Introduction
增強式學習(Reinforcement learnin, RL)是一種專注於在相同的初始環境下擬定策略進行行動選擇(action selection),取得反饋後重新評估先前決策並調整,以最大化累積獎勵的機器學習方法。
機器學習中會使用
軟體代理人(Software agent),利用動態規劃(Dynamic programming, DP)方法進行演算,又稱為馬可夫決策過程(Markov Decision Processes, MDPs)。
OpenAI'S gym
OpenAI's gym是一個模擬器,支援如雅達利(Atari)等平台環境,是學習開發和比較增強式學習的常用工具。
這裡使用[經典控制(Classic control]模擬器,並使用其中的 木棒台車平衡問題(CartPole)遊戲,來訓練增強式學習。
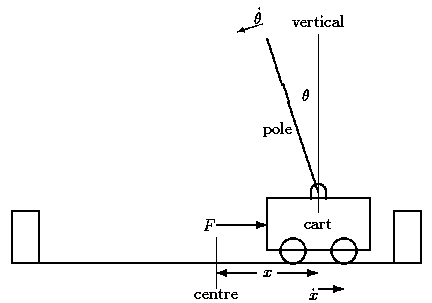
遊戲的目標,是防止在車移動的時候,豎桿從垂直狀態倒下。
也就是說,豎桿(pole)垂直(vertical)的角度小於 15 度及車(cart)在畫面中央(centre) 2.4 的距離單位以內,就會得分。
深度 Q 網路(Deep Q-Networks, DQN)是 [Deep Mind] 的論文使用深度增強式學習玩雅達利遊戲(Playing Atari with Deep Reinforcement Learning)提出的,訓練神經網路來取得學習成果 Q 值,並從所有 Q 值中選擇出最好的。
這種動態規劃方法又稱為貝爾曼方程(Bellman Equation)。
s:給定狀態
a:動作選擇
r:目前得分
s':動作後的反饋狀態
策略梯度(Policy gradient)使用梯度(gradient)方法評估策略動作,透過隨機選擇一些動作 a 集合,來訓練得到一個可以讓得分最大化的動作集合。
Tasks
物件引用。
from __future__ import print_function
from __future__ import division
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
import pandas as pd
import seaborn as sns
style.use('ggplot')
%matplotlib inline
安裝模擬器環境。
try:
import gym
except:
!pip install gym
import gym
選擇運行模式。
isFast = True
3.建立模型(Model creation):
STATE_COUNT:4 種狀態,遊戲開始、得分、未得分、遊戲結束。
ACTION_COUNT:2 種動作,左、右。
env = gym.make('CartPole-v0')
# STATE_COUNT = 4
STATE_COUNT = env.observation_space.shape[0]
# ACTION_COUNT = 2
ACTION_COUNT = env.action_space.n
STATE_COUNT, ACTION_COUNT
設定變數。
# 目標得分數
REWARD_TARGET = 30 if isFast else 200
# 批次處理資料集大小
BATCH_SIZE_BASELINE = 20 if isFast else 50
# 隱藏層層數
H = 64
宣告類別:Brain 模型訓練。
class Brain:
def __init__(self):
self.params = {}
self.model, self.trainer, self.loss = self._create()
# self.model.load_weights("cartpole-basic.h5")
def _create(self):
observation = C.sequence.input_variable(STATE_COUNT, np.float32, name="s")
q_target = C.sequence.input_variable(ACTION_COUNT, np.float32, name="q")
# 全連接層,激活函式使用 relu
l1 = C.layers.Dense(H, activation=C.relu)
l2 = C.layers.Dense(ACTION_COUNT)
unbound_model = C.layers.Sequential([l1, l2])
model = unbound_model(observation)
self.params = dict(W1=l1.W, b1=l1.b, W2=l2.W, b2=l2.b)
# 損失函數為均方差(mean squared error, MSE)
loss = C.reduce_mean(C.square(model - q_target), axis=0)
meas = C.reduce_mean(C.square(model - q_target), axis=0)
# 最佳化
lr = 0.00025
lr_schedule = C.learning_parameter_schedule(lr)
learner = C.sgd(model.parameters, lr_schedule, gradient_clipping_threshold_per_sample=10)
trainer = C.Trainer(model, (loss, meas), learner)
# 傳回訓練結果
return model, trainer, loss
def train(self, x, y, epoch=1, verbose=0):
arguments = dict(zip(self.loss.arguments, [x,y]))
updated, results =self.trainer.train_minibatch(arguments, outputs=[self.loss.output])
def predict(self, s):
return self.model.eval([s])
宣告類別:Memory 用以儲存狀態 s、動作 a、得分 r、狀態 s_。
class Memory:
samples = []
def __init__(self, capacity):
self.capacity = capacity
def add(self, sample):
self.samples.append(sample)
if len(self.samples) > self.capacity:
self.samples.pop(0)
def sample(self, n):
n = min(n, len(self.samples))
return random.sample(self.samples, n)
設定變數。
MEMORY_CAPACITY = 100000
BATCH_SIZE = 64
# 折扣率
GAMMA = 0.99
MAX_EPSILON = 1
MIN_EPSILON = 0.01
# 衰減速度
LAMBDA = 0.0001
宣告類別:Agent 代理人,模擬人類操作動作的程式片段。
class Agent:
steps = 0
epsilon = MAX_EPSILON
def __init__(self):
self.brain = Brain()
self.memory = Memory(MEMORY_CAPACITY)
def act(self, s):
if random.random() < self.epsilon:
return random.randint(0, ACTION_COUNT-1)
else:
return numpy.argmax(self.brain.predict(s))
def observe(self, sample): # in (s, a, r, s_) format
self.memory.add(sample)
# 緩慢減少
self.steps += 1
self.epsilon = MIN_EPSILON + (MAX_EPSILON - MIN_EPSILON) * math.exp(-LAMBDA * self.steps)
def replay(self):
batch = self.memory.sample(BATCH_SIZE)
batchLen = len(batch)
no_state = numpy.zeros(STATE_COUNT)
states = numpy.array([ o[0] for o in batch ], dtype=np.float32)
states_ = numpy.array([(no_state if o[3] is None else o[3]) for o in batch ], dtype=np.float32)
p = agent.brain.predict(states)
p_ = agent.brain.predict(states_)
x = numpy.zeros((batchLen, STATE_COUNT)).astype(np.float32)
y = numpy.zeros((batchLen, ACTION_COUNT)).astype(np.float32)
for i in range(batchLen):
s, a, r, s_ = batch[i]
t = p[0][i]
if s_ is None:
t[a] = r
else:
t[a] = r + GAMMA * numpy.amax(p_[0][i])
x[i] = s
y[i] = t
self.brain.train(x, y)
4.訓練模型(Learning the model):
宣告函式:迭代訓練評估,取得最佳動作 a 集合,以獲得最佳得分。
def plot_weights(weights, figsize=(7,5)):
sns.set(style="white")
f, ax = plt.subplots(len(weights), figsize=figsize)
cmap = sns.diverging_palette(220, 10, as_cmap=True)
for i, data in enumerate(weights):
axi = ax if len(weights)==1 else ax[i]
if isinstance(data, tuple):
w, title = data
axi.set_title(title)
else:
w = data
sns.heatmap(w.asarray(), cmap=cmap, square=True, center=True, #annot=True,
linewidths=.5, cbar_kws={"shrink": .25}, ax=axi)
宣告函式:epsilon
訓練初始時盡量嘗試所有可能的動作,嘗試所有可能動作,將 epsilon 最大化 MAX_EPSILON。
當取得可得分的動作集合越來越多,減少動作範圍,將 epsilon 接近最小化 MIN_EPSILON。
def epsilon(steps):
return MIN_EPSILON + (MAX_EPSILON - MIN_EPSILON) * np.exp(-LAMBDA * steps)
資料視覺化。
plt.plot(range(10000), [epsilon(x) for x in range(10000)], 'r')
plt.xlabel('step');plt.ylabel('$\epsilon$')
設定變數:總共執行幾回合後結束。
TOTAL_EPISODES = 2000 if isFast else 3000
宣告函式:開始訓練。
def run(agent):
s = env.reset()
R = 0
while True:
# 訓練過程會將遊戲動作畫面過程儲存為 mp4 檔案
# 顯示訓練過程
# env.render()
a = agent.act(s.astype(np.float32))
s_, r, done, info = env.step(a)
# 如果遊戲結束
if done:
s_ = None
agent.observe((s, a, r, s_))
agent.replay()
s = s_
R += r
if done:
return R
agent = Agent()
episode_number = 0
reward_sum = 0
while episode_number < TOTAL_EPISODES:
reward_sum += run(agent)
episode_number += 1
if episode_number % BATCH_SIZE_BASELINE == 0:
print('Episode: %d, Average reward for episode %f.' % (episode_number,
reward_sum / BATCH_SIZE_BASELINE))
if episode_number%200==0:
plot_weights([(agent.brain.params['W1'], 'Episode %i $W_1$'%episode_number)], figsize=(14,5))
if reward_sum / BATCH_SIZE_BASELINE > REWARD_TARGET:
print('Task solved in %d episodes' % episode_number)
plot_weights([(agent.brain.params['W1'], 'Episode %i $W_1$'%episode_number)], figsize=(14,5))
break
reward_sum = 0
agent.brain.model.save('dqn.mod')




 iThome鐵人賽
iThome鐵人賽