
經過上篇簡單得介紹Register Access後,今天終於要介紹一下超級大魔王Memory Access的部分!
在整個實作當中,由於Memory Access常會被用到,因此針對這邊修改的Commit也很多,
實作方式也不斷地改變!
今天將會談到兩大主題:
進入點,很簡單,就是直接呼叫013裡的read_memory()來處理,
參考以下內容(src/target/riscv/riscv.c):
static int riscv_read_memory(struct target *target, target_addr_t address,
uint32_t size, uint32_t count, uint8_t *buffer)
{
struct target_type *tt = get_target_type(target);
return tt->read_memory(target, address, size, count, buffer);
}
然後就讓我們來觀賞一下壯觀的實作,請參考以下內容(src/target/riscv/riscv-013.c):
/**
* Read the requested memory, taking care to execute every read exactly once,
* even if cmderr=busy is encountered.
*/
static int read_memory(struct target *target, target_addr_t address,
uint32_t size, uint32_t count, uint8_t *buffer)
{
RISCV013_INFO(info);
int result = ERROR_OK;
LOG_DEBUG("reading %d words of %d bytes from 0x%" TARGET_PRIxADDR, count,
size, address);
select_dmi(target);
/* s0 holds the next address to write to
* s1 holds the next data value to write
*/
uint64_t s0, s1;
if (register_read_direct(target, &s0, GDB_REGNO_S0) != ERROR_OK)
return ERROR_FAIL;
if (register_read_direct(target, &s1, GDB_REGNO_S1) != ERROR_OK)
return ERROR_FAIL;
if (execute_fence(target) != ERROR_OK)
return ERROR_FAIL;
/* Write the program (load, increment) */
struct riscv_program program;
riscv_program_init(&program, target);
switch (size) {
case 1:
riscv_program_lbr(&program, GDB_REGNO_S1, GDB_REGNO_S0, 0);
break;
case 2:
riscv_program_lhr(&program, GDB_REGNO_S1, GDB_REGNO_S0, 0);
break;
case 4:
riscv_program_lwr(&program, GDB_REGNO_S1, GDB_REGNO_S0, 0);
break;
default:
LOG_ERROR("Unsupported size: %d", size);
return ERROR_FAIL;
}
riscv_program_addi(&program, GDB_REGNO_S0, GDB_REGNO_S0, size);
if (riscv_program_ebreak(&program) != ERROR_OK)
return ERROR_FAIL;
riscv_program_write(&program);
/* Write address to S0, and execute buffer. */
result = register_write_direct(target, GDB_REGNO_S0, address);
if (result != ERROR_OK)
goto error;
uint32_t command = access_register_command(GDB_REGNO_S1, riscv_xlen(target),
AC_ACCESS_REGISTER_TRANSFER |
AC_ACCESS_REGISTER_POSTEXEC);
result = execute_abstract_command(target, command);
if (result != ERROR_OK)
goto error;
/* First read has just triggered. Result is in s1. */
dmi_write(target, DMI_ABSTRACTAUTO,
1 << DMI_ABSTRACTAUTO_AUTOEXECDATA_OFFSET);
/* read_addr is the next address that the hart will read from, which is the
* value in s0. */
riscv_addr_t read_addr = address + size;
/* The next address that we need to receive data for. */
riscv_addr_t receive_addr = address;
riscv_addr_t fin_addr = address + (count * size);
unsigned skip = 1;
while (read_addr < fin_addr) {
LOG_DEBUG("read_addr=0x%" PRIx64 ", receive_addr=0x%" PRIx64
", fin_addr=0x%" PRIx64, read_addr, receive_addr, fin_addr);
/* The pipeline looks like this:
* memory -> s1 -> dm_data0 -> debugger
* It advances every time the debugger reads dmdata0.
* So at any time the debugger has just read mem[s0 - 3*size],
* dm_data0 contains mem[s0 - 2*size]
* s1 contains mem[s0-size] */
LOG_DEBUG("creating burst to read from 0x%" TARGET_PRIxADDR
" up to 0x%" TARGET_PRIxADDR, read_addr, fin_addr);
assert(read_addr >= address && read_addr < fin_addr);
struct riscv_batch *batch = riscv_batch_alloc(target, 32,
info->dmi_busy_delay + info->ac_busy_delay);
size_t reads = 0;
for (riscv_addr_t addr = read_addr; addr < fin_addr; addr += size) {
riscv_batch_add_dmi_read(batch, DMI_DATA0);
reads++;
if (riscv_batch_full(batch))
break;
}
riscv_batch_run(batch);
/* Wait for the target to finish performing the last abstract command,
* and update our copy of cmderr. */
uint32_t abstractcs = dmi_read(target, DMI_ABSTRACTCS);
while (get_field(abstractcs, DMI_ABSTRACTCS_BUSY))
abstractcs = dmi_read(target, DMI_ABSTRACTCS);
info->cmderr = get_field(abstractcs, DMI_ABSTRACTCS_CMDERR);
unsigned cmderr = info->cmderr;
riscv_addr_t next_read_addr;
uint32_t dmi_data0 = -1;
switch (info->cmderr) {
case CMDERR_NONE:
LOG_DEBUG("successful (partial?) memory read");
next_read_addr = read_addr + reads * size;
break;
case CMDERR_BUSY:
LOG_DEBUG("memory read resulted in busy response");
increase_ac_busy_delay(target);
riscv013_clear_abstract_error(target);
dmi_write(target, DMI_ABSTRACTAUTO, 0);
/* This is definitely a good version of the value that we
* attempted to read when we discovered that the target was
* busy. */
dmi_data0 = dmi_read(target, DMI_DATA0);
/* Clobbers DMI_DATA0. */
result = register_read_direct(target, &next_read_addr,
GDB_REGNO_S0);
if (result != ERROR_OK) {
riscv_batch_free(batch);
goto error;
}
/* Restore the command, and execute it.
* Now DMI_DATA0 contains the next value just as it would if no
* error had occurred. */
dmi_write(target, DMI_COMMAND, command);
dmi_write(target, DMI_ABSTRACTAUTO,
1 << DMI_ABSTRACTAUTO_AUTOEXECDATA_OFFSET);
break;
default:
LOG_ERROR("error when reading memory, abstractcs=0x%08lx", (long)abstractcs);
riscv013_clear_abstract_error(target);
riscv_batch_free(batch);
result = ERROR_FAIL;
goto error;
}
/* Now read whatever we got out of the batch. */
for (size_t i = 0; i < reads; i++) {
if (read_addr >= next_read_addr)
break;
read_addr += size;
if (skip > 0) {
skip--;
continue;
}
riscv_addr_t offset = receive_addr - address;
uint64_t dmi_out = riscv_batch_get_dmi_read(batch, i);
uint32_t value = get_field(dmi_out, DTM_DMI_DATA);
write_to_buf(buffer + offset, value, size);
LOG_DEBUG("M[0x%" TARGET_PRIxADDR "] reads 0x%08x", receive_addr,
value);
receive_addr += size;
}
riscv_batch_free(batch);
if (cmderr == CMDERR_BUSY) {
riscv_addr_t offset = receive_addr - address;
write_to_buf(buffer + offset, dmi_data0, size);
LOG_DEBUG("M[0x%" TARGET_PRIxADDR "] reads 0x%08x", receive_addr,
dmi_data0);
read_addr += size;
receive_addr += size;
}
}
dmi_write(target, DMI_ABSTRACTAUTO, 0);
if (count > 1) {
/* Read the penultimate word. */
uint64_t value = dmi_read(target, DMI_DATA0);
write_to_buf(buffer + receive_addr - address, value, size);
LOG_DEBUG("M[0x%" TARGET_PRIxADDR "] reads 0x%" PRIx64, receive_addr, value);
receive_addr += size;
}
/* Read the last word. */
uint64_t value;
result = register_read_direct(target, &value, GDB_REGNO_S1);
if (result != ERROR_OK)
goto error;
write_to_buf(buffer + receive_addr - address, value, size);
LOG_DEBUG("M[0x%" TARGET_PRIxADDR "] reads 0x%" PRIx64, receive_addr, value);
receive_addr += size;
riscv_set_register(target, GDB_REGNO_S0, s0);
riscv_set_register(target, GDB_REGNO_S1, s1);
return ERROR_OK;
error:
dmi_write(target, DMI_ABSTRACTAUTO, 0);
riscv_set_register(target, GDB_REGNO_S0, s0);
riscv_set_register(target, GDB_REGNO_S1, s1);
return result;
}
娘子! 快跟牛魔王出來看上帝!!
一個Memory Read竟然這麼落落長........!
不過基本上我們可以把重點流程分解如下:
大概就是這12個動作!!
除了Batch Commands會留待下面的章節另外剖析外,其餘將會一一說明!!
讓我們開始吧!!!
首先是Step 1: 備份$S0和$S1,這個簡單:
/* s0 holds the next address to write to
* s1 holds the next data value to write
*/
uint64_t s0, s1;
if (register_read_direct(target, &s0, GDB_REGNO_S0) != ERROR_OK)
return ERROR_FAIL;
if (register_read_direct(target, &s1, GDB_REGNO_S1) != ERROR_OK)
return ERROR_FAIL;
再來是Step 2. 執行fence指令,這也還好:
if (execute_fence(target) != ERROR_OK)
return ERROR_FAIL;
Step 3. 準備好Program Buffer的內容,基本上內容如下:
lw $S1, 0($S0)
addi $S0, $S0, 4
ebreak
很簡單的三道指令,基本概念如下:
實作的方式也很簡單:
/* Write the program (load, increment) */
struct riscv_program program;
riscv_program_init(&program, target);
switch (size) {
case 1:
riscv_program_lbr(&program, GDB_REGNO_S1, GDB_REGNO_S0, 0);
break;
case 2:
riscv_program_lhr(&program, GDB_REGNO_S1, GDB_REGNO_S0, 0);
break;
case 4:
riscv_program_lwr(&program, GDB_REGNO_S1, GDB_REGNO_S0, 0);
break;
default:
LOG_ERROR("Unsupported size: %d", size);
return ERROR_FAIL;
}
riscv_program_addi(&program, GDB_REGNO_S0, GDB_REGNO_S0, size);
if (riscv_program_ebreak(&program) != ERROR_OK)
return ERROR_FAIL;
riscv_program_write(&program); ///譯註: 這時候先把Program Buffer的內容寫入,但還沒有開始執行!!
再過來是Step 4. 將目標的Address寫入$S0中,這也很簡單,
簡單利用「Day 18: 深入淺出 RISC-V 源碼剖析 (3) - Register Access」介紹的方法即可:
result = register_write_direct(target, GDB_REGNO_S0, address);
if (result != ERROR_OK)
goto error;
在過來Step 5. 執行第一次Program Buffer,並將第一次的結果讀入$S1中
uint32_t command = access_register_command(GDB_REGNO_S1, riscv_xlen(target),
AC_ACCESS_REGISTER_TRANSFER |
AC_ACCESS_REGISTER_POSTEXEC);
result = execute_abstract_command(target, command);
if (result != ERROR_OK)
goto error;
還記得「Day 10: RISC-V Debug Module (下篇)-Debug Module Registers」中的這張圖嗎:
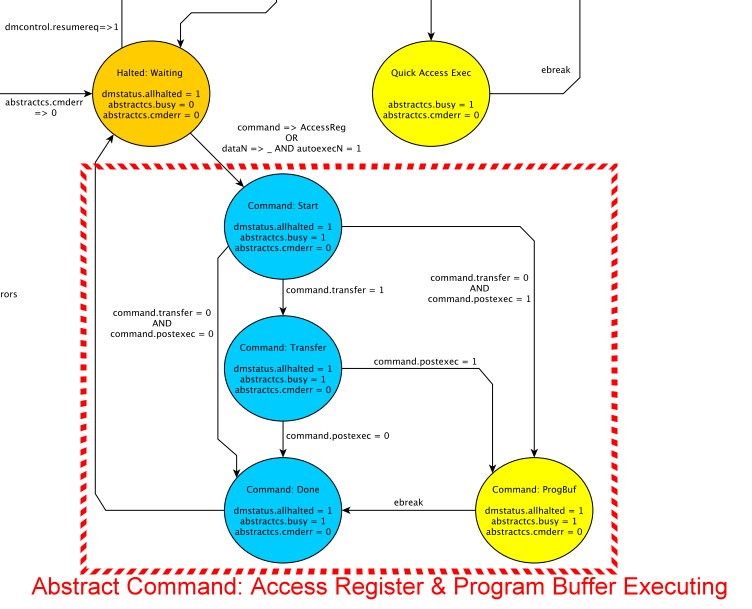
---引用自RISC-V External Debug Support 0.13
不過今天我們只看紅色括號起的地方!
當Abstrace Command中"transfer"和"postexec"同時被拉起來並執行的時候,
隱藏了一個小小的觀念在裡面:
先做Register Access之後,才會去執行Program Buffer!!!
請記住這個小小的地方,他對於接下來的Memory Access的設計有關!
不過這邊,我們其實只是要第一次執行Program Buffer而已,
所以目前$S1裡面存的值就是Mem[$S0]
再過來是Step 6. 設定Debug Module中的$abstractauto!
這邊先介紹一下$abstractauto這個Register:
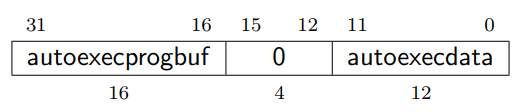
---引用自RISC-V External Debug Support 0.13
Debug Module中0x18 abstractauto,這功能是硬體可選支援的,
在這版本的實作中,皆假設這個支援存在,主要欄位有兩個:
我們在這邊主要是需要autoexecdata的功能,
當我們在讀取Debug Module中的$Data0的時候,同時硬體會自動執行一次Abstract Command!
然後讓我們繼續看下去!
再過來就是一個迴圈的部分:
/* read_addr is the next address that the hart will read from, which is the
* value in s0. */
riscv_addr_t read_addr = address + size;
/* The next address that we need to receive data for. */
riscv_addr_t receive_addr = address;
riscv_addr_t fin_addr = address + (count * size);
unsigned skip = 1;
while (read_addr < fin_addr) {
///Step 7. 建立DMI Read $Data0的Batch Commands
///Step 8. 執行Batch Commands
///Step 9. 等待執行完畢,並判斷是否成功
///Step 10. 從Batch中讀回資料
}
基本架構就是重複執行上述7~10的過程,直到讀完所需要的長度為止!
當然如果你只需要讀一道Memory(32bits)的話,那就不會進入到這個迴圈當中了!
================================= 我是分隔線 =================================
接下來介紹一下本篇最重要的部分,深入剖析Memory Access的原理!
試想一個狀況,假如我今天希望能夠讀取完一到32bits的Memory之後,
讓硬體自動幫我更新資料,讀取下一位置的Memory,我應該怎麼做!!?
我有的資源如下:
讀到這邊,讓讀者想一下,這邊應該要怎麼設計!?
================================= 我是分隔線 =================================
來公布答案吧!
就是一直不段的讀取$Data0,讓autoexecdata的機制自動執行Abstract Command一次,
在執行Abstract Command的時候,會先將$S1的內容存到$Data0後,再去執行Program Buffer一次,讓Program Buffer裡面的指令,將存Mem[$S0]到$S1中,並自動更新$S0到下一個位置!!
有沒有突然覺得這個機制設計得很神啊!!!!!!!!!!!!!一起加入Debugger的世界吧!
整個Pipeline看起來如下:
| $S1 | → | DM中 $Data0 | → | Debugger 讀取到的值 | 說明 |
|---|---|---|---|---|---|
| Mem[0] | X | X | 剛開始執行batch之前 | ||
| Mem[4] | Mem[0] | X | DMI Read 1 | ||
| Mem[8] | Mem[4] | Mem[0] | DMI Read 2 | ||
| Mem[12] | Mem[8] | Mem[4] | DMI Read 3 | ||
| Mem[16] | Mem[12] | Mem[8] | DMI Read 4 | ||
| ... | Mem[16] | Mem[12] | DMI Read 5 | ||
| ... | ... | Mem[16] | DMI Read 6 | ||
| ... | ... | ... | ... |
大概就是程式碼中註解那部分的意思:
/* The pipeline looks like this:
* memory -> s1 -> dm_data0 -> debugger
* It advances every time the debugger reads dmdata0.
* So at any time the debugger has just read mem[s0 - 3*size],
* dm_data0 contains mem[s0 - 2*size]
* s1 contains mem[s0-size] */
基本的概念大概就是這樣!!!
所以Step 7. 建立DMI Read $Data0的Batch Commands和Step 8. 執行Batch Commands的實作如下:
///譯註: 先建立一個Batch Commands存放的空間
struct riscv_batch *batch = riscv_batch_alloc(target, 32,
info->dmi_busy_delay + info->ac_busy_delay);
size_t reads = 0;
for (riscv_addr_t addr = read_addr; addr < fin_addr; addr += size) {
///譯註: 寫入讀取DM中$Data0的指令,直到空間滿了為止!
riscv_batch_add_dmi_read(batch, DMI_DATA0);
reads++;
if (riscv_batch_full(batch))
break;
}
///譯註: 執行Batch Commands
riscv_batch_run(batch);
然後記得要去檢查Abstract Command執行的狀況!
Step 9. 等待執行完畢,並判斷是否成功:
unsigned cmderr = info->cmderr;
riscv_addr_t next_read_addr;
uint32_t dmi_data0 = -1;
switch (info->cmderr) {
case CMDERR_NONE:
LOG_DEBUG("successful (partial?) memory read");
next_read_addr = read_addr + reads * size;
break;
case CMDERR_BUSY:
中間略過...
default:
LOG_ERROR("error when reading memory, abstractcs=0x%08lx", (long)abstractcs);
riscv013_clear_abstract_error(target);
riscv_batch_free(batch);
result = ERROR_FAIL;
goto error;
}
最後是Step 10. 從Batch中讀回資料:
/* Now read whatever we got out of the batch. */
for (size_t i = 0; i < reads; i++) {
if (read_addr >= next_read_addr)
break;
read_addr += size;
if (skip > 0) {
skip--;
continue;
}
riscv_addr_t offset = receive_addr - address;
uint64_t dmi_out = riscv_batch_get_dmi_read(batch, i);
uint32_t value = get_field(dmi_out, DTM_DMI_DATA);
write_to_buf(buffer + offset, value, size);
LOG_DEBUG("M[0x%" TARGET_PRIxADDR "] reads 0x%08x", receive_addr,
value);
receive_addr += size;
}
///譯註: 清空Batch
riscv_batch_free(batch);
到這邊基本上Memory Access的概念都已經剖析完畢!
至於Write Memory的部分也是類似啦!
直接放在附錄的部分給大家參考!
好經過上面的剖析之後,只剩下一個重點還沒有說明!?
就是什麼是Batch Commands啦!?
說他是整個Memory Access的核心也不為過!
基本的概念如下:
所以假設field[0].out裡面放的是DMI_READ1(第一次Read DMI $Data0),等到寫入field[1].out = NOP的時候,同時field[1].in就會是field[0].out處理後的結果!
別忘記了在OpenOCD JTAG設計中,out指的是從OpenOCD到達(out)Target端,in指的是OpenOCD從Target端得到(in)的值
整個Pipeline大概長這樣:
| Debugger寫入(out)的值 | DTM中的$dmi | Debugger得到(in)的值 | ||
|---|---|---|---|---|
| field[0].out = DMI_READ1 | X | X | ||
| field[1].out = NOP | → | field[1].in = DMI_READ 1 | ||
| field[2].out = DMI_READ2 | X | X | ||
| field[3].out = NOP | → | field[1].in = DMI_READ2 | ||
| ... | ... | ... | ||
忘記JTAG的操作可以參考這邊: 小蘿蔔工作室 Little Robot Studio - JTAG
先看程式碼的部分,請參考以下內容(src/target/riscv/riscv-013.c):
size_t riscv_batch_add_dmi_read(struct riscv_batch *batch, unsigned address)
{
assert(batch->used_scans < batch->allocated_scans);
struct scan_field *field = batch->fields + batch->used_scans;
field->num_bits = riscv_dmi_write_u64_bits(batch->target);
field->out_value = (void *)(batch->data_out + batch->used_scans * sizeof(uint64_t));
field->in_value = (void *)(batch->data_in + batch->used_scans * sizeof(uint64_t));
riscv_fill_dmi_read_u64(batch->target, (char *)field->out_value, address);
riscv_fill_dmi_nop_u64(batch->target, (char *)field->in_value);
batch->last_scan = RISCV_SCAN_TYPE_READ;
batch->used_scans++;
/* FIXME We get the read response back on the next scan. For now I'm
* just sticking a NOP in there, but this should be coelesced away. */
///譯註: 加個NOP在後方!
riscv_batch_add_nop(batch);
///譯註: 這邊只是設定一下這個filed出去後的結果,會在下面一道NOP的in_value中!
batch->read_keys[batch->read_keys_used] = batch->used_scans - 1;
LOG_DEBUG("read key %u for batch 0x%p is %u (0x%p)",
(unsigned) batch->read_keys_used, batch, (unsigned) (batch->used_scans - 1),
batch->data_in + sizeof(uint64_t) * (batch->used_scans + 1));
return batch->read_keys_used++;
}
基本上就是把要送到Target端的資料(out_value)給放好,至於in_value的部分就不是很重要了,可以直接放個NOP
然後比較重要的是在下一道的地方給放上一個NOP:
riscv_batch_add_nop(batch);
幾本上riscv_batch_add_nop()做的事情也差不多,請參考以下內容(src/target/riscv/riscv-013.c):
void riscv_batch_add_nop(struct riscv_batch *batch)
{
assert(batch->used_scans < batch->allocated_scans);
struct scan_field *field = batch->fields + batch->used_scans;
field->num_bits = riscv_dmi_write_u64_bits(batch->target);
field->out_value = (void *)(batch->data_out + batch->used_scans * sizeof(uint64_t));
field->in_value = (void *)(batch->data_in + batch->used_scans * sizeof(uint64_t));
riscv_fill_dmi_nop_u64(batch->target, (char *)field->out_value);
riscv_fill_dmi_nop_u64(batch->target, (char *)field->in_value);
batch->last_scan = RISCV_SCAN_TYPE_NOP;
batch->used_scans++;
LOG_DEBUG(" added NOP with in_value=0x%p", field->in_value);
}
就是在送給Target端的資料裡面放上NOP!
基本上就是把對應欄位的資料給讀出來,請參考以下內容(src/target/riscv/riscv-013.c):
uint64_t riscv_batch_get_dmi_read(struct riscv_batch *batch, size_t key)
{
assert(key < batch->read_keys_used);
size_t index = batch->read_keys[key];
assert(index <= batch->used_scans);
uint8_t *base = batch->data_in + 8 * index;
return base[0] |
((uint64_t) base[1]) << 8 |
((uint64_t) base[2]) << 16 |
((uint64_t) base[3]) << 24 |
((uint64_t) base[4]) << 32 |
((uint64_t) base[5]) << 40 |
((uint64_t) base[6]) << 48 |
((uint64_t) base[7]) << 56;
}
從發想到設計出來,真心覺得要對JTAG運作非常熟悉的人才可以設計出來的方式!
佩服佩服!!
今天一樣是把程式碼塞好、塞滿!
單純放在這邊 程式碼塞好塞滿!
請參考以下內容(src/target/riscv/riscv-013.c):
static int write_memory(struct target *target, target_addr_t address,
uint32_t size, uint32_t count, const uint8_t *buffer)
{
RISCV013_INFO(info);
LOG_DEBUG("writing %d words of %d bytes to 0x%08lx", count, size, (long)address);
select_dmi(target);
/* s0 holds the next address to write to
* s1 holds the next data value to write
*/
int result = ERROR_OK;
uint64_t s0, s1;
if (register_read_direct(target, &s0, GDB_REGNO_S0) != ERROR_OK)
return ERROR_FAIL;
if (register_read_direct(target, &s1, GDB_REGNO_S1) != ERROR_OK)
return ERROR_FAIL;
/* Write the program (store, increment) */
struct riscv_program program;
riscv_program_init(&program, target);
switch (size) {
case 1:
riscv_program_sbr(&program, GDB_REGNO_S1, GDB_REGNO_S0, 0);
break;
case 2:
riscv_program_shr(&program, GDB_REGNO_S1, GDB_REGNO_S0, 0);
break;
case 4:
riscv_program_swr(&program, GDB_REGNO_S1, GDB_REGNO_S0, 0);
break;
default:
LOG_ERROR("Unsupported size: %d", size);
result = ERROR_FAIL;
goto error;
}
riscv_program_addi(&program, GDB_REGNO_S0, GDB_REGNO_S0, size);
result = riscv_program_ebreak(&program);
if (result != ERROR_OK)
goto error;
riscv_program_write(&program);
riscv_addr_t cur_addr = address;
riscv_addr_t fin_addr = address + (count * size);
bool setup_needed = true;
LOG_DEBUG("writing until final address 0x%016" PRIx64, fin_addr);
while (cur_addr < fin_addr) {
LOG_DEBUG("transferring burst starting at address 0x%016" PRIx64,
cur_addr);
struct riscv_batch *batch = riscv_batch_alloc(
target,
32,
info->dmi_busy_delay + info->ac_busy_delay);
/* To write another word, we put it in S1 and execute the program. */
unsigned start = (cur_addr - address) / size;
for (unsigned i = start; i < count; ++i) {
unsigned offset = size*i;
const uint8_t *t_buffer = buffer + offset;
uint32_t value;
switch (size) {
case 1:
value = t_buffer[0];
break;
case 2:
value = t_buffer[0]
| ((uint32_t) t_buffer[1] << 8);
break;
case 4:
value = t_buffer[0]
| ((uint32_t) t_buffer[1] << 8)
| ((uint32_t) t_buffer[2] << 16)
| ((uint32_t) t_buffer[3] << 24);
break;
default:
LOG_ERROR("unsupported access size: %d", size);
riscv_batch_free(batch);
result = ERROR_FAIL;
goto error;
}
LOG_DEBUG("M[0x%08" PRIx64 "] writes 0x%08x", address + offset, value);
cur_addr += size;
if (setup_needed) {
result = register_write_direct(target, GDB_REGNO_S0,
address + offset);
if (result != ERROR_OK) {
riscv_batch_free(batch);
goto error;
}
/* Write value. */
dmi_write(target, DMI_DATA0, value);
/* Write and execute command that moves value into S1 and
* executes program buffer. */
uint32_t command = access_register_command(GDB_REGNO_S1, 32,
AC_ACCESS_REGISTER_POSTEXEC |
AC_ACCESS_REGISTER_TRANSFER |
AC_ACCESS_REGISTER_WRITE);
result = execute_abstract_command(target, command);
if (result != ERROR_OK) {
riscv_batch_free(batch);
goto error;
}
/* Turn on autoexec */
dmi_write(target, DMI_ABSTRACTAUTO,
1 << DMI_ABSTRACTAUTO_AUTOEXECDATA_OFFSET);
setup_needed = false;
} else {
riscv_batch_add_dmi_write(batch, DMI_DATA0, value);
if (riscv_batch_full(batch))
break;
}
}
result = riscv_batch_run(batch);
riscv_batch_free(batch);
if (result != ERROR_OK)
goto error;
/* Note that if the scan resulted in a Busy DMI response, it
* is this read to abstractcs that will cause the dmi_busy_delay
* to be incremented if necessary. */
uint32_t abstractcs = dmi_read(target, DMI_ABSTRACTCS);
while (get_field(abstractcs, DMI_ABSTRACTCS_BUSY))
abstractcs = dmi_read(target, DMI_ABSTRACTCS);
info->cmderr = get_field(abstractcs, DMI_ABSTRACTCS_CMDERR);
switch (info->cmderr) {
case CMDERR_NONE:
LOG_DEBUG("successful (partial?) memory write");
break;
case CMDERR_BUSY:
LOG_DEBUG("memory write resulted in busy response");
riscv013_clear_abstract_error(target);
increase_ac_busy_delay(target);
dmi_write(target, DMI_ABSTRACTAUTO, 0);
result = register_read_direct(target, &cur_addr, GDB_REGNO_S0);
if (result != ERROR_OK)
goto error;
setup_needed = true;
break;
default:
LOG_ERROR("error when writing memory, abstractcs=0x%08lx", (long)abstractcs);
riscv013_clear_abstract_error(target);
result = ERROR_FAIL;
goto error;
}
}
error:
dmi_write(target, DMI_ABSTRACTAUTO, 0);
if (register_write_direct(target, GDB_REGNO_S1, s1) != ERROR_OK)
return ERROR_FAIL;
if (register_write_direct(target, GDB_REGNO_S0, s0) != ERROR_OK)
return ERROR_FAIL;
if (execute_fence(target) != ERROR_OK)
return ERROR_FAIL;
return result;
}

