在上一篇([07]更深入看看Hadoop裡面的YARN和HDFS)了解了整個jps的process代表的意思之後,在這篇將會延續之前([05]建立Hadoop環境 -上篇、[06]建立Hadoop環境 -下篇)建立出來pseudo-distributed mode的hadoop改成 fully-distributed mode
這篇結束之後,除了Master,會建立出一台slave。由於Master裡面也有DataNode和NodeManager,所以總共會有2個DataNode。
同步發表於我的部落格:http://blog.alantsai.net/2017/12/data-science-series-08-hadoop-fully-distributed-mode-tutorial.html (部落格的格式會漂亮一些,ithome不支援html好不方便)
基本上整個的建立步奏可以分為6個部分:
開啟Terminal(快速鍵Ctrl+Alt+ t)然後輸入:sudo gedit /etc/hosts
在裡面的檔案把ubuntu改成master
調整host
記得透過右上角把整個機器重啟,然後開termianl會發現@後面是master
重啟機器和檢查terminal是不是變成master
重啟了之後,當輸入指令會需要等一下,因為他會嘗試和master溝通 - master不存在所以要等一下他timeout才會出現
透過右上角的network資訊找到目前機器的ip,並且用terminal執行:sudo gedit /etc/hosts
在裡面加入:{ip} master - ip是上面找到的ip
找到ip
設定master的host ip
在terminal執行:gedit /usr/local/hadoop/etc/hadoop/master
在開的檔案,把裡面內容改成master
改成master
在terminal輸入:gedit /usr/local/hadoop/etc/hadoop/core-site.xml
把整個configuration內容改成:
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
這邊把localhost改成了master
用terminal開啟:gedit /usr/local/hadoop/etc/hadoop/hdfs-site.xml
在Configuration最後一筆的前面加上:
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
修改畫面
在terminal輸入:gedit /usr/local/hadoop/etc/hadoop/mapred-site.xml
增加以下設定Configuration:
<property>
<name>mapred.job.tracker</name>
<value>master:54311</value>
</property>
設定畫面
在terminal輸入:gedit /usr/local/hadoop/etc/hadoop/yarn-site.xml
增加以下設定到Configuration:
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8025</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8050</value>
</property>
增加yarn site設定
用terminal輸入:gedit /usr/local/hadoop/etc/hadoop/slaves
改成以下設定:
master
slave1
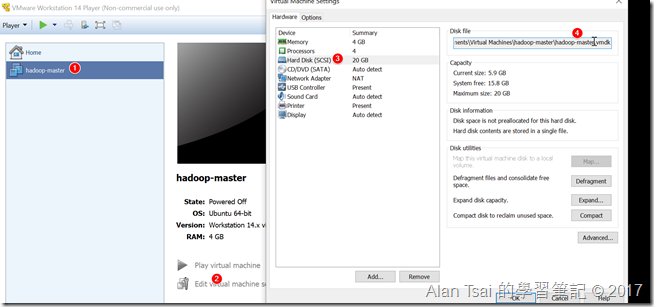
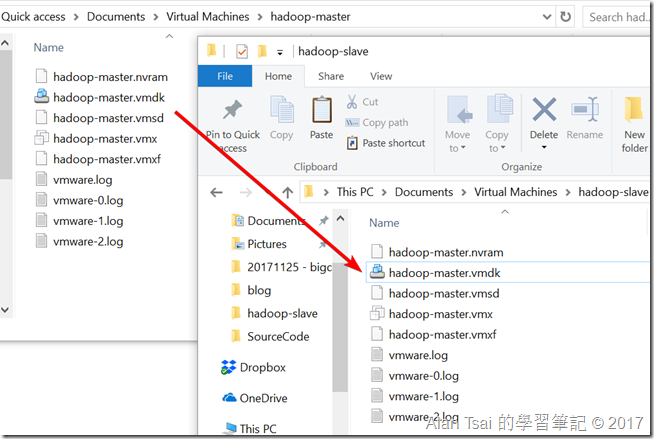
先從設定找到Master VM的設定位置,並且複製一份出來
透過設定找到VM檔案位置
用開啟VM的方式打開複製出來的VM
開啟VM並且改成hadoop-slave
對開啟的VM做出:

選擇I Copied It
最後把兩個VM都啟動起來,可以再上面的title看到那一台是master和那台是slave
兩台機器啟動起來
開啟Terminal(快速鍵 Ctrl+Alt+ t)然後輸入: sudo gedit /etc/hosts
在裡面的檔案把 master改成 slave1
調整host
記得一樣要重啟機器才會有作用
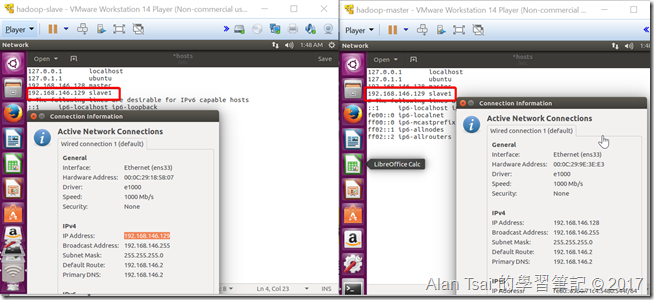
透過右上角的network資訊找到slave機器的ip,並且在master和slave的機器terminal執行:sudo gedit /etc/hosts
在裡面加入:{ip} slave1 - ip是上面找到的ip
兩台都要修改
分別從master那台的terminal呼叫:ping slave1和slave那台機器的terminal呼叫:ping master
確保兩台之間溝通沒有問題
兩台互相ping
在master的機器把slave ssh key建立出來然後做出測試,在terminal執行:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
scp -r ~/.ssh slave1:~/
ssh slave1
exit
測試ssh畫面
在master輸入以下來重建資料夾:
sudo rm -rf /usr/local/hadoop/hadoop_data/hdfs
mkdir -p /usr/local/hadoop/hadoop_data/hdfs/namenode
mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode
sudo chown -R hduser:hduser /usr/local/hadoop
在slave輸入以下來重建對應資料夾:
sudo rm -rf /usr/local/hadoop/hadoop_data/hdfs
mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode
sudo chown -R hduser:hduser /usr/local/hadoop
在master輸入以下來format hdfs:
hadoop namenode -format
hadoop datanode -format
在slave輸入以下來format hdfs:
hadoop datanode -format
在master呼叫start-all.sh(這邊偷懶了,其實比較建議呼叫start-yarn和start-hdfs)來啟動整個hadoop。
啟動了之後可以再兩台的jps看到服務都出現:
master同時也是slave
檢查ResourceManager,在Firefox輸入:http://localhost:8088
可以看到有兩個Node
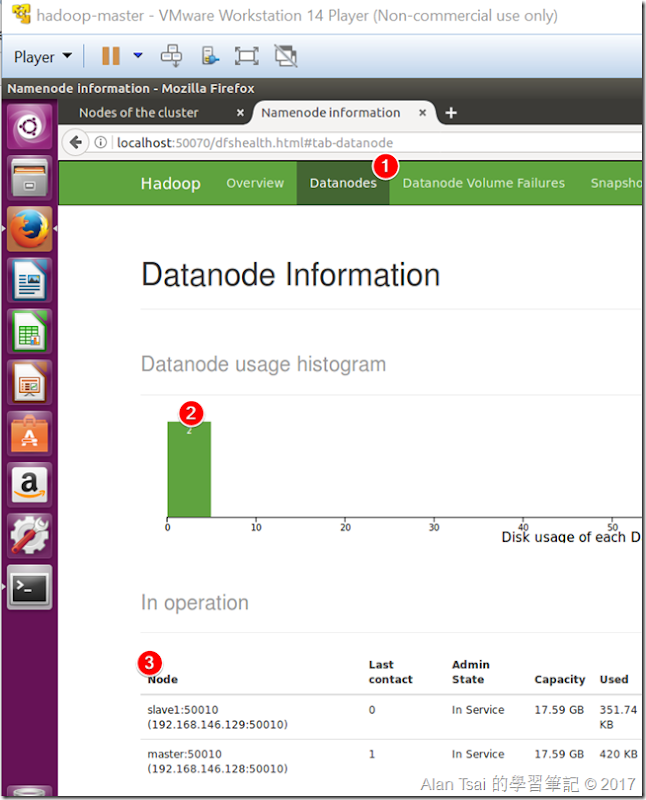
檢查DataNode,在Firefox輸入:http://localohost:50070
可以看到有兩個DataNode
執行方式和之前一模一樣:
cd ~/Downloads
hadoop fs -mkdir -p /user/hduser/input
hadoop fs -copyFromLocal jane_austen.txt /user/hduser/input
執行WordCount程式:hadoop jar wordcount2.jar WordCount /user/hduser/input/jane_austen.txt /user/hduser/output
檢查執行結果:hadoop fs -cat /user/hduser/output/part-r-00000
如果要在執行一次計算,需要先把hdfs裡面的output砍掉,要不然會執行不了。指令是:hadoop fs -rm -r /user/hduser/output
如果執行有問題,或者run不起來,可以試試重開機,然後從測試Hadoop裡面的格式化HDFS開始重新做一次。
在這篇,透過之前建立的VM轉換成為Master,並且在從這個Master複製出來變成slave。
可以想象,如果要串聯多台電腦可以用這種方式達到分散式運算和分散式檔案儲存。只不過這邊用VM來模擬這個情況。
基本上,到目前為止對於整個Hadoop應該已經有個比較完整的感覺,並且了解如何建立一個測試來玩玩看。
不過有一個部分還沒有介紹,就是MapReduce裡面執行的WordCount程式是怎麼建立出來。
工商服務
今年的團隊機制不知不覺就集合了10位隊(坑)友 - 大家幫忙多多關注別不小心我們就gg了 XD
** 一群技術愛好者與一名物理治療師的故事 提醒著我們 千萬不要放棄治療 **
沉浸於.Net世界的後端工程師,樂於分享,現任台中Study4成員之一。除了程式以外,就愛看小說。
歡迎有任何問題或者建議都可以告訴我,可以再以下找到我:
部落格:Alan Tsai的學習筆記
我的Linkedin
我的粉絲頁
我的github
我的Slideshare
我的Twitter