Introduction
自動編碼器(Autoencoders)是一種無監督學習人工神經網路。
使用機器學習的有損資料壓縮(lossy compression),目的是訓練出一套資料表示方法來表示一個資料集,經常被用於資料降維。
有損壓縮,因此當一段資訊被編碼並解碼還原,在該過程會丟失一些訊息,他不是真正的資料壓縮,而是應用在資料降噪和資料降維。
Tasks
學習資源:
cntk\Tutorials\CNTK_105_Basic_Autoencoder_for_Dimensionality_Reduction.ipynb
訓練一個自動編碼器,將 MNIST 資料集壓縮成一個更小維度的向量,然後再保存成圖像。
快速模式:isFast設置為True。
我們對有限的數據進行更少的迭代或訓練。 這確保功能正確性,儘管產生的模型準確率並不高。
isFast = True
1.資料讀取(Data reading):
讀取本地端資料集。
cntk\Examples\Image\DataSets\MNIST
2.資料處理(Data preprocessing):
無。
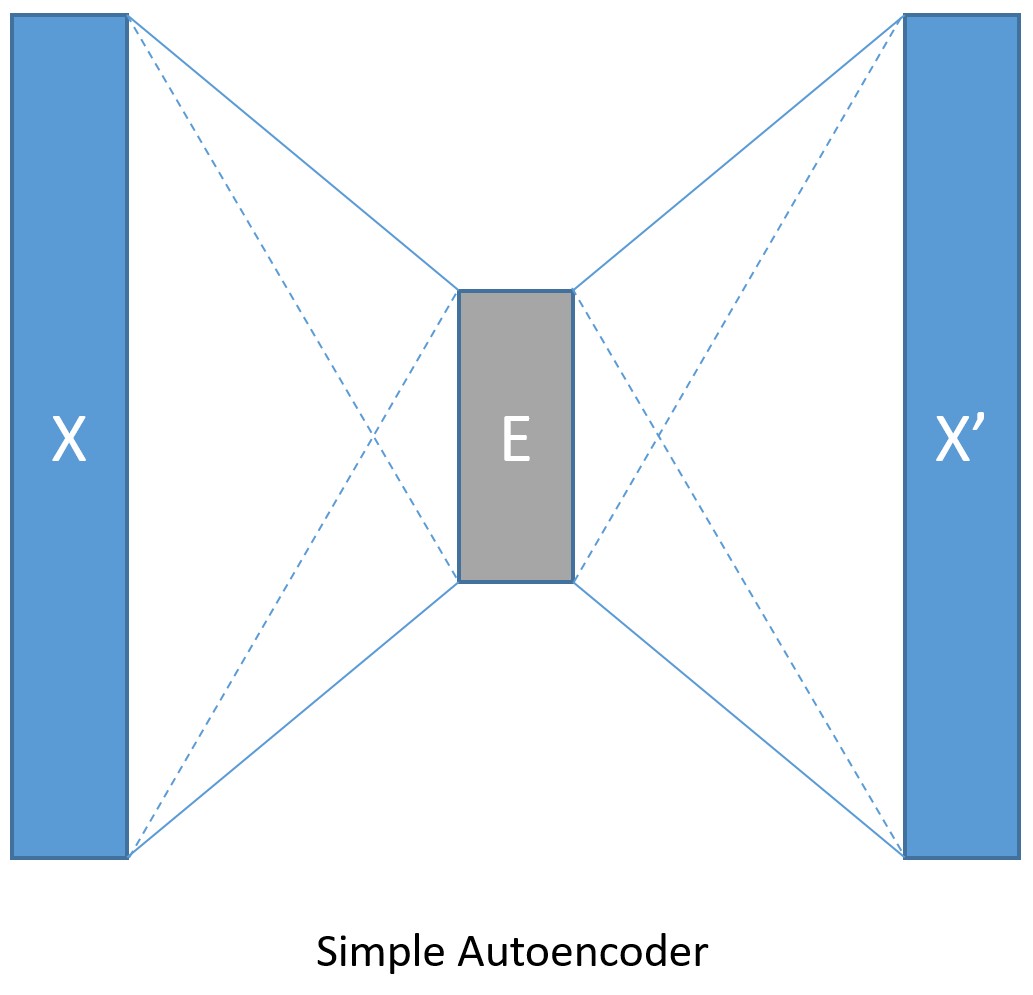
3.建立模型(Model creation):簡單自動解碼器
MNIST 資料集的圖像是 28 * 28 像素,每個圖像都存在陣列中,輸入值就是 28 * 28 = 784。
設定壓縮後的數據大小是 32。
資料編碼後解碼,輸出的大小跟輸入的大小一樣。
input_dim = 784
encoding_dim = 32
output_dim = input_dim
宣告函式:create_model
def create_model(features):
with C.layers.default_options(init = C.glorot_uniform()):
# 輸入值歸一化成 0 ~ 1 之間
encode = C.layers.Dense(encoding_dim, activation = C.relu)(features/255.0)
decode = C.layers.Dense(input_dim, activation = C.sigmoid)(encode)
return decode
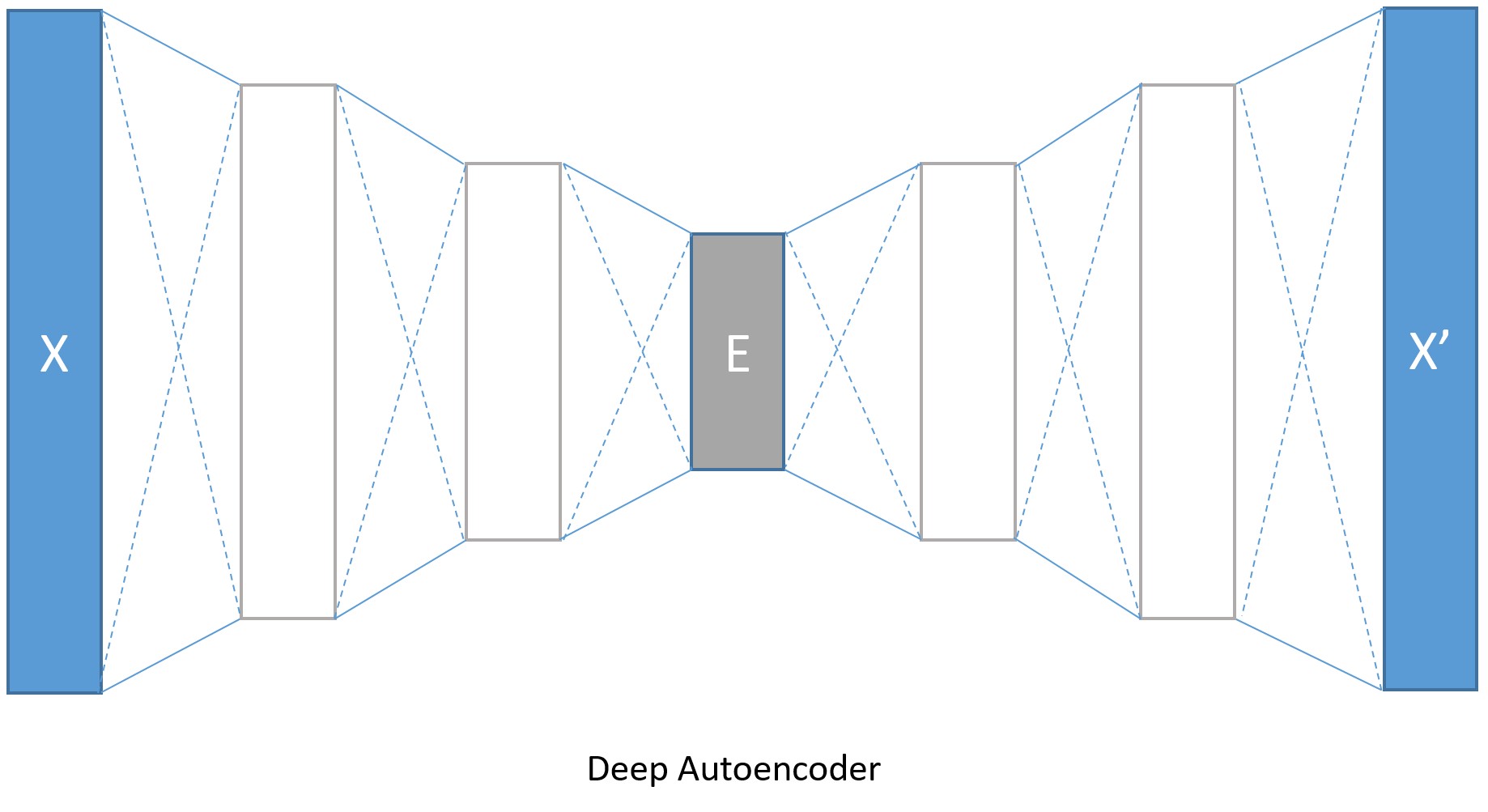
3.建立模型(Model creation):深度自動解碼器
MNIST 資料集的圖像是 28 * 28 像素,每個圖像都存在陣列中,輸入值就是 28 * 28 = 784
編碼層的大小分別是128,64,32。
解碼層就分別是64,128。
input_dim = 784
encoding_dims = [128,64,32]
decoding_dims = [64,128]
encoded_model = None
宣告函式:
def create_deep_model(features):
with C.layers.default_options(init = C.layers.glorot_uniform()):
encode = C.element_times(C.constant(1.0/255.0), features)
for encoding_dim in encoding_dims:
encode = C.layers.Dense(encoding_dim, activation = C.relu)(encode)
global encoded_model
encoded_model= encode
decode = encode
for decoding_dim in decoding_dims:
decode = C.layers.Dense(decoding_dim, activation = C.relu)(decode)
decode = C.layers.Dense(input_dim, activation = C.sigmoid)(decode)
return decode
4.訓練模型(Learning the model)
訓練模型
num_label_classes = 10
reader_train = create_reader(train_file, True, input_dim, num_label_classes)
reader_test = create_reader(test_file, False, input_dim, num_label_classes)
model, deep_ae_train_error, deep_ae_test_error = train_and_test(reader_train, reader_test, model_func = create_deep_model)


