
現在網友都勇於發聲,網路聲量高漲,往往會引領群眾的意向,引發巨大能量,影響國家命運,例如太陽花運動、埃及茉莉花革命,因此,輿情分析已經變成顯學,如何收集網路正反意見,進行大數據分析,已是各個先進國家政府必修的課程,所以,這次我們就以『情緒分析』(Sentiment Analysis) 為主題,說明 LSTM 如何進行情緒分析。
以下範例檔案名稱為 Sentiment1.py,程式來自利用 Keras 下的 LSTM 进行情感分析,同樣的,我加了一些註解,也可從這裡下載。
# scikit-learn 須升級至 0.19
# pip install -U scikit-learn
# 在 python 執行 nltk.download(), 下載 data
from keras.layers.core import Activation, Dense
from keras.layers.embeddings import Embedding
from keras.layers.recurrent import LSTM
from keras.models import Sequential
from keras.preprocessing import sequence
from sklearn.model_selection import train_test_split
import collections
import nltk
import numpy as np
from keras.models import load_model
## 探索數據分析(EDA)
# 計算訓練資料的字句最大字數
maxlen = 0
word_freqs = collections.Counter()
num_recs = 0
with open('./Sentiment1_training.txt','r+', encoding='UTF-8') as f:
for line in f:
label, sentence = line.strip().split("\t")
words = nltk.word_tokenize(sentence.lower())
if len(words) > maxlen:
maxlen = len(words)
for word in words:
word_freqs[word] += 1
num_recs += 1
print('max_len ',maxlen)
print('nb_words ', len(word_freqs))
## 準備數據
MAX_FEATURES = 2000
MAX_SENTENCE_LENGTH = 40
vocab_size = min(MAX_FEATURES, len(word_freqs)) + 2
word_index = {x[0]: i+2 for i, x in enumerate(word_freqs.most_common(MAX_FEATURES))}
word_index["PAD"] = 0
word_index["UNK"] = 1
index2word = {v:k for k, v in word_index.items()}
X = np.empty(num_recs,dtype=list)
y = np.zeros(num_recs)
i=0
# 讀取訓練資料,將每一單字以 dictionary 儲存
with open('./Sentiment1_training.txt','r+', encoding='UTF-8') as f:
for line in f:
label, sentence = line.strip().split("\t")
words = nltk.word_tokenize(sentence.lower())
seqs = []
for word in words:
if word in word_index:
seqs.append(word_index[word])
else:
seqs.append(word_index["UNK"])
X[i] = seqs
y[i] = int(label)
i += 1
# 字句長度不足補空白
X = sequence.pad_sequences(X, maxlen=MAX_SENTENCE_LENGTH)
# 資料劃分訓練組及測試組
Xtrain, Xtest, ytrain, ytest = train_test_split(X, y, test_size=0.2, random_state=42)
# 模型構建
EMBEDDING_SIZE = 128
HIDDEN_LAYER_SIZE = 64
BATCH_SIZE = 32
NUM_EPOCHS = 10
model = Sequential()
# 加『嵌入』層
model.add(Embedding(vocab_size, EMBEDDING_SIZE,input_length=MAX_SENTENCE_LENGTH))
# 加『LSTM』層
model.add(LSTM(HIDDEN_LAYER_SIZE, dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(1))
model.add(Activation("sigmoid"))
# binary_crossentropy:二分法
model.compile(loss="binary_crossentropy", optimizer="adam",metrics=["accuracy"])
# 模型訓練
model.fit(Xtrain, ytrain, batch_size=BATCH_SIZE, epochs=NUM_EPOCHS,validation_data=(Xtest, ytest))
# 預測
score, acc = model.evaluate(Xtest, ytest, batch_size=BATCH_SIZE)
print("\nTest score: %.3f, accuracy: %.3f" % (score, acc))
print('{} {} {}'.format('預測','真實','句子'))
for i in range(5):
idx = np.random.randint(len(Xtest))
xtest = Xtest[idx].reshape(1,MAX_SENTENCE_LENGTH)
ylabel = ytest[idx]
ypred = model.predict(xtest)[0][0]
sent = " ".join([index2word[x] for x in xtest[0] if x != 0])
print(' {} {} {}'.format(int(round(ypred)), int(ylabel), sent))
# 模型存檔
model.save('Sentiment1.h5') # creates a HDF5 file 'model.h5'
##### 自己輸入測試
INPUT_SENTENCES = ['I love it.','It is so boring.', 'I love it althougn it is so boring.']
XX = np.empty(len(INPUT_SENTENCES),dtype=list)
# 轉換文字為數值
i=0
for sentence in INPUT_SENTENCES:
words = nltk.word_tokenize(sentence.lower())
seq = []
for word in words:
if word in word_index:
seq.append(word_index[word])
else:
seq.append(word_index['UNK'])
XX[i] = seq
i+=1
XX = sequence.pad_sequences(XX, maxlen=MAX_SENTENCE_LENGTH)
# 預測,並將結果四捨五入,轉換為 0 或 1
labels = [int(round(x[0])) for x in model.predict(XX) ]
label2word = {1:'正面', 0:'負面'}
# 顯示結果
for i in range(len(INPUT_SENTENCES)):
print('{} {}'.format(label2word[labels[i]], INPUT_SENTENCES[i]))
我們再次見識到 Neural Network 的強大威力,要作到輿情分析,只要先撰寫爬蟲程式,抓取網路評論,再將資料餵入LSTM 模型,統計正負評或作更細的分類,就可以自己開民調公司了(開開玩笑!!),下次見了。
在這個資料集中的X是句子用onehot轉成向量,Y是情緒(我看了一下原文,只有1與0),不知道我的理解有沒有錯。
如果沒有錯的話,想請教一個問題,你文章都說,不管是RNN或是LSTM都是透過把前面字詞的權重,用來預測中間或是下一個要出現的字,這樣的問題中,X是前面出現過的字,Y是即將要出現的字,LSTM跟RNN的差別只是在,權重的安排RNN會遞減,LSTM會選擇性紀錄。但是怎麼樣把這樣的問題mapping成情緒分析問題?
具體一點來問,我不太清楚,他recurrent的東西如果是裡面的前後字詞,那是不是會比較像在input layer中每個node之間做forward prop,而不是在layer間做forward prop,那怎麼把w傳遞到下一個layer,並且最後預測出最後的結果?
以上個人淺見,如有疏漏或錯誤,請不令指正。
另外,為了讓了RNN/LSTM模型能更準確判斷前文,可以試試看加入 Stop words,把不重要的單字(I, you, it, ...)移除掉,讓前文的影響力更明確,記憶(Ct)判斷更精準,建議讀者可以異想天開的實驗,也許您可能是下一位AI大師喔。
抱歉一直打擾你,因為我最近卡在這裡,無法理解QQ
你這幾篇文章我都有認真看,不過還是不是很清楚。我想確定一下你的意思,「RNN/LSTM會額外考慮『同一個Layer』前面的output」的意思,是不是指,假設onehot的情況下,第1個epoch的Input layer中某個字(node)的output,會被傳遞到第2個epoch的Input layer同個字的Input?
但我真的好難想像,但這樣真的好難跟「例如,聽到『我看見...』,下面應該就是一個名詞,通常是人或物,又例如『它很...』,下面應該就是一個形容詞,例如『辣』、『鹹』。」這種東西連結起來。
它可以讓預測變得更準確的原因感覺又更神秘了。
感謝你認真地回應TAT
不要客氣,相互切磋,才會進步。
simple NN 不考慮 activation function 時,y=Wx+b。
RNN 不考慮 activation function 時,公式如下,會多考慮 h(t-1), 這裡的h可簡單視為y。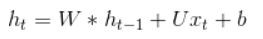
您好,我在spyder上執行Sentiment1.py時出現了問題FileNotFoundError: [Errno 2] No such file or directory: './Sentiment1_training.txt'
我有先執行過nltk.download(),並下載了他所有的package,也試過將Sentiment1.py放在資料下載的地方,請問我該如何解決?
Sentiment1_training.txt 未放入程式所在的目錄。
您好請教一下,
word_index["PAD"] = 0
word_index["UNK"] = 1
請問這兩行的用意是什麼呢?謝謝
word_index["PAD"] = 0 --> 空白的索引值設為0
word_index["UNK"] = 1 --> 未知單字的索引值設為1
原來如此,感謝您!
抱歉再請教您一個問題...
有關模型建構的訓練參數(如以下您定義的):
EMBEDDING_SIZE = 128
HIDDEN_LAYER_SIZE = 64
BATCH_SIZE = 32
NUM_EPOCHS = 10
是如何去決定的呢?比方說為何EMBEDDING_SIZE是128而不是256?
謝謝!
神經網路是一個黑箱科學,必須靠經驗與實驗,找到最佳參數值,所以,這些值都是可以任意設定的。
原來如此,了解了XD 感謝回覆!

