接下來我們將建立一個歌曲推薦系統
一樣的要載入資料庫,同時可以稍微看一下資料庫裡面的內容包含了使用者ID與歌曲ID,這個人聽過這首歌幾次,專輯、歌曲及歌手名稱
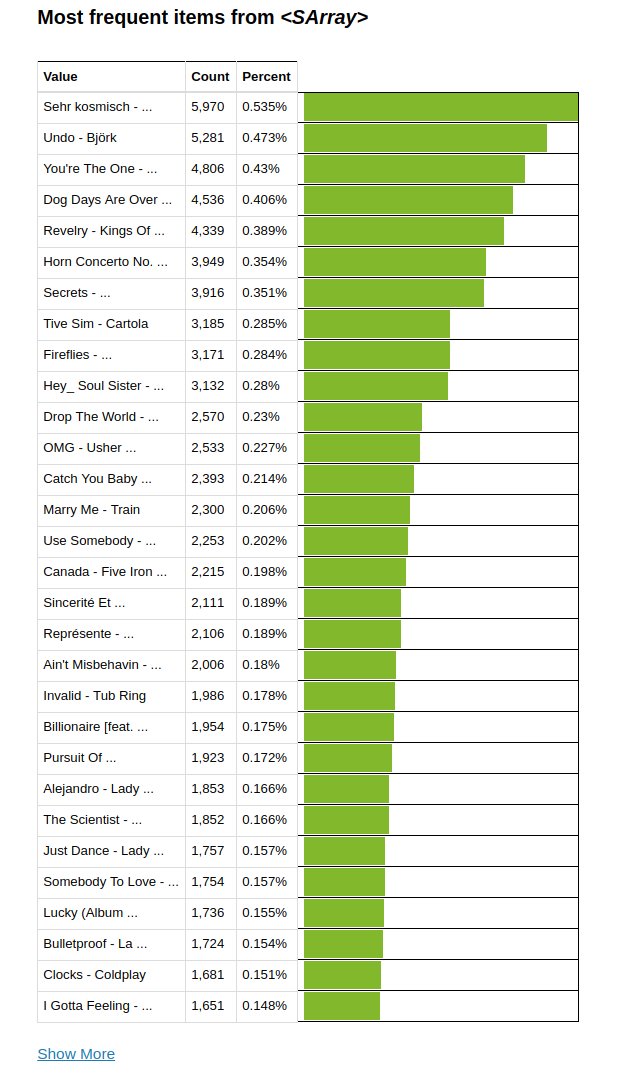
這個表格裡面展示了每個聽每一首歌的頻率
# Building a song recommender Fire up GraphLab Create
import graphlab
# Load music data
song_data = graphlab.SFrame('song_data.gl/')
# Explore data
song_data.head()
| user_id | song_id | listen_count | title | artist | song |
|---|---|---|---|---|---|
| b80344d063b5ccb3212f76538f3d9e43d87dca9e ... | SOAKIMP12A8C130995 | 1 | The Cove | Jack Johnson | The Cove - Jack Johnson |
| b80344d063b5ccb3212f76538f3d9e43d87dca9e ... | SOBBMDR12A8C13253B | 2 | Entre Dos Aguas | Paco De Lucia | Entre Dos Aguas - Paco DeLucia ... |
| b80344d063b5ccb3212f76538f3d9e43d87dca9e ... | SOBXHDL12A81C204C0 | 1 | Stronger | Kanye West | Stronger - Kanye West |
| b80344d063b5ccb3212f76538f3d9e43d87dca9e ... | SOBYHAJ12A6701BF1D | 1 | Constellations | Jack Johnson | Constellations - JackJohnson ... |
| b80344d063b5ccb3212f76538f3d9e43d87dca9e ... | SODACBL12A8C13C273 | 1 | Learn To Fly | Foo Fighters | Learn To Fly - FooFighters ... |
| b80344d063b5ccb3212f76538f3d9e43d87dca9e ... | SODDNQT12A6D4F5F7E | 5 | Apuesta Por El Rock 'N'Roll ... | Héroes del Silencio | Apuesta Por El Rock 'N'Roll - Héroes del ... |
| b80344d063b5ccb3212f76538f3d9e43d87dca9e ... | SODXRTY12AB0180F3B | 1 | Paper Gangsta | Lady GaGa | Paper Gangsta - Lady GaGa |
| b80344d063b5ccb3212f76538f3d9e43d87dca9e ... | SOFGUAY12AB017B0A8 | 1 | Stacked Actors | Foo Fighters | Stacked Actors - FooFighters ... |
| b80344d063b5ccb3212f76538f3d9e43d87dca9e ... | SOFRQTD12A81C233C0 | 1 | Sehr kosmisch | Harmonia | Sehr kosmisch - Harmonia |
| b80344d063b5ccb3212f76538f3d9e43d87dca9e ... | SOHQWYZ12A6D4FA701 | 1 | Heaven's gonna burn youreyes ... | Thievery Corporationfeat. Emiliana Torrini ... | Heaven's gonna burn youreyes - Thievery ... |
接著我想對我的資料有一些初步的了解,比如那首歌被播放最多次又或者資料庫裡面究竟有幾首歌,不僅如此也想知道究竟使用者的數量有多少
# Showing the most popular songs in the dataset
song_data['song'].show()
len(song_data)
# 1116609
# Count number of unique users in the dataset
users = song_data['user_id'].unique()
len(users)
# 66346
有了這些資料之後,接著就是建立歌曲推薦系統
按照慣例,我們必須給定測試集與訓練集
# train set 80% test set 20%
train_data,test_data = song_data.random_split(.8,seed=0)
有了這些之後我們就可以開始做機器學習了,先從課程中的第一個方法來做學習(基於流行程度)
這是一個非常常見的範例,比如前面一開始提到的上報的熱門新聞欄位
# Simple popularity-based recommender
popularity_model = graphlab.popularity_recommender.create(train_data,
user_id='user_id',
item_id='song')
# Use the popularity model to make some predictions
# popularity_model.recommend(users=[users[0...66343]])
popularity_model.recommend(users=[users[0]])
popularity_model.recommend(users=[users[1]])
最後,從基於流行度的模型得到推薦結果你會發現,不管你要推薦給那一個使用者,結果都會是一樣的
| user_id | song | score | rank |
|---|---|---|---|
| 279292bb36dbfc7f505e36ebf038c81eb1d1d63e ... | Sehr kosmisch - Harmonia | 4754.0 | 1 |
| 279292bb36dbfc7f505e36ebf038c81eb1d1d63e ... | Undo - Björk | 4227.0 | 2 |
| 279292bb36dbfc7f505e36ebf038c81eb1d1d63e ... | You're The One - DwightYoakam ... | 3781.0 | 3 |
| 279292bb36dbfc7f505e36ebf038c81eb1d1d63e ... | Dog Days Are Over (RadioEdit) - Florence + The ... | 3633.0 | 4 |
| 279292bb36dbfc7f505e36ebf038c81eb1d1d63e ... | Revelry - Kings Of Leon | 3527.0 | 5 |
| 279292bb36dbfc7f505e36ebf038c81eb1d1d63e ... | Horn Concerto No. 4 in Eflat K495: II. Romance ... | 3161.0 | 6 |
| 279292bb36dbfc7f505e36ebf038c81eb1d1d63e ... | Secrets - OneRepublic | 3148.0 | 7 |
接下來我們想要讓模型更 personalization 一些
# Build a song recommender with personalization
personalized_model = graphlab.item_similarity_recommender.create(train_data, user_id='user_id',
item_id='song')
# Applying the personalized model to make song recommendations
personalized_model.recommend(users=[users[0]])
personalized_model.recommend(users=[users[1]])
這次你將得到兩個不同的結果
| user_id | song | score | rank |
|---|---|---|---|
| 279292bb36dbfc7f505e36ebf038c81eb1d1d63e ... | Riot In Cell Block NumberNine - Dr Feelgood ... | 0.0374999940395 | 1 |
| 279292bb36dbfc7f505e36ebf038c81eb1d1d63e ... | Sei Lá Mangueira -Elizeth Cardoso ... | 0.0331632643938 | 2 |
| 279292bb36dbfc7f505e36ebf038c81eb1d1d63e ... | The Stallion - Ween | 0.0322580635548 | 3 |
| 279292bb36dbfc7f505e36ebf038c81eb1d1d63e ... | Rain - Subhumans | 0.0314159244299 | 4 |
| 279292bb36dbfc7f505e36ebf038c81eb1d1d63e ... | West One (Shine On Me) -The Ruts ... | 0.0306771993637 | 5 |
| 279292bb36dbfc7f505e36ebf038c81eb1d1d63e ... | Back Against The Wall -Cage The Elephant ... | 0.0301204770803 | 6 |
| user_id | song | score | rank |
|---|---|---|---|
| c067c22072a17d33310d7223d7b79f819e48cf42 ... | Grind With Me (ExplicitVersion) - Pretty Ricky ... | 0.0459424376488 | 1 |
| c067c22072a17d33310d7223d7b79f819e48cf42 ... | There Goes My Baby -Usher ... | 0.0331920742989 | 2 |
| c067c22072a17d33310d7223d7b79f819e48cf42 ... | Panty Droppa [Intro](Album Version) - Trey ... | 0.0318566203117 | 3 |
| c067c22072a17d33310d7223d7b79f819e48cf42 ... | Nobody (Featuring AthenaCage) (LP Version) - ... | 0.0278467655182 | 4 |
| c067c22072a17d33310d7223d7b79f819e48cf42 ... | Youth Against Fascism -Sonic Youth ... | 0.0262914180756 | 5 |
| c067c22072a17d33310d7223d7b79f819e48cf42 ... | Nice & Slow - Usher | 0.0239639401436 | 6 |
personalized 後你將可以做更多的事情,我們也可以以歌曲為基準,找出與其相似的,理論上它會被同一群人所接受
# We can also apply the model to find similar songs to any song in the dataset
personalized_model.get_similar_items(['With Or Without You - U2'])
personalized_model.get_similar_items(['Chan Chan (Live) - Buena Vista Social Club'])
| song | similar | score | rank |
|---|---|---|---|
| With Or Without You - U2 | I Still Haven't FoundWhat I'm Looking For ... | 0.042857170105 | 1 |
| With Or Without You - U2 | Hold Me_ Thrill Me_ KissMe_ Kill Me - U2 ... | 0.0337349176407 | 2 |
| With Or Without You - U2 | Window In The Skies - U2 | 0.0328358411789 | 3 |
| With Or Without You - U2 | Vertigo - U2 | 0.0300751924515 | 4 |
| With Or Without You - U2 | Sunday Bloody Sunday - U2 | 0.0271317958832 | 5 |
| With Or Without You - U2 | Bad - U2 | 0.0251798629761 | 6 |
# We can also apply the model to find similar songs to any song in the dataset
personalized_model.get_similar_items(['Chan Chan (Live) - Buena Vista Social Club'])
| song | similar | score | rank |
|---|---|---|---|
| Chan Chan (Live) - BuenaVista Social Club ... | Murmullo - Buena VistaSocial Club ... | 0.188118815422 | 1 |
| Chan Chan (Live) - BuenaVista Social Club ... | La Bayamesa - Buena VistaSocial Club ... | 0.18719214201 | 2 |
| Chan Chan (Live) - BuenaVista Social Club ... | Amor de Loca Juventud -Buena Vista Social Club ... | 0.184834122658 | 3 |
| Chan Chan (Live) - BuenaVista Social Club ... | Diferente - Gotan Project | 0.0214592218399 | 4 |
| Chan Chan (Live) - BuenaVista Social Club ... | Mistica - Orishas | 0.0205761194229 | 5 |
| Chan Chan (Live) - BuenaVista Social Club ... | Hotel California - GipsyKings ... | 0.0193049907684 | 6 |
接著我們就可以透過 precision-recall 來比較兩個模型的優劣了
# Quantitative comparison between the models
model_performance = graphlab.recommender.util.compare_models(test_data, [popularity_model, personalized_model], user_sample=.05)
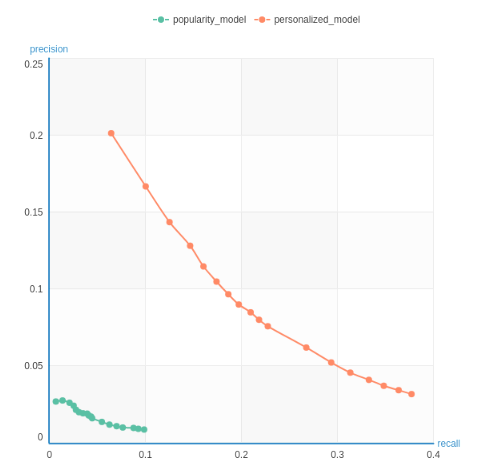
從結果來看,誰是相對好的模型顯而易見,也符合我們預期的結果


