在這門課裡面提到了許多不同的機器學習方法以及其可能的應用,但這堂課還是留下一些問題,所以接下來就是要談談這些挑戰
其中一個就是,我們往往被迫在許多模型中做出選擇
當我們提到推薦系統,會使用分類模型,我們提取使用者和商品的特徵放到 classifier ,然後判斷使用者是否喜歡這個商品,在那之後我們學到 matrix factorization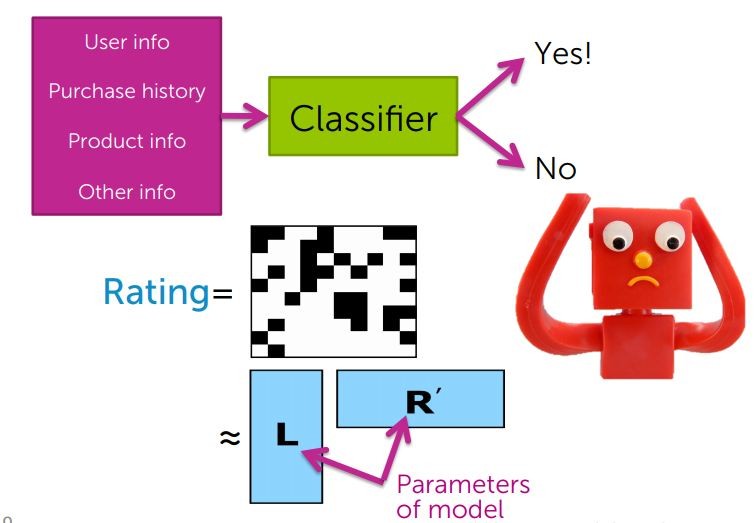
如果我們想把潛在模型全部列出來,那將是一件浩大的工程,而且對實施者也非常複雜
太多模型可以選擇,我們到底該選擇那一個?模型的選擇仍舊是這個領域極大的挑戰(2015的結論)
另一個挑戰是,我們要如何呈現我們的資料
在先前的 document retrieval 我們使用了簡單的字數統計、normalize 向量、 tf-idf 來計算我們較普遍使用的詞,然後強調它在文件中的重要性
事實上 tf-idf 有許多變種,在這裡僅僅提供一些例子,你可以用到 Bigrams、Trigrams...等,來表示在文件中出現的用詞
你可能不只會有文件,有可能面臨到圖片或其他擁有相對複雜結構的資料,因此我們如何呈現資料會對資料如何判斷有著重要影響(Good vs Not good)
另一個重要的挑戰是機器學習如何處理多維度問題?事實上資料變得越來越多,我們可以想一下我們可能碰到的情形
隨著資料量的增加,我們有不同的網路社交平台,從更廣泛的管道取得資料,比如你在臉書上對某間餐廳的評價或者在亞馬遜上的商品評價...
比那些還要更多的還有,現在有了穿戴式裝置,一個能監控我做什麼活動、睡著了沒?
資料只會越來越多,我們可以從中知道,一個人的客觀身體素質、購買習慣、交友圈、閱讀喜好....
我們需要新的方法來分析這些資料,並對某種有特殊結構的資料進行分析
最後還有 Big data 該如何處理?
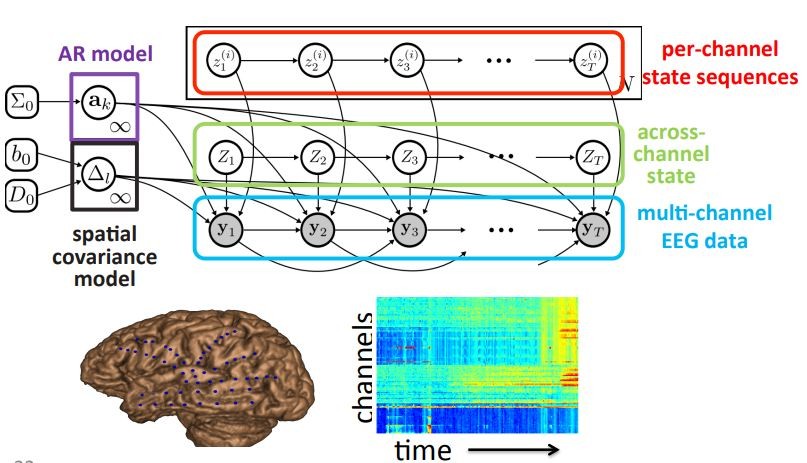
當資料變得非常大時,我們會面臨到越來越複雜的資料,不只如此模型本身也會變得肥大,這樣才能夠因應那些資料提取想要的訊息,就像之前 clustering 中提到的紀錄大腦的活動
當面臨這些問題時其實還好,因為硬體會越來越好,舉例來說我們可以看到處理的效能呈現指數型的增加
但是這種增長在十年前就停止了,我們可以看到處理器的速度呈現緩慢遞減的現象,因此我們必須思考替代方案,比較典型的方式是多核心
但緊接著的是我們要如何運用在機器學習上,最基本的兩個難題就是


