請問各位大神。小弟之前用以下的程式可以抓到goodinfo的表格,但是現在卻抓不到了;請問有人知道應該如何修改嗎?感恩!
import requests
import pandas as pd
url = 'https://goodinfo.tw/tw/StockFinDetail.asp?RPT_CAT=XX_M_YEAR&STOCK_ID=2330'
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"}
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
dfs = pd.read_html(response.text)
seventeenth_table = dfs[16]
已邀請的邦友 {{ invite_list.length }}/5
如果你查看 response.text 的結果
你會發現網頁根本還沒有載入完成,所以你會需要用其他方法
因為 requests 沒辦法執行 JavaScript 等
給你個 Selenium 參考 (Selenium安裝可能比較麻煩,要查一下driver如何安裝)
from selenium import webdriver
import pandas as pd
url = 'https://goodinfo.tw/tw/StockFinDetail.asp?RPT_CAT=XX_M_YEAR&STOCK_ID=2330'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"}
browser = webdriver.Firefox()
browser.get(url)
source_code = browser.page_source
browser.quit()
dfs = pd.read_html(source_code)
seventeenth_table = dfs[16]
print(seventeenth_table)
這邊是我測試跑完的結果,看起來是沒問題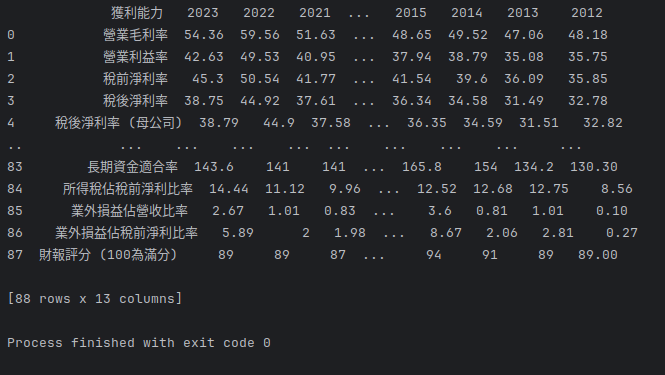 ](_)
](_)
