其實 Kubernetes 官方的文件,已經將 Kubernetes 上的每個元件的功能都已解釋的非常清楚。官網上現在也提供 互動式學習的教學,對於有心想學習Kubernetes讀者,這兩者都是非常有幫助的資源。然而筆者在自學的過程中,發覺若是能先暸解 Kubernetes 內部如何運作,對於之後學習 Kubernetes 的基礎元件是非常有幫助的,因此今天的學習筆記,除了介紹 Node 元件 以外,也會從一個概觀的角度去介紹 Kubernetes 的內部運作。
今日內容如下:
在 Kubernetes 中,Node 通常是指實體機、虛擬機。一個Node,可以是指 AWS的一台EC2 或 GCP上的一台computer engine ,也可以是你的筆電,甚至是一台 Raspberry Pi。只要他們上面裝有 Docker Engine ,足以跑起 Pod,就可以被加入 Kubernetes Cluster。
將 Node 加到 Kubernetes 中之後,Kubernetes 會建立一個Node 物件,並進行一連串檢查,包含網路連線,Pod 是否能被正常啟動等,若都通過則會將該Node物件的狀態設為 Ready,若是無法通過則會顯示 Not Ready
若還是記得 第二天在本機端架好的 minikube,輸入 kubectl get nodes 指令,就可以發現 minikube 已在其中

當然也可以使用 kubectl describe nodes 取得該 Node 的詳細資料,以下以 minikube 為例 (更多 log 可參考 kubectl-describe-node-minikube),
$ kubectl describe nodes minikub
由於我們目前是在本機端操作,只有一個 Node。在 未來的學習筆記 中,也會介紹到如何利用第三方套件 kops 在 AWS 上打造多台機器的 Kubernetes Cluster
過去是一台 Node 指運行可能只運行一個應用服務(application),若是該應用服務(application) 只使用 I/O 資源,免不了 Node 上閒置 memory 的浪費;若是為了避免閒置資源,而將多個服務同時運行在同一台 Node 上,運維人員還需隨時掌控目前各個應用服務使用資源狀況,避免資源不足情形。而在 Kubernetes 上,當我們將 Node 都加到 Kubernetes Cluster 後,系統會根據目前 Pod 的設定檔去決定要部署在哪個 Node 上。在未來讀書筆記 [Day 27] 如何限制每個服務資源 - Resource Quotas 也會分享這部分。
在實際場景應用上,Kubernetes 是會由多台 Node 組成,今天將藉由底下這張 簡化的 Kubernetes 系統架構圖 講解 Kubernetes 的內部是如何溝通(圖中並無 Master Node):
Master Node 主要用來管理與調度Kubernetes Cluster 中所有物件的狀態,讀者只需有有該概念即可,在 [Day 26] 介紹Kubernetes調度中心 - Master Node 會更詳細介紹。
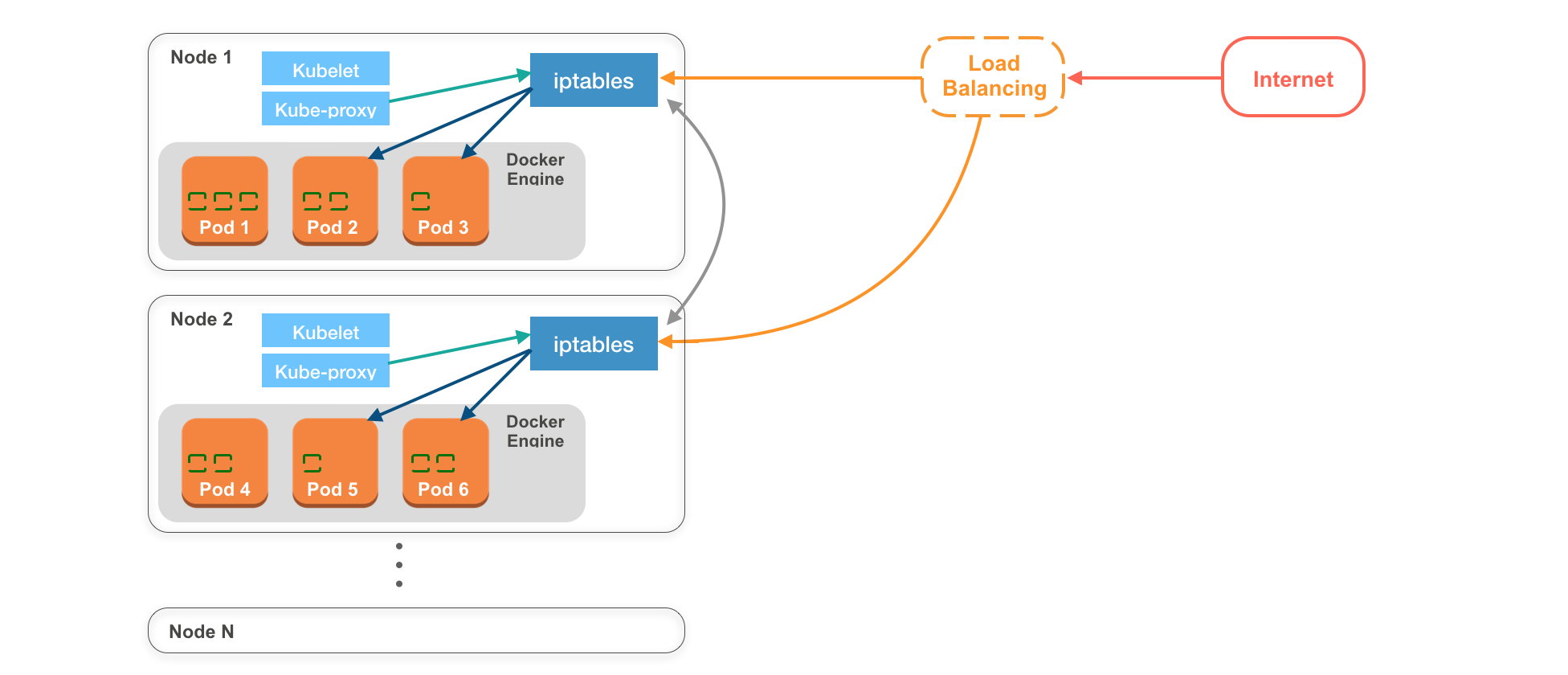
該圖中的 Kubernetes Cluster 有 N 個 Nodes,Node 1, Node 2, ... Node N
每個 Node 都必須跑起 Container Engine 以便於運行 Pods。
而在30天教學筆記中使用的是 Docker Engine。
圖中,一個橘色框分別代表一個 Pod ,而 Pod 中綠色的空心方型則代表一個container。以 Pod 3 與 Pod 5 為例,這兩個 Pod 分別只運行一個 container;而在 Pod 1 中則運行三個 containers。
圖中每個 Node 都有屬於它自己的 iptables,iptables 是 Linux 上的防火牆(firewall),不只限制哪些連線可以連進來,也會管理網路連線,決定收到的 request 要交給哪個 Pod。
在對這張架構圖有基本認識之後,我們會藉由這張圖來解釋每個 Kubernetes 的內部是如何溝通:
由於每個Pod中有自己的網路。所以同一個Pod中的containers之間可以透過**<localhost:port_num>**互相溝通。而這樣無需透過外網的性質,讓我們可以將性質相近的服務放在同一個Pod裡,好比一個後端API service,與一個後端認證service,可以放在同一個pod裡互相溝通。
在每個 Node物件 中都會有,kubelet與kube-proxy
kubelet
kubelet相當於 node agent,用於管理該 Node 上的所有 pods以及與 master node 即時溝通。
kube-proxy
kube-prox y則是會將目前該 Node 上所有 Pods 的資訊傳給 iptables,讓 iptables 即時獲得在該 Node 上所有 Pod 的最新狀態。好比當一個 Pod物件 被建立時,kube-proxy 會通知 iptables,以確保該 Pod 可以被 Kubernetes Cluster 中的其他物件存取。
Load balancing
在實際場景中,收到外部傳來的 requests 都會先交由 Load balancer 處理,再由 Load balancer 決定要將 request 給哪個 Node ,通常 Load balancer 都是由 Node 供應商提供,好比 AWS 的 ELB,或是自己架設 Nginx 或 HAProxy 等專門做負載平衡的服務。
首先,kubelet 會先收到 master node 指令,創建一個 Pod。創建好後,kube-proxy 會去告知 iptables,目前該 Pod 可用。
當使用者透過 網路(internet) 發送 requests 時,requests 會先送到 Load Balancer,由 Load Balancer 決定要把request交給哪個 Node,這時收到 requests的 Node 會經由 iptables 決定要送給哪個 Pod 。
但如果收到request的 Node 恰好沒有相對應可以處理 request Pod 的話,原本收到 request 的 Node 會透過 iptables 把 request 轉給其他有可以處理這個 request 的 Node 。
在 Kubernetes 的 Github 上對 Kubernetes 的架構做了詳細的介紹,對於 Kubernetes 內部運作有興趣的讀者不妨看一看。明天的學習筆記,將介紹 Kubernetes 的另一個重要的核心元件 Replication Controller
依舊歡迎大家給予建議與討論,如果能按個讚給些鼓勵也是很開心唷 : )
想請問最後的
但如果收到request的 Node 恰好沒有相對應可以處理 request Pod 的話,原本收到 request 的 Node 會透過 iptables 把 request 轉給其他有可以處理這個 request 的 Node 。
這個 Node 要怎麼知道 收到的 request 可以轉發給哪個node?
這裡我寫的不太好,事實上所有請求(request)要最終指向哪個 Pod 都是 kube-proxy 與 iptables決定的。
解釋之前,我們可能要先知道 Kubernetes 中的 Endpoints
每次新的 Service 建立,Kubernetes 也會創建一個 Endpints 物件,用來儲存這個新建立的 Server 與相對應的 Pods 的關係。好比有一個 Service
{
“name”: “nginx”,
“endpoints”: [“10.0.0.1”, “10.0.0.2”]
}
代表這個名為 nginx 的 service,後面有兩個相對應的 Pods,cluster ip 分別是 “10.0.0.1” 與 “10.0.0.2”
而 Endpoint 也會跟隨 Pod 目前的狀況動態改變紀錄的值,確保每次 service 傳進來的請求都能找到相對應的 Pod。
若是有興趣,可以在每次創建好一個 service 物件後,透過 kubectl describe 或 kubectl get ep指令,都可以看到該 service 對應的 endpoint 的資料。或是也可以參考 官網提供的 kubectl describe svc 範例
事實上,每個 Node 上都有自己的kube-proxy 與 iptables,一旦有新的 Service 建立或是改動後,每個 kube-proxy 都會針對該 Service 設置相同的轉送規則,並將這些 rule 存在 iptables。(可以說是每個 Node 上的 kube-proxy 都會知道所有 service 的狀態)
Kube-proxy 會依據 endpoint 紀錄的 ip 清單,透過 Round Robin 的方式,在本機端的記憶體尋找是否存在相對應 ip ,如果有就指向相對應的 Pod 物件(代表 Pod 在 Node 上)。如果沒有,則會選擇 endpoint 中的一組 ip,將存取請求指向該 ip,由該 ip 相對應的物件處理(將 request 送到另外一個 Node)。
非常感謝您的詳細回應,但我看過兩三次後,覺得應該沒有回答到我的疑問,或是我還不太能理解其中的運作原理。
我先釐清一下其他問題
hi @herb123456,
kube-proxy 與 iptables,所有請求最終要指向哪個 Pod 都是 kube-proxy 與 iptables決定的。kube-proxy 會依據 endpoint 紀錄的 ip 清單,透過 Round Robin 的方式,在本機端的記憶體尋找是否存在相對應 ip ,如果有就指向相對應的 Pod 物件(代表 Pod 在 Node 上)。如果沒有,則會選擇 endpoint 中的一組 ip,將存取請求指向該 ip,由該 ip 相對應的物件處理(將 request 轉送到另外一個 Node)。也就是,當 Node 收到 request 後,Node 上的 kube-proxy 會決定要送到哪個 Pod ip address,再由 iptables 轉發。感謝您的熱心回應
大部分的疑問都了解了
但我還有個疑問就是你最後提到的
如果沒有,則會選擇 endpoint 中的一組 ip,將存取請求指向該 ip,由該 ip 相對應的物件處理(將 request 轉送到另外一個 Node)。
此份 endpoint 清單,是記錄誰的ip?
依據您之前的回應
kube-proxy 會依據 endpoint 紀錄的 ip 清單,透過 Round Robin 的方式,在本機端的記憶體尋找是否存在相對應 ip ,如果有就指向相對應的 Pod 物件(代表 Pod 在 Node 上)
這份 ip 清單是否為 pod 的 ip 清單?抑或是還有紀錄其他 node 的清單呢?
若是還有紀錄其他node的清單,但這時候又該怎麼知道要轉給哪個node呢?
總不可能隨機挑選一個node,然後很不幸的要在最後一個node才有pod可以處理這個request?
我其實一直對會把這個request轉給其他node有很大的問號啊。
Hi @herb12346,
1/ 沒錯 endpoint 會記錄 pod ip list。之後不妨可以試試建立一個 service 與一個相對應的 pod,再用 kubectl describe 去查看 service 的資料,會發現endpoint的欄位後面記錄的會是該對應pod的 Cluster IP
2/接續我們上述以及前面提到的, kube-proxy 會從 endpoint 找到 pod IP list ,會用 Round Robin 的方式去找對應的 pod 。每個 Node 都有自己的 kube-proxy ,如果接收到請求的 kube-proxy 發現在同一個 node 中有相對應的 pod 物件,就會將流量導到該 pod ;然而,若是這個 kube-proxy 選擇的 pod 部署在其他 node 上,則會透過 iptables 將這個流量導到有對應的 node 上。在文中提到的 把 request 轉給其他有可以處理這個 request 的 Node 便是這個意思,不是隨機挑選一個 Node 而是由 kube-proxy 決定把流量要給那個 node 。
也很開心有人提問呢,希望這樣有解答你的疑惑!
原來如此啊
所以每一份清單都會紀錄其他node上的pod嗎?
也就是這份清單是每個node都會相同嗎?
理論上是喔~



 iThome鐵人賽
iThome鐵人賽