昨天我們執行了官方提供的範例程式, 透過CLI進行了flink job submit, 並看到了結果。如果在開發的過程中需要測試語法, 除了寫成scala檔包成JAR檔執行之外, 是否有更方便的方式呢?Flink提供了類似spark-shell的工具, 今天先來介紹這個工具, 後續要測試API的話會在這個工具底下進行。
./bin/start-scala-shell.sh local
執行成功後會顯示下面的畫面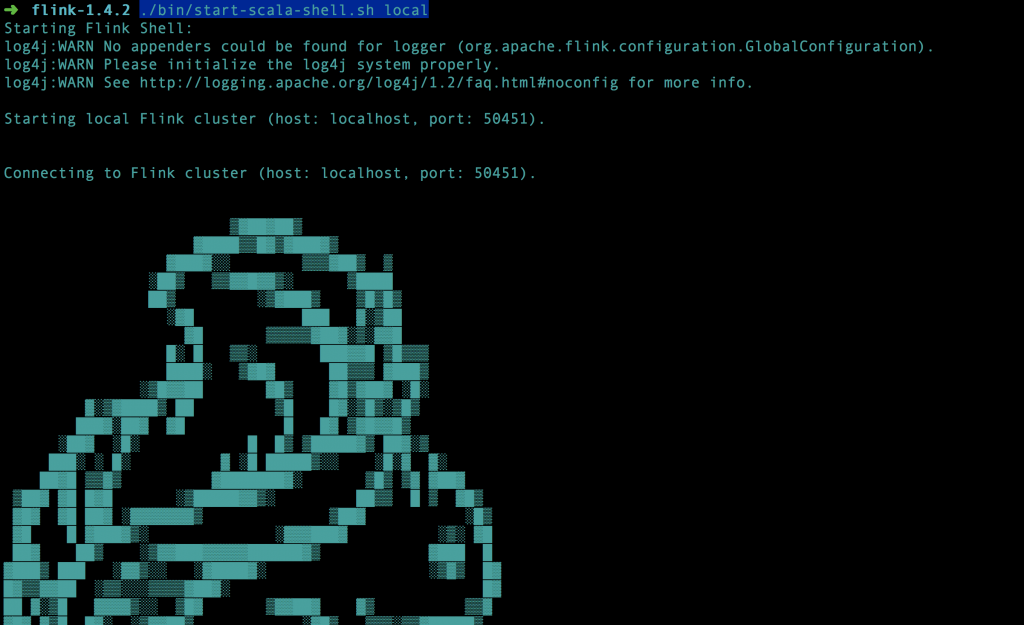
這個工具支援了Batch/Streaming, 因此在啟動之後, 兩種的ExecutionEnvironments會自動的建立起來,分別是"benv"和"senv", 有點類似spark-shell一樣啟動之後會幫你把sc(SparkContext)已經建立起來。會有簡單的範例如下圖: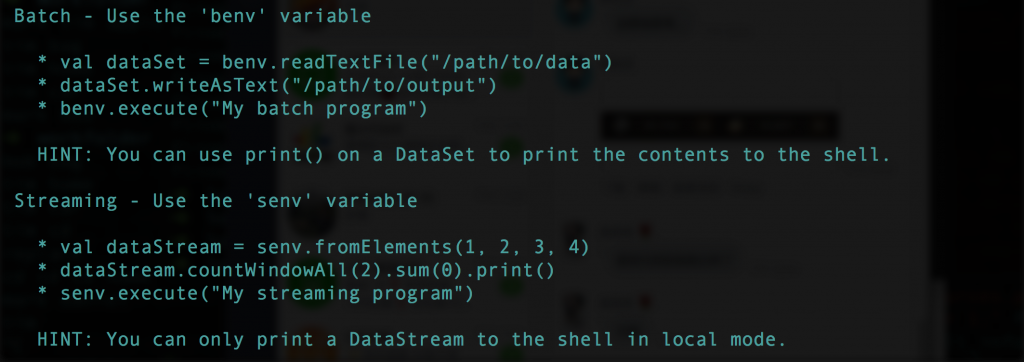
//load data from socket
val textStreaming = senv.socketTextStream("localhost", 9000)
//data transform with mapreduce
val countsStreaming = textStreaming.flatMap { _.toLowerCase.split("\\W+") }.map { (_, 1) }.keyBy(0).sum(1)
countsStreaming.print()
//run the programe
senv.execute("Streaming Wordcount")
3.執行結果如下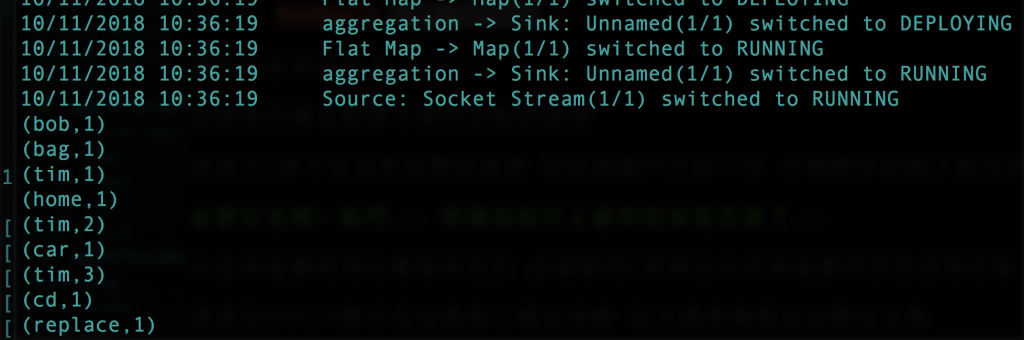
bin/start-scala-shell.sh [local | remote <host> <port> | yarn] --addclasspath <path/to/jar.jar>


 iThome鐵人賽
iThome鐵人賽