我們今天要繼續練習 scikit-learn 機器學習套件,還記得在昨天有提到 Logistic 迴歸雖然冠有迴歸的名稱,但實際上是一個二元分類(Binary classification)演算法嗎?Logistc 迴歸是我們建立的第一個分類器(Classifier)。分類(Classification)與迴歸(Regression)都屬於監督式學習(Supervised learning),一個預測類別目標變數,一個預測連續型目標變數。
我們今天將建立兩個分類器,分別是決策樹分類器(Decision Tree Classifiers)與 k-Nearest Neighbors 分類器,這兩個演算法與 Logistic 迴歸最大的不同點是她們均為多元分類(Multiclass classification)演算法。
同時我們也會開始使用 sklearn.cross_validation 的 train_test_split() 方法來將鳶尾花資料很便利地切分為訓練與測試資料,這是很常會使用的資料預處理方法,透過前述的 train_test_split() 方法,我們可以用一行程式完成。
決策樹分類器(Decision Tree Classifiers)是可以處理多元分類問題的演算法,我們最喜歡她的地方有兩點:
Pclass 與 Sex 這兩個變數創造成 dummy variables,但是決策樹分類器不需要。# ... 前略
# 創造 dummy variables
label_encoder = preprocessing.LabelEncoder()
encoded_Sex = label_encoder.fit_transform(titanic_train["Sex"])
encoded_Pclass = label_encoder.fit_transform(titanic_train["Pclass"])
# ... 後略
Decision Trees Classifiers are a non-parametric supervised learning method used for classification, that are capable of performing multi-class classification on a dataset. The goal is to create a model that predicts the value of a target variable by learning simple decision rules inferred from the data features.
1.10. Decision Trees - scikit-learn 0.18.1 documentation
我們使用 scikit-learn 機器學習套件的其中一個玩具資料(Toy datasets)鳶尾花資料,利用花瓣(Petal)的長和寬跟花萼(Sepal)的長和寬來預測花的種類,藉此練習使用決策樹演算法建立一個三元分類器。如果你對玩具資料感到陌生,我推薦你參考 [第 21 天] 機器學習 玩具資料與線性迴歸。
我們使用 sklearn.tree 的 DecisionTreeClassifier() 方法。
from sklearn.datasets import load_iris
from sklearn import tree
from sklearn.cross_validation import train_test_split
# 讀入鳶尾花資料
iris = load_iris()
iris_X = iris.data
iris_y = iris.target
# 切分訓練與測試資料
train_X, test_X, train_y, test_y = train_test_split(iris_X, iris_y, test_size = 0.3)
# 建立分類器
clf = tree.DecisionTreeClassifier()
iris_clf = clf.fit(train_X, train_y)
# 預測
test_y_predicted = iris_clf.predict(test_X)
print(test_y_predicted)
# 標準答案
print(test_y)

眼尖的你可以仔細看看分類器在哪一個觀測值的預測分類與標準答案不一樣。
我們使用 rpart 套件的 rpart() 函數。
library(rpart)
# 切分訓練與測試資料
n <- nrow(iris)
shuffled_iris <- iris[sample(n), ]
train_indices <- 1:round(0.7 * n)
train_iris <- shuffled_iris[train_indices, ]
test_indices <- (round(0.7 * n) + 1):n
test_iris <- shuffled_iris[test_indices, ]
# 建立分類器
iris_clf <- rpart(Species ~ ., data = train_iris, method = "class")
# 預測
test_iris_predicted = predict(iris_clf, test_iris, type = "class")
test_iris_predicted
# 標準答案
test_iris$Species

眼尖的你可以仔細看看分類器在哪一個觀測值的預測分類與標準答案不一樣。
我們使用準確率(Accuracy)作為分類演算法的績效。
我們使用 sklearn.metrics 的 accuracy_score() 方法計算準確率。
from sklearn.datasets import load_iris
from sklearn import tree
from sklearn.cross_validation import train_test_split
from sklearn import metrics
# 讀入鳶尾花資料
iris = load_iris()
iris_X = iris.data
iris_y = iris.target
# 切分訓練與測試資料
train_X, test_X, train_y, test_y = train_test_split(iris_X, iris_y, test_size = 0.3)
# 建立分類器
clf = tree.DecisionTreeClassifier()
iris_clf = clf.fit(train_X, train_y)
# 預測
test_y_predicted = iris_clf.predict(test_X)
# 績效
accuracy = metrics.accuracy_score(test_y, test_y_predicted)
print(accuracy)

我們透過 confusion matrix 來計算準確率。
library(rpart)
# 切分訓練與測試資料
n <- nrow(iris)
shuffled_iris <- iris[sample(n), ]
train_indices <- 1:round(0.7 * n)
train_iris <- shuffled_iris[train_indices, ]
test_indices <- (round(0.7 * n) + 1):n
test_iris <- shuffled_iris[test_indices, ]
# 建立分類器
iris_clf <- rpart(Species ~ ., data = train_iris, method = "class")
# 預測
test_iris_predicted <- predict(iris_clf, test_iris, type = "class")
# 績效
conf_mat <- table(test_iris$Species, test_iris_predicted)
accuracy <- sum(diag(conf_mat)) / sum(conf_mat)
accuracy

k-Nearest Neighbors 分類器同樣也是可以處理多元分類問題的演算法,由於是以距離作為未知類別的資料點分類依據,必須要將類別變數轉換為 dummy variables 然後將所有的數值型變數標準化,避免因為單位不同,在距離的計算上失真。
The principle behind nearest neighbor methods is to find a predefined number of training samples closest in distance to the new point, and predict the label from these. The number of samples can be a user-defined constant (k-nearest neighbor learning.)
1.6. Nearest Neighbors - scikit-learn 0.18.1 documentation
我們使用 sklearn.neighbors 的 KNeighborsClassifier() 方法,預設 k = 5。
from sklearn.datasets import load_iris
from sklearn import neighbors
from sklearn.cross_validation import train_test_split
from sklearn import metrics
# 讀入鳶尾花資料
iris = load_iris()
iris_X = iris.data
iris_y = iris.target
# 切分訓練與測試資料
train_X, test_X, train_y, test_y = train_test_split(iris_X, iris_y, test_size = 0.3)
# 建立分類器
clf = neighbors.KNeighborsClassifier()
iris_clf = clf.fit(train_X, train_y)
# 預測
test_y_predicted = iris_clf.predict(test_X)
print(test_y_predicted)
# 標準答案
print(test_y)

眼尖的你可以仔細看看分類器在哪一個觀測值的預測分類與標準答案不一樣。
我們使用 class 套件的 knn() 函數,指定參數 k = 5。
library(class)
# 切分訓練與測試資料
n <- nrow(iris)
shuffled_iris <- iris[sample(n), ]
train_indices <- 1:round(0.7 * n)
train_iris <- shuffled_iris[train_indices, ]
test_indices <- (round(0.7 * n) + 1):n
test_iris <- shuffled_iris[test_indices, ]
# 獨立 X 與 y
train_iris_X <- train_iris[, -5]
test_iris_X <- test_iris[, -5]
train_iris_y <- train_iris[, 5]
test_iris_y <- test_iris[, 5]
# 預測
test_y_predicted <- knn(train = train_iris_X, test = test_iris_X, cl = train_iris_y, k = 5)
test_y_predicted
# 標準答案
print(test_iris_y)

眼尖的你可以仔細看看分類器在哪一個觀測值的預測分類與標準答案不一樣。
讓程式幫我們怎麼選擇一個適合的 k,通常 k 的上限為訓練樣本數的 20%。
from sklearn.datasets import load_iris
from sklearn import neighbors
from sklearn.cross_validation import train_test_split
from sklearn import metrics
import numpy as np
import matplotlib.pyplot as plt
# 讀入鳶尾花資料
iris = load_iris()
iris_X = iris.data
iris_y = iris.target
# 切分訓練與測試資料
train_X, test_X, train_y, test_y = train_test_split(iris_X, iris_y, test_size = 0.3)
# 選擇 k
range = np.arange(1, round(0.2 * train_X.shape[0]) + 1)
accuracies = []
for i in range:
clf = neighbors.KNeighborsClassifier(n_neighbors = i)
iris_clf = clf.fit(train_X, train_y)
test_y_predicted = iris_clf.predict(test_X)
accuracy = metrics.accuracy_score(test_y, test_y_predicted)
accuracies.append(accuracy)
# 視覺化
plt.scatter(range, accuracies)
plt.show()
appr_k = accuracies.index(max(accuracies)) + 1
print(appr_k)

k 在介於 8 到 12 之間模型的準確率最高。
library(class)
# 切分訓練與測試資料
n <- nrow(iris)
shuffled_iris <- iris[sample(n), ]
train_indices <- 1:round(0.7 * n)
train_iris <- shuffled_iris[train_indices, ]
test_indices <- (round(0.7 * n) + 1):n
test_iris <- shuffled_iris[test_indices, ]
# 獨立 X 與 y
train_iris_X <- train_iris[, -5]
test_iris_X <- test_iris[, -5]
train_iris_y <- train_iris[, 5]
test_iris_y <- test_iris[, 5]
# 選擇 k
range <- 1:round(0.2 * nrow(train_iris_X))
accuracies <- rep(NA, length(range))
for (i in range) {
test_y_predicted <- knn(train = train_iris_X, test = test_iris_X, cl = train_iris_y, k = i)
conf_mat <- table(test_iris_y, test_y_predicted)
accuracies[i] <- sum(diag(conf_mat))/sum(conf_mat)
}
# 視覺化
plot(range, accuracies, xlab = "k")
which.max(accuracies)

k 在等於 14 與 18 時模型的準確率最高。
第二十三天我們繼續練習 Python 的機器學習套件 scikit-learn,切分熟悉的鳶尾花資料成為訓練與測試資料,並建立了一個決策樹分類器以及一個 k-Nearest Neighbors 分類器,讓程式幫我們選擇合適的 k 值,並且與 R 語言相互對照。
同步刊登於 Github:https://github.com/yaojenkuo/learn_python_for_a_r_user
#sklearn.tree 的方法。從sklearn.cross_validation改成 model_selection
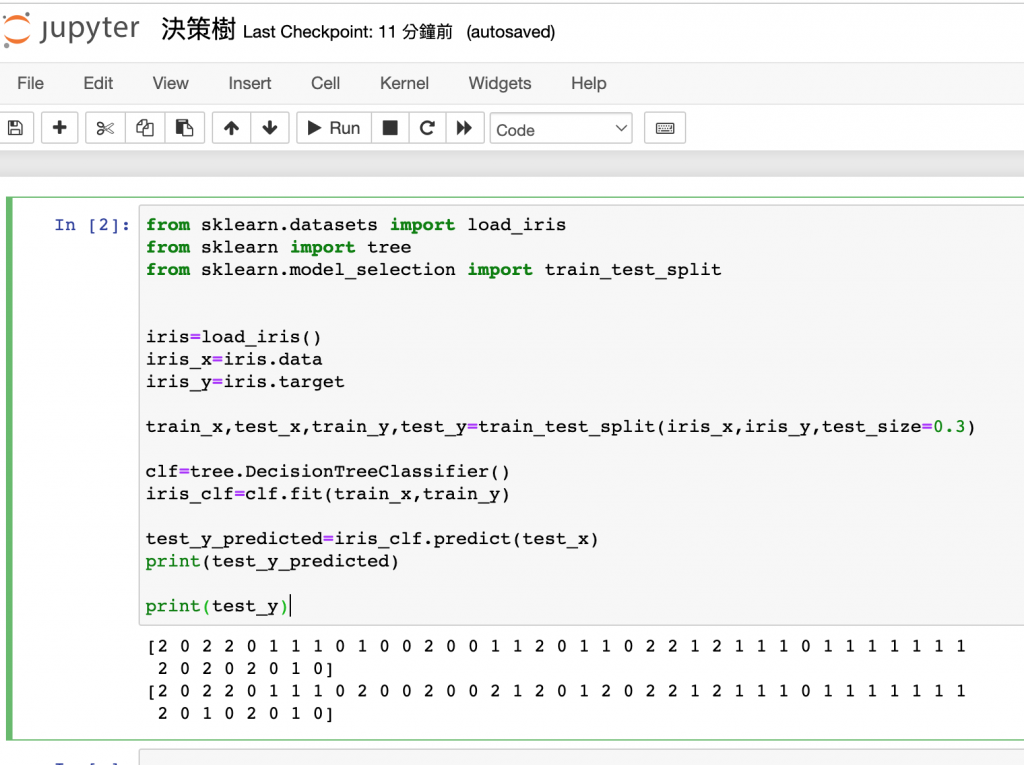
from sklearn.datasets import load_iris
from sklearn import tree
from sklearn.model_selection import train_test_split
iris=load_iris()
iris_x=iris.data
iris_y=iris.target
train_x,test_x,train_y,test_y=train_test_split(iris_x,iris_y,test_size=0.3)
clf=tree.DecisionTreeClassifier()
iris_clf=clf.fit(train_x,train_y)
test_y_predicted=iris_clf.predict(test_x)
print(test_y_predicted)
print(test_y)


