上一篇的寫法不適合大型檔案下載,因為會一次配置整個檔案所需的記憶體空間,並且檔案完全載入後才輸出到瀏覽器,這時如果檔案大小超過 ASP.NET 可用的記憶體上限,就會出現錯誤造成檔案下載失敗。
當然要來證實一下XD,我先產生一個1GB的空白檔案,然後下載看看。
產生空白檔案的方法,開啟 cmd 輸入:fsutil file createnew test.txt 1073741824
fsutil file createnew 檔案名稱 檔案大小 (單位為byte)
1KB = 1 x 1024 = 1024
1MB = 1 x 1024 x 1024 = 1048576
1GB = 1 x 1024 x 1024 x 1024 = 1073741824
執行檔案下載後,程式出錯了。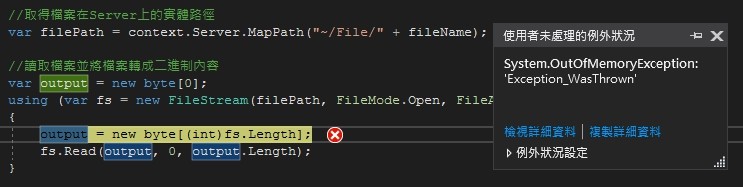
改善方式,不要一次配置整個檔案的記憶體,只配置一小塊緩衝區,每次讀取檔案只讀取一部份到緩衝區,然後馬上輸出到瀏覽器,如此就可以用很少的記憶體完成大型檔案下載的動作,程式碼如下:
public class Download : IHttpHandler
{
public void ProcessRequest(HttpContext context)
{
var index = context.Request.Params["index"];
var fileName = "test.txt";
//取得檔案在 Server 上的實體路徑
var filePath = context.Server.MapPath("~/File/" + fileName);
//緩衝區大小,每次讀取100KB
var bufferSize = 102400;
var buffer = new byte[bufferSize];
var fs = new FileStream(filePath,
FileMode.Open, FileAccess.Read);
//輸出檔案的位元組總長度
var outputLength = fs.Length;
//每次讀取的位元組長度
var readLength = 0;
context.Response.Clear();
context.Response.AddHeader(
"Content-Length", outputLength.ToString());
context.Response.ContentType = "application/octet-stream";
context.Response.AddHeader(
"content-disposition",
"attachment; filename=" + fileName);
//剩餘位元組長度大於零,且與瀏覽器連接著,就繼續執行
while (outputLength > 0 && context.Response.IsClientConnected)
{
readLength = fs.Read(buffer, 0, bufferSize);
context.Response.OutputStream.Write(buffer, 0, readLength);
context.Response.Flush();
outputLength = outputLength - readLength;
}
fs.Close();
context.Response.End();
}
public bool IsReusable
{
get
{
return false;
}
}
}
結果:
相關文章:
[C#] ASP.NET 檔案下載(1) - POST 和 GET 觸發檔案下載
[C#] ASP.NET 檔案下載(2) - 大型檔案下載
[C#] ASP.NET 檔案下載(3) - 檔案續傳
其實我滿好奇的,我現在做檔案下載都是直接用放href耶
這兩種方式有差別嗎?
是指程式讀取和href放檔案路徑嗎?
如果沒有特殊需求,我會用href,因為IIS會處理好其他細節,就不用自己手刻XD
但如果有特殊需求,例如: 檔案要加權限、檔案存在資料庫、檔案是動態產生(PDF報表)、等等...,就會需要程式控制。
以上是我的一些心得XD
 小碼農米爾
小碼農米爾
