請教各位大神,
我是爬蟲菜鳥
這個問題已經困擾我好久....QQ
我目前因為想做電影相關的研究 想爬 台灣文化內容策進院文章清單的標題及內文,
因為網頁是動態網頁所以用了scrapy + selenium套件,
不囉唆先上code,
import scrapy
from scrapy_selenium import SeleniumRequest
from scrapy_splash import SplashRequest
import chromedriver_binary
import time
class TaiccaSpider(scrapy.Spider):
name = "TAICCA"
allowed_domains = ["research.taicca.tw"]
start_urls = ['https://research.taicca.tw/']
def start_requests(self):
url = 'https://research.taicca.tw/search/'
yield SeleniumRequest(url=url, callback=self.parse)
def parse(self,response):
articles = response.xpath('//table[@class="table table-sm table-borderless"]//tbody//tr')
time.sleep(5)
for article in articles:
#文章標題
title = article.xpath('.//td[4][@class="title"]//a[@class="link"]/text()').get()
#文章連結
link = article.xpath('.//td[4]//a[@class="link"]/@href').get()
print("Title:", title)
print("Link:", link)
yield response.follow(url=link, callback=self.parse_page, meta = {'title':title})
def parse_page(self,response):
title = response.request.meta['title']
articles= response.xpath('//div[@class="ql-editor"]//div')
time.sleep(5)
for article in articles:
#文章摘要
lead=article.xpath('.//ul/li/strong/text()').getall()
#文章內文
paragraph = article.xpath('.//p/text()').getall()
print(lead)
print(paragraph)
yield{
'title' : title,
'lead': lead,
'paragraph' : paragraph
}
執行爬蟲時,
Webdriver有正常運行,
爬了標題頁都沒問題,
且文章連結的部分也都有進一步crawl 且應該是有正確連到網頁(http 200),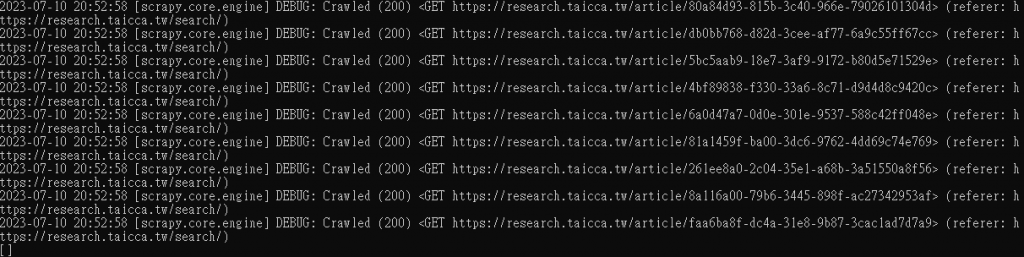
但要爬取內層網頁時(def parse_page)部分就爬不出來...
結果是空值QQ
(先撇除每篇文章的摘要標籤不太相同的因素,有些文章的摘要html標籤是ol 有些則是ul)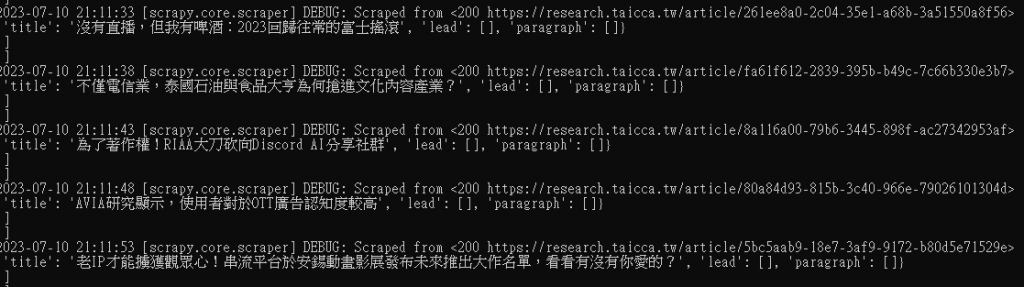
原本想說是不是xpath路徑寫錯呢?
但有試著針對其中一篇文章用Selenium的find_elements()來爬,
是有爬出結果的...
但透過上面的方式外層標題及內層網頁一起爬,
就只爬得出標題的部分,
想請教各位大神是否程式碼有寫錯呢,
或是哪裡我有誤解,
麻煩各位大大指點迷津!!!!
(執行環境 window10 python 3.10)
已邀請的邦友 {{ invite_list.length }}/5
