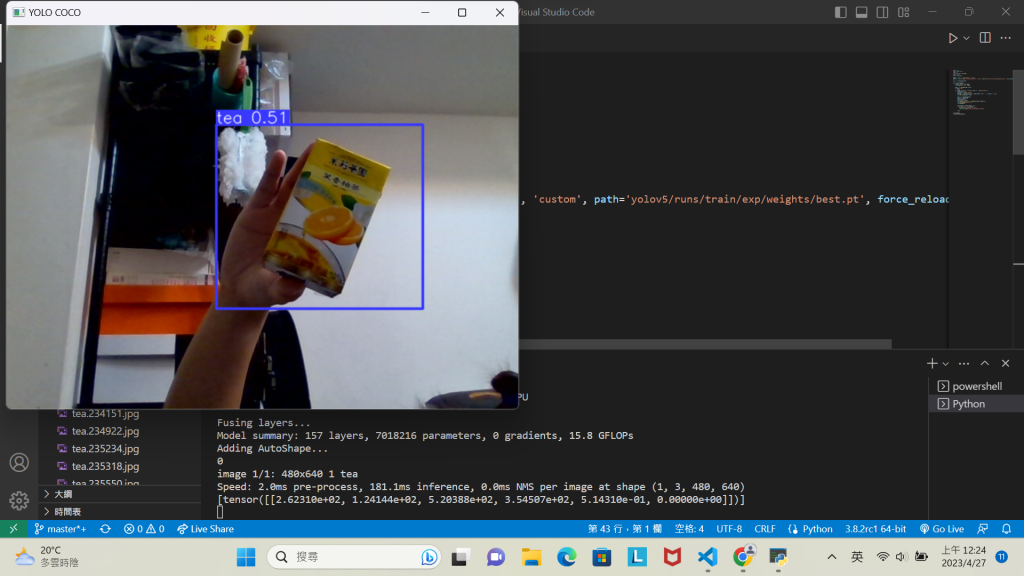
產生的錯誤:
已邀請的邦友 {{ invite_list.length }}/5
這個錯誤訊息代表的是你的list裡面的indices參數只吃integers或slices,而不接受tuple參數
所以我想應該修改成last_column = results.xyxy[-1]就可以了吧(錯誤答案)
更正:從xyxy取出names[0]資訊
pred_name = results.xyxy.names[0] # tea
我從PyTorch官網找到的範例程式碼如下:
LOAD FROM PYTORCH HUB
import torch
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True)
# Images
imgs = ['https://ultralytics.com/images/zidane.jpg'] # batch of images
# Inference
results = model(imgs)
# Results
results.print()
results.save() # or .show()
results.xyxy[0] # img1 predictions (tensor)
results.pandas().xyxy[0] # img1 predictions (pandas)
# xmin ymin xmax ymax confidence class name
# 0 749.50 43.50 1148.0 704.5 0.874023 0 person
# 1 433.50 433.50 517.5 714.5 0.687988 27 tie
# 2 114.75 195.75 1095.0 708.0 0.624512 0 person
# 3 986.00 304.00 1028.0 420.0 0.286865 27 tie
# Get the names of the classes
class_names = results.names
# Get the index 0 row name
row_name = class_names[0]
print(row_name) # Output: person
你的這個錯誤:
是因為 results.xyxy 的類別是 list , 不是 numpy.array, 沒有 [:,-1] 這種 索引 (indexing) 語法。
( 請善用 type() 取得物件類別資訊。 )
辨識結果的名稱集合可從 results.pandas().xyxy[0]['name'].values (<class 'numpy.ndarray'>) 取得, 例如:
## 顯示 'tea' 是否在辨識結果的名稱列表內;
print('tea' in results.pandas().xyxy[0]['name'].values)
( 你的程式碼中, torch.hub.load() 給的 model() 具批次處理功能。 因為你只辨識一張圖片, 所以只需檢查一個辨識結果 xyxy[0] 的內容。 )
請善用 程式碼與語法高亮標記 - iT邦幫忙 的 Markdown ;
不然, 至少, 編輯區工具列, 有個 新增程式碼 (Ctrl-Alt-C) 能用。
( 程式碼區塊 亦可用以存放各種文字資料, 以方便他人閱覽。 )
iThelp-Markdown 的語法高亮之自動識別時常錯判, 建議用下面方式(py)指定語言:
```py
print('hello, world')
```
