我們現在面對表格式資料(Tabular data),Excel 試算表,JSON 或者網頁資料時有了相當程度的自信,透過 pandas、requests 與 BeautifulSoup 套件我們可以輕鬆地將不同格式資料載入 Python 的工作環境中。如果你對於將資料載入 Python 還不太清楚,我推薦你閱讀前兩天的內容 [第 15 天] 載入資料與 [第 16 天] 網頁解析。
載入資料之後,接踵而來的就是資料整理(Data manipulation)的差事,或稱資料改寫(Data munging),抑或是一個比較潮的詞彙:資料角力(Data wrangling)。資料角力的目的是為了視覺化或者機器學習模型需求,必須將資料整理成合乎需求的格式。
Yet far too much handcrafted work — what data scientists call “data wrangling,” “data munging” and “data janitor work” — is still required. Data scientists, according to interviews and expert estimates, spend from 50 percent to 80 percent of their time mired in this more mundane labor of collecting and preparing unruly digital data, before it can be explored for useful nuggets.
For Big-Data Scientists, ‘Janitor Work’ Is Key Hurdle to Insights
我們討論幾個常用技巧,然後使用 Python 與 R 語言練習。
類似資料庫表格的 join。
我們使用 pandas 套件的 merge() 方法。
import pandas as pd
name = ["蒙其·D·魯夫", "羅羅亞·索隆", "娜美", "騙人布", "賓什莫克·香吉士", "多尼多尼·喬巴", "妮可·羅賓", "佛朗基", "布魯克"]
occupation = ["船長", "劍士", "航海士", "狙擊手", "廚師", "醫生", "考古學家", "船匠", "音樂家"]
# 建立 dict
straw_hat_dict = {"name": name,
"occupation": occupation
}
# 建立第一個 data frame
straw_hat_df = pd.DataFrame(straw_hat_dict)
name = ["蒙其·D·魯夫", "多尼多尼·喬巴", "妮可·羅賓", "布魯克"]
devil_fruit = ["橡膠果實", "人人果實", "花花果實", "黃泉果實"]
# 建立 dict
devil_fruit_dict = {"name": name,
"devil_fruit": devil_fruit
}
# 建立第二個 data frame
devil_fruit_df = pd.DataFrame(devil_fruit_dict)
# 連接
straw_hat_merged = pd.merge(straw_hat_df, devil_fruit_df)
straw_hat_merged

pandas 套件的 merge() 方法預設是inner join,如果我們希望使用不同的合併方式,我們可以在 how = 參數指定為 left、right 或 outer。
import pandas as pd
name = ["蒙其·D·魯夫", "羅羅亞·索隆", "娜美", "騙人布", "賓什莫克·香吉士", "多尼多尼·喬巴", "妮可·羅賓", "佛朗基", "布魯克"]
occupation = ["船長", "劍士", "航海士", "狙擊手", "廚師", "醫生", "考古學家", "船匠", "音樂家"]
# 建立 dict
straw_hat_dict = {"name": name,
"occupation": occupation
}
# 建立第一個 data frame
straw_hat_df = pd.DataFrame(straw_hat_dict)
name = ["蒙其·D·魯夫", "多尼多尼·喬巴", "妮可·羅賓", "布魯克"]
devil_fruit = ["橡膠果實", "人人果實", "花花果實", "黃泉果實"]
# 建立 dict
devil_fruit_dict = {"name": name,
"devil_fruit": devil_fruit
}
# 建立第二個 data frame
devil_fruit_df = pd.DataFrame(devil_fruit_dict)
# 連接
straw_hat_merged = pd.merge(straw_hat_df, devil_fruit_df, how = "left")
straw_hat_merged

我們使用 merge() 函數。
name <- c("蒙其·D·魯夫", "羅羅亞·索隆", "娜美", "騙人布", "賓什莫克·香吉士", "多尼多尼·喬巴", "妮可·羅賓", "佛朗基", "布魯克")
occupation <- c("船長", "劍士", "航海士", "狙擊手", "廚師", "醫生", "考古學家", "船匠", "音樂家")
# 建立第一個 data frame
straw_hat_df = data.frame(name, occupation)
name <- c("蒙其·D·魯夫", "多尼多尼·喬巴", "妮可·羅賓", "布魯克")
devil_fruit <- c("橡膠果實", "人人果實", "花花果實", "黃泉果實")
# 建立第二個 data frame
devil_fruit_df = data.frame(name, devil_fruit)
# 連接
straw_hat_merged = merge(straw_hat_df, devil_fruit_df)
View(straw_hat_merged)

R 語言的 merge() 函數預設也是inner join,如果我們希望使用不同的合併方式,我們可以在 all.x = 與 all.y = 參數指定。
name <- c("蒙其·D·魯夫", "羅羅亞·索隆", "娜美", "騙人布", "賓什莫克·香吉士", "多尼多尼·喬巴", "妮可·羅賓", "佛朗基", "布魯克")
occupation <- c("船長", "劍士", "航海士", "狙擊手", "廚師", "醫生", "考古學家", "船匠", "音樂家")
# 建立第一個 data frame
straw_hat_df = data.frame(name, occupation)
name <- c("蒙其·D·魯夫", "多尼多尼·喬巴", "妮可·羅賓", "布魯克")
devil_fruit <- c("橡膠果實", "人人果實", "花花果實", "黃泉果實")
# 建立第二個 data frame
devil_fruit_df = data.frame(name, devil_fruit)
# 連接
straw_hat_merged = merge(straw_hat_df, devil_fruit_df, all.x = TRUE)
View(straw_hat_merged)

新增一個觀測值或一個變數欄位。
我們使用 pandas 套件的 concat() 方法。在 axis = 的參數指定 axis = 1 即可新增一個變數欄位。
import pandas as pd
name = ["蒙其·D·魯夫", "羅羅亞·索隆", "娜美", "騙人布", "賓什莫克·香吉士", "多尼多尼·喬巴", "妮可·羅賓", "佛朗基", "布魯克"]
occupation = ["船長", "劍士", "航海士", "狙擊手", "廚師", "醫生", "考古學家", "船匠", "音樂家"]
# 建立 dict
straw_hat_dict = {"name": name,
"occupation": occupation
}
# 建立第一個 data frame
straw_hat_df = pd.DataFrame(straw_hat_dict)
name = ["娜菲鲁塔利·薇薇"]
occupation = ["阿拉巴斯坦王國公主"]
princess_vivi_dict = {"name": name,
"occupation": occupation
}
# 建立第二個 data frame
princess_vivi_df = pd.DataFrame(princess_vivi_dict, index = [9])
# 新增一個觀測值
straw_hat_df_w_vivi = pd.concat([straw_hat_df, princess_vivi_df])
straw_hat_df_w_vivi
age = [19, 21, 20, 19, 21, 17, 30, 36, 90, 18]
age_dict = {"age": age
}
# 建立第三個 data frame
age_df = pd.DataFrame(age_dict)
# 新增一個變數欄位
straw_hat_df_w_vivi_age = pd.concat([straw_hat_df_w_vivi, age_df], axis = 1)
straw_hat_df_w_vivi_age


我們使用 rbind() 函數新增一個觀測值,使用 cbind() 函數新增一個變數欄位。
name <- c("蒙其·D·魯夫", "羅羅亞·索隆", "娜美", "騙人布", "賓什莫克·香吉士", "多尼多尼·喬巴", "妮可·羅賓", "佛朗基", "布魯克")
occupation <- c("船長", "劍士", "航海士", "狙擊手", "廚師", "醫生", "考古學家", "船匠", "音樂家")
# 建立第一個 data frame
straw_hat_df = data.frame(name, occupation)
straw_hat_df$name <- as.character(straw_hat_df$name)
straw_hat_df$occupation <- as.character(straw_hat_df$occupation)
# 新增一個觀測值
princess_vivi <- c("娜菲鲁塔利·薇薇", "阿拉巴斯坦王國公主")
straw_hat_df_w_vivi <- rbind(straw_hat_df, princess_vivi)
View(straw_hat_df_w_vivi)
# 新增一個變數欄位
age <- c(19, 21, 20, 19, 21, 17, 30, 36, 90, 18)
straw_hat_df_w_vivi_age <- cbind(straw_hat_df_w_vivi, age)
View(straw_hat_df_w_vivi_age)


轉置(Transpose)指的是寬表格(Wide table)與長表格(Long table)之間的互換。
我們使用 data frame 物件的 stack() 將寬表格轉置為長表格,使用 unstack() 方法將長表格轉置回寬表格。
import pandas as pd
name = ["蒙其·D·魯夫", "羅羅亞·索隆", "娜美", "騙人布", "賓什莫克·香吉士", "多尼多尼·喬巴", "妮可·羅賓", "佛朗基", "布魯克"]
age = [19, 21, 20, 19, 21, 17, 30, 36, 90]
height = [174, 181, 170, 176, 180, 90, 188, 240, 277]
# 建立 dict
straw_hat_dict = {
"name": name,
"age": age,
"height": height
}
# 建立一個寬表格
straw_hat_df_wide = pd.DataFrame(straw_hat_dict)
# 轉換為長表格
straw_hat_df_long = straw_hat_df_wide.stack()
straw_hat_df_long
# 轉換回寬表格
straw_hat_df_wide = straw_hat_df_long.unstack()
straw_hat_df_wide


我們使用 tidyr 套件的 gather() 函數將寬表格轉置為長表格,使用 spread() 函數將長表格轉置回寬表格。
library(tidyr)
name <- c("蒙其·D·魯夫", "羅羅亞·索隆", "娜美", "騙人布", "賓什莫克·香吉士", "多尼多尼·喬巴", "妮可·羅賓", "佛朗基", "布魯克")
age <- c(19, 21, 20, 19, 21, 17, 30, 36, 90)
height <- c(174, 181, 170, 176, 180, 90, 188, 240, 277)
# 建立一個寬表格
straw_hat_df_wide <- data.frame(name, age, height)
# 轉換為長表格
straw_hat_df_long <- gather(straw_hat_df_wide, key = item, value = value, age, height)
View(straw_hat_df_long)
# 轉換回寬表格
straw_hat_df_wide <- spread(straw_hat_df_long, key = item, value = value)
View(straw_hat_df_wide)


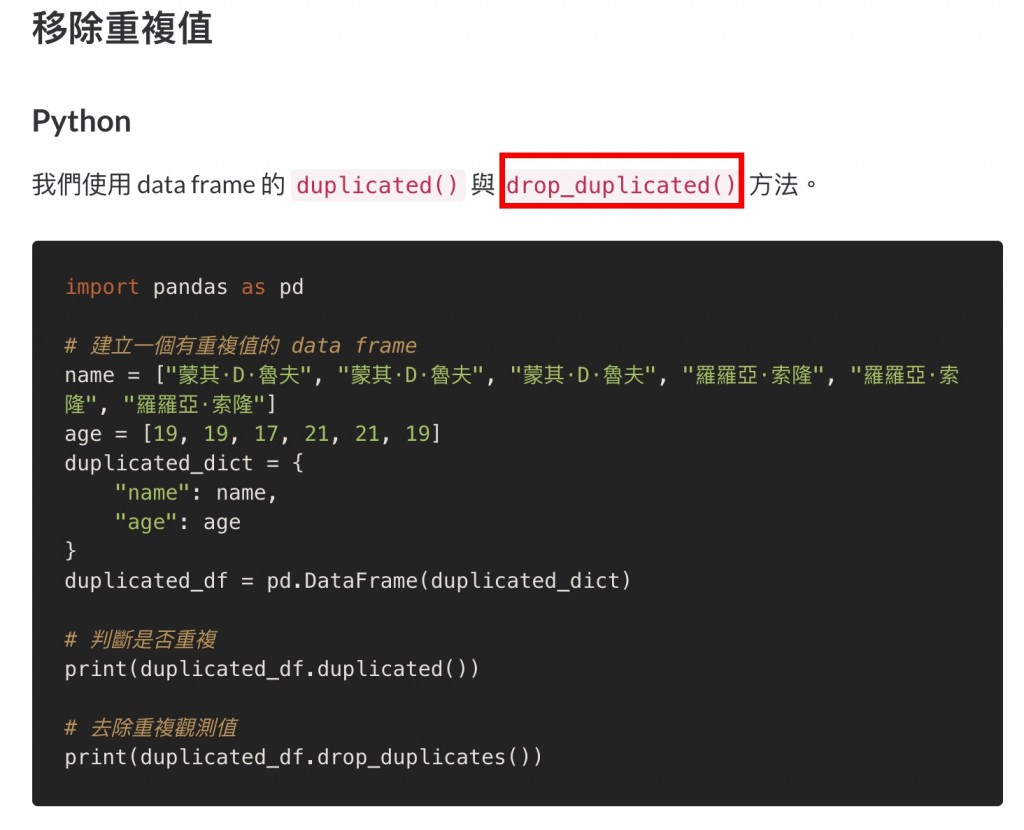
我們使用 data frame 的 duplicated() 與 drop_duplicated() 方法。
import pandas as pd
# 建立一個有重複值的 data frame
name = ["蒙其·D·魯夫", "蒙其·D·魯夫", "蒙其·D·魯夫", "羅羅亞·索隆", "羅羅亞·索隆", "羅羅亞·索隆"]
age = [19, 19, 17, 21, 21, 19]
duplicated_dict = {
"name": name,
"age": age
}
duplicated_df = pd.DataFrame(duplicated_dict)
# 判斷是否重複
print(duplicated_df.duplicated())
# 去除重複觀測值
print(duplicated_df.drop_duplicates())

我們使用 duplicated() 函數。
# 建立一個有重複值的 data frame
name = c("蒙其·D·魯夫", "蒙其·D·魯夫", "蒙其·D·魯夫", "羅羅亞·索隆", "羅羅亞·索隆", "羅羅亞·索隆")
age <- c(19, 19, 17, 21, 21, 19)
duplicated_df <- data.frame(name, age)
is_duplicates <- duplicated(duplicated_df)
duplicated_df[!is_duplicates, ]

數值分箱(Binning)是將連續型數值用幾個切點分隔,新增一個類別型變數的技巧。
我們使用 pandas 套件的 cut() 方法。
import pandas as pd
name = ["蒙其·D·魯夫", "羅羅亞·索隆", "娜美", "騙人布", "賓什莫克·香吉士", "多尼多尼·喬巴", "妮可·羅賓", "佛朗基", "布魯克"]
age = [19, 21, 20, 19, 21, 17, 30, 36, 90]
# 建立 dict
straw_hat_dict = {
"name": name,
"age": age
}
# 建立一個 data frame
straw_hat_df = pd.DataFrame(straw_hat_dict)
# 分箱
bins = [0, 25, float("inf")]
group_names = ["小於 25 歲", "超過 25 歲"]
straw_hat_df.ix[:, "age_cat"] = pd.cut(straw_hat_df.ix[:, "age"], bins, labels = group_names)
straw_hat_df

我們使用 cut() 函數。
name <- c("蒙其·D·魯夫", "羅羅亞·索隆", "娜美", "騙人布", "賓什莫克·香吉士", "多尼多尼·喬巴", "妮可·羅賓", "佛朗基", "布魯克")
age <- c(19, 21, 20, 19, 21, 17, 30, 36, 90)
straw_hat_df <- data.frame(name, age)
# 分箱
bins <- c(0, 25, Inf)
group_names <- c("小於 25 歲", "超過 25 歲")
straw_hat_df$age_cat <- cut(straw_hat_df$age, breaks = bins, labels = group_names)
View(straw_hat_df)

經過激烈的資料角力(Data wrangling)之後,我們想要將整理乾淨的資料輸出成 csv 或者 JSON。
我們使用 data frame 的 to_csv() 與 to_json() 方法。
import pandas as pd
name = ["蒙其·D·魯夫", "羅羅亞·索隆", "娜美", "騙人布", "賓什莫克·香吉士", "多尼多尼·喬巴", "妮可·羅賓", "佛朗基", "布魯克"]
age = [19, 21, 20, 19, 21, 17, 30, 36, 90]
# 建立 dict
straw_hat_dict = {
"name": name,
"age": age
}
# 建立一個 data frame
straw_hat_df = pd.DataFrame(straw_hat_dict)
# 輸出為 csv
straw_hat_df.to_csv("straw_hat.csv", index = False)
# 輸出為 JSON
straw_hat_df.to_json("straw_hat.json")
我們使用 write.csv() 函數與 jsonlite 套件的 toJSON() 函數。
library(jsonlite)
name <- c("蒙其·D·魯夫", "羅羅亞·索隆", "娜美", "騙人布", "賓什莫克·香吉士", "多尼多尼·喬巴", "妮可·羅賓", "佛朗基", "布魯克")
age <- c(19, 21, 20, 19, 21, 17, 30, 36, 90)
straw_hat_df <- data.frame(name, age)
# 輸出為 csv
write.csv(straw_hat_df, file = "straw_hat.csv", row.names = FALSE)
# 輸出為 JSON
straw_hat_json <- toJSON(straw_hat_df)
write(straw_hat_json, file = "straw_hat.json")
第十七天我們討論資料角力(Data wrangling)的常用技巧,包含連接、合併與轉置等,我們透過 pandas 與 data frame 的各種方法練習,同時也跟 R 語言使用的各種函數作對照。
同步刊登於 Github:https://github.com/yaojenkuo/learn_python_for_a_r_user



 iThome鐵人賽
iThome鐵人賽