還記不記得昨天用forExpression產生一個優雅的employees Set?並且用於UDF中?
val employees = Set() ++ (
for {
line <- Source.fromFile(empPath).getLines
} yield line.trim
)
val isEmp: String => Boolean = {
name => employees.contains(name)
}
val isEmployee = spark.udf.register("isEmpUdf", isEmp)
這個寫法有個問題,如果真的這樣RUN在叢集上的話....
這與階段&工作(stage&task)的概念有關,之後會再多說一點,
現在只需要知道是否有共享變數可以讓每個節點存取一次就好不會重複傳送?
有的,那就是Share variable之一的Broadcast variable(廣播變數),Broadcast是唯讀變數,讓一個節點在多次工作階段內若用到同一份資料集的話,不用多次傳送;另外一大類是Accumulator(累加器),等有恰當例子再來講。
那我們就將Set改造為廣播變數吧:
[Snippet.9]改造為廣播變數
要修改的地方:
val bcEmployees = sc.broadcast(employees) ①
val isEmp = user => bcEmployees.value.contains(user) ②
收工...超簡單吧XDD
①透過sc.broadcast將變數註冊成廣播變數
②要取出廣播變數值要透過bcEmployees.value
也可以在shell中簡單玩一下:
scala> val bcNums=sc.broadcast(List(1,2,3))
bcNums: org.apache.spark.broadcast.Broadcast[List[Int]] = Broadcast(0)
上面範例有沒有哪裡怪怪的?看不出來?再給你個例子你就知道啦:
scala> val nums =sc.parallelize(List(1,2,3))
nums: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> val bcNums=sc.broadcast(nums)
java.lang.IllegalArgumentException: requirement failed: Can not directly broadcast RDDs; instead, call collect() and broadcast the result.
at scala.Predef$.require(Predef.scala:224)
at org.apache.spark.SparkContext.broadcast(SparkContext.scala:1368)
... 48 elided
對啦,broadcast裡面只能放一般集合物件進行註冊,不能放RDD類。若要的話要先collect回Driver端成為一般集合物件再broadcast,這點要特別注意。所以如果要共享超大型集合該怎麼辦?
我目前想法是切partition 或放進Cassandra吧(我是C*粉),這題外話。
改造後完整程式碼:
package SparkIronMan
import org.apache.spark.sql.SparkSession
import scala.io.Source
/**
* Created by joechh on 2016/12/20.
*/
object Day07_Brodcast {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder() ①
.appName("GitHub push counter")
.master("local[*]")
.getOrCreate()
val homeDir = System.getenv("HOME")
val inputPath = homeDir + "/Scala/sparkIronMan/Spark/src/main/resources/day5/2015-03-01-0.json" ②
val githubLog = spark.read.json(inputPath)
val pushes = githubLog.filter("type ='PushEvent'")
import spark.implicits._
val grouped = pushes.groupBy("actor.login").count()
val ordered = grouped.orderBy(grouped("count").desc)
val empPath = homeDir + "/Scala/sparkIronMan/Spark/src/main/resources/day6/ghEmployees.txt" ③
val employees = Set() ++ (
for {
line <- Source.fromFile(empPath).getLines()
} yield line.trim
)
val sc = spark.sparkContext
val bcEmployees = sc.broadcast(employees)
val isEmp: String => Boolean = (name => bcEmployees.value.contains(name))
val isEmployee = spark.udf.register("isEmpUdf", isEmp)
val filtered = ordered.filter(isEmployee($"login"))
filtered.show(5) ④
}
}
接著我們先前的作法執行都是在IDE中執行,接著我們為之後丟到叢集上執行做暖身,透過Spark-submit來遞交工作吧!Spark-submit是一支Spark遞交任務到叢集端的統一腳本,無論未來是用standalone、YARN、Mesos作為叢集管理器,都可以透過同樣一支的遞交程式進行遞交,很棒吧!所以掌握Spark-submit的用法是肯定需要的!
遞交前我們還有幾件事情要做才能正式遞交:
1.改造程式:
現在思維要從單機模式轉換成包裝成一個分散式環境的模式,有幾點要考量
①appName跟master不會寫死在程式中了,會透過spark-submit帶入參數
②與③檔案路徑:檔案路徑也通常會改寫為參數(並且通常是存放在分散式儲存環境例如HDFS或S3上)
④輸出到檔案,而不是show在螢幕上XD
改造完的樣子:
package SparkIronMan
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.SparkSession
import scala.io.Source
/**
* Created by joechh on 2016/12/20.
*/
object Day07_SubmitFormat {
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val spark = SparkSession.builder().getOrCreate() ①
val sc = spark.sparkContext
val githubLog = spark.read.json(args(0)) ②
val pushes = githubLog.filter("type ='PushEvent'")
val grouped = pushes.groupBy("actor.login").count()
val ordered = grouped.orderBy(grouped("count").desc)
val employees = Set() ++ (
for {
line <- Source.fromFile(args(1)).getLines() ③
} yield line.trim
)
val bcEmployees = sc.broadcast(employees)
import spark.implicits._
val isEmp: String => Boolean = (name => bcEmployees.value.contains(name))
val isEmployee = spark.udf.register("isEmpUdf", isEmp)
val filtered = ordered.filter(isEmployee($"login"))
filtered.write.format(args(3)).save(args(2)) ④
}
}
①變簡短了,之後在spark-submit時再宣告
②與③檔案路徑改為吃參數
④DataSet RDD的write支援多種輸出,這邊也參數化一下(arg(3))
④還有save路徑(arg(2))的參數化
在任意終端機打入$sbt package(路徑要在專案的頂層目錄~如下圖):
然後在target目錄下就會產生jar檔:
要特別注意的是package指令不會在jar中打包第三方的函式庫,所以實務上用sbt-assembly plugin搭配生產fatJar時處理衝突的mergeStratgy或shading比較常見。
如果你有把Spark加入你的PATH中那你可以在任意處執行spark-submit,不然就要指到bin下的spark-submit: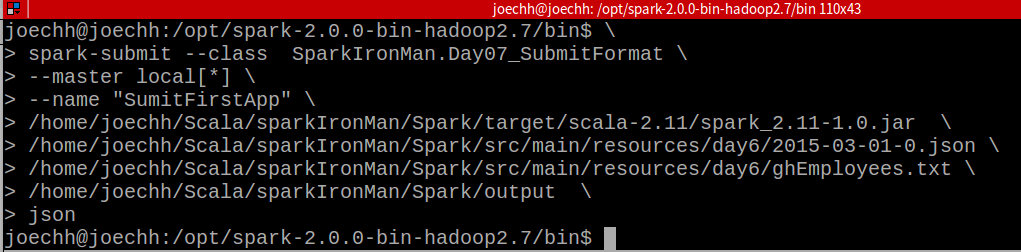
範例中
spark-submit --class:執行main所在的classSparkIronMan.Day07_SubmitFormat--master local[*]: 透過spark-submit,將本機當作一個節點的叢集來執行XD--name "SumitFirstApp": AP名稱,透過觀察工具監控時,以此應用程式會以此命名執行完畢後檢查輸出是否成功(根據你指定的位置),應該會產生類似下圖的樣子:
請問如果有一個資料量很大的變數(比方說某個參照表),也可以註冊成 broadcast variable 嗎? 會不會有效能上的問題?
Hi, 如果真的是超大的參照表,因為broadcast目前的特性會先collect起來,也就是必須至少要能吃進單機才能廣播出去。
我認為broadcast只適合:
如果真非常大,我會建議用NoSQL(Cassandra在對你招手~)
感謝回答~
只是用外部資料庫的話會衍生 latency,尤其是 network latency。如果 Spark framework 裡沒有整合外部資料查詢元件,改用 Batch request 來查詢的話,可能會影響 Spark 的 throughput。
沒錯的確會有latency,假設目前的問題是存一張單機容納不下的超大查找表,那應該就是往兩個分項走:
有時必須在單一App的執行速度與整體throughput中做個tradeOff囉
版主你好,本身是Spark新手,想請教一個問題。就是文章一開頭您說
employees Set會在網路上重複傳送200多次....XDDD
我想了好久還是想不到這個原因,可以幫忙解惑嗎?感激


