在前面幾篇都是說明如何尋找到你想要的東西,而在接下來的聚合章節中,我們將說來學習到如何使用聚合工具,來幫助我們分析更多資料,以下為本篇要說明的事情。
(aggregate)是啥?有啥用。Mongodb聚合工具Aggregate Framework。pipeline操作符號。(aggregate)是啥?有啥用? ~在前面幾篇文章中,我們學會了mongodb的CRUD,以及使用索引讓我們搜尋、排序速度更快速,那我們接下來幾篇要學什麼?答案就是『分析』,是的,我們將資料存放進mongodb最終的目的就是要使用分析,而聚合就是能幫助我們分析的工具,它能處理數據記錄並回傳結果。
Aggregate Framework ~在mongodb中提供了aggregate framework的聚合工具,使用方法如下,其中AGGREGATE_OPERATION就是指你每一次的處理過程。
db.collection.aggregate(AGGREGATE_OPERATION)
先不考慮mongodb的語言,下面就是一個聚合的範例,mongodb的aggregate framework主要是建立在聚合管道(pipeline)基礎下,而這管道就是可以一連串的處理事件,以下列範例中你可以想成管道中有四節,『將每篇文章作者與like數抓取出來』為第一節,然後它處理完會產生資料,會再丟給第二節[依作者進行分類],直到最後產生結果。
db.collection.aggregate(
[將每篇文章作者與like數抓取出來],
[依作者進行分類],
[將like數進行加總]
[返like數前五多的結果]
)
pipeline操作符號 ~Aggregate framework提供了很多的操作符號,來幫助你進行複雜的操作,每個符號都會接受一堆document,並對這些document做些操作,然後再將結果傳至下一個pipeline直到最後結果出現。
使用$project可以用來選取document中的欄位,還可以在這些欄位上進行一些操作,或是新建欄位。
下面寫個簡單的使用範例。
首先我們有下列的資料。
{
"id" : 1,
"name" : "mark",
"age" : 20,
"assets" : 100000000
}
然後我們可以用$project來決定要那個欄位,我們選取id與name欄位。
db.user.aggregate({ "$project" : { "id" : 1, "name" : 1 }})
結果如下,當然他的功能沒著麼單純,它還可以和很多東西搭配,晚點會說。
{
"_id" : ObjectId("584e73bd6f4811e2ad965055"),
"id" : 1, "name" : "mark"
}
$match主要用於對document的篩選,用個簡單的範例來看看。
{
"id" : 1
"name" : "mark",
"age" : 20,
"assets" : 100000000
},{
"id" : 2
"name" : "steven",
"age" : 40,
"assets" : 1000000
}
然後我們要只選出age為10至30歲的人。
db.user.aggregate({ "$match" : { age : { $gt : 10, $lte : 30 } }})
結果
{
"_id" : ObjectId("584e2c486f4811e2ad965043"),
"id" : 1,
"name" : "mark",
"age" : 20,
"assets" : 100000000
}
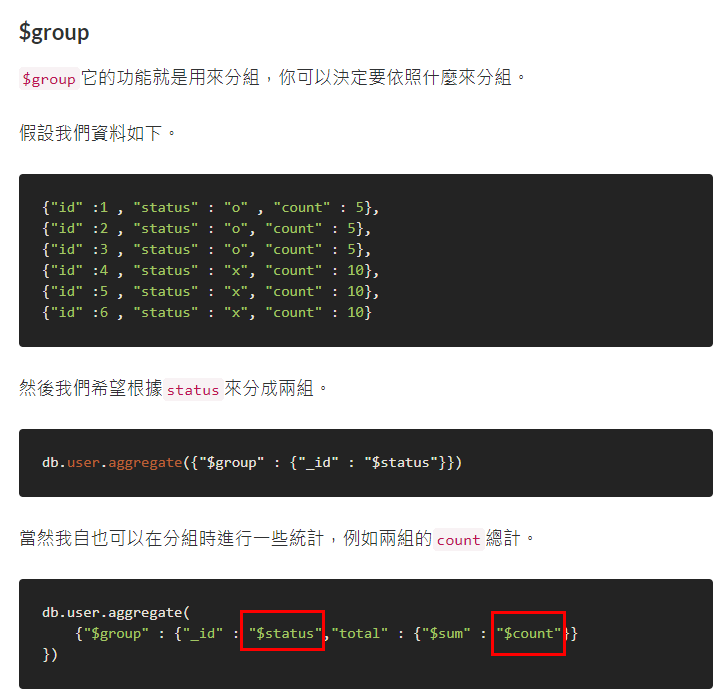
$group它的功能就是用來分組,你可以決定要依照什麼來分組。
假設我們資料如下。
{"id" :1 , "status" : "o" , "count" : 5},
{"id" :2 , "status" : "o", "count" : 5},
{"id" :3 , "status" : "o", "count" : 5},
{"id" :4 , "status" : "x", "count" : 10},
{"id" :5 , "status" : "x", "count" : 10},
{"id" :6 , "status" : "x", "count" : 10}
然後我們希望根據status來分成兩組。
db.user.aggregate({"$group" : {"_id" : "$status"}})
當然我自也可以在分組時進行一些統計,例如兩組的count總計。
db.user.aggregate(
{"$group" : {"_id" : "$status","total" : {"$sum" : "$count"}}
})
結果如下。
{ "_id" : "x", "total" : 30 }
{ "_id" : "o", "total" : 15 }
$unwind英文解釋就是『拆分』,他可以將陣列欄位的每一個值拆分為單獨的document,
來看看下面的範例。
{
"name" : "mark",
"fans" : [
{"name" : "steven","age":20},
{"name" : "max","age":60},
{"name" : "stanly","age":30}
]
}
然後我們希望將fans內的資料拆分成三個document。
db.user.aggregate({"$unwind" : "$fans"})
結果如下。
{ "_id" : ObjectId("584e53246f4811e2ad96504a"),
"name" : "mark",
"fans" : { "name" : "steven", "age" : 20 }
},
{ "_id" : ObjectId("584e53246f4811e2ad96504a"),
"name" : "mark",
"fans" : { "name" : "max", "age" : 60 }
},
{ "_id" : ObjectId("584e53246f4811e2ad96504a"),
"name" : "mark",
"fans" : { "name" : "stanly", "age" : 30 }
}
$sort它可以根據任何欄位進行排序,是的與搜尋時的用法一樣,但是有件事要注意。
如果大量的資料要進行排序,建議在管道的第一節進行排序,因為可以用索引。
假設我們有下列資料。
{"name" : "mark", "age" : 18}
{"name" : "steven", "age" : 38}
{"name" : "max", "age" : 10}
{"name" : "stanlly", "age" : 28}
然後我們要根據age進行排序。
db.user.aggregate({"$sort" : { "age" : 1 }})
結果如下。
{ "_id" : ObjectId("584e71856f4811e2ad96504d"),
"name" : "max", "age" : 10 }
{ "_id" : ObjectId("584e71856f4811e2ad96504b"),
"name" : "mark", "age" : 18 }
{ "_id" : ObjectId("584e71866f4811e2ad96504e"),
"name" : "stanlly", "age" : 28 }
{ "_id" : ObjectId("584e71856f4811e2ad96504c"),
"name" : "steven", "age" : 38 }
就是可以限制回傳document的數量,大致使用法式如下,懶的講太多了。
db.user.aggregate({"$limit" : 5})
$skip就是可以捨棄前n然後在開始回傳結果,以下有點要注意。
就如同在
find時一樣,大量數據下他的效能會非常的差。
db.user.aggregate({"$skip" : 5})
上面將了不少的管道操作符號,不過也只是一個一個分開來使用,接下來我們組合起來一起使用,這才是聚合的真正用法,再開始之前我們複習一下,我們用個表個整理上述的操作符號功用。
| 操作符號 | 功用 |
|---|---|
$project |
選擇集合中要的欄位,並可進行修改。 |
$match |
篩選操作,可以減少不需要的資料。 |
$group |
可以欄位進行分組。 |
$unwind |
拆開,可以將陣列欄位拆開成多個document。 |
$sort |
可針對欄位進行排序 。 |
$limit |
可針對回傳結果進行數量限制。 |
$skip |
略過前n筆資料,在開始回傳 。 |
先看看我們有的資料,它是一堆使用者的基本資料。
{
"id" : 1,
"name" : "mark",
"age" : 20,
"sex" : "M",
"fans" : [{"name" : "steven"},{"name" : "max"}],
"phone" : "xxxxx"
},
{
"id" : 2,
"name" : "steven",
"age" : 40,
"sex" : "M",
"fans" : [{"name" : "mark"},{"name" : "max"}],
"phone" : "xxxxx"
},
{
"id" : 3,
"name" : "marry",
"age" : 30,
"sex" : "S",
"fans" : [{"name" : "mark"},{"name" : "max"},{"name" : "jack"}],
"phone" : "xxxxx"
},
{
"id" : 4,
"name" : "jack",
"age" : 21,
"sex" : "M",
"fans" : [{"name" : "mark"}],
"phone" : "xxxxx"
}
我們可以按照下面的步驟建立管道,來找出第二年輕的男性。
sex為M的user。user的name與age投射出來。age進行排序。1名user。1。根據以上的步驟我們建立出來的聚合如下。
db.user.aggregate(
{ "$match" : { "sex" : "M"}},
{ "$project" : { "name" : 1 , "age" : 1 }},
{ "$sort" : { "age" : 1 }},
{ "$skip" : 1 },
{ "$limit" : 1 }
)
然後執行結果正確,jack的確是第二年輕的男性。
{
"_id" : ObjectId("584e98109ea01650ca1f5617"),
"name" : "jack",
"age" : 21
}
今天簡單的說明了聚合工具Aggregate framework的用法,以及管理的操作符號,不過還缺了一些東西,事實上每個管道內還可以在做更多的事情,這些下一篇文章將會說明到。



 iThome鐵人賽
iThome鐵人賽