到目前為止,已經知道識別數據類型以及資料缺漏的問題,也實際見識填補資料數據的方法。現在將探討的是正規化與標準化資料,也是增強機器學習流程的方法之一。
讓我們從一張資料集中各個表徵的直方圖開始: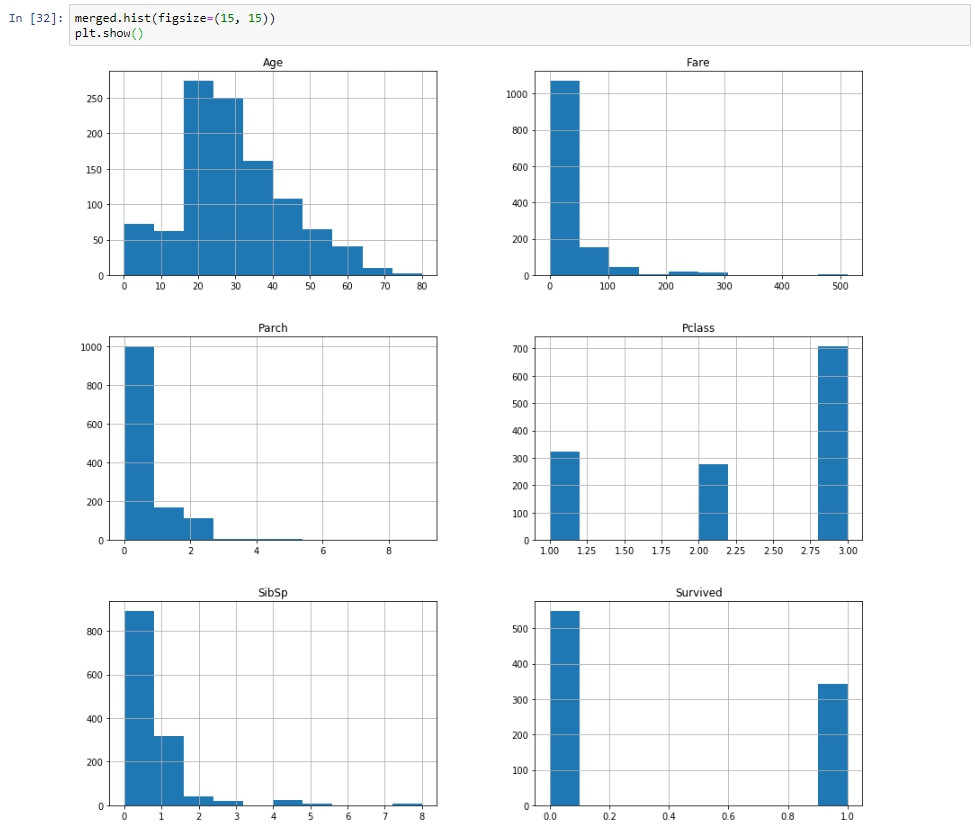
注意到每個列的平均值,最小值,最大值和標準差都有很大差異。使用以下代碼通過describe方法更加明顯(各個表徵的min、max值差異極大):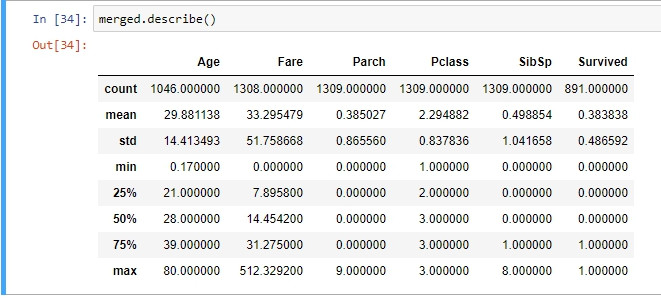
試著在顯示所有表徵直方圖時使用統一的尺度(X軸以所有表徵中最小、最大值為範圍):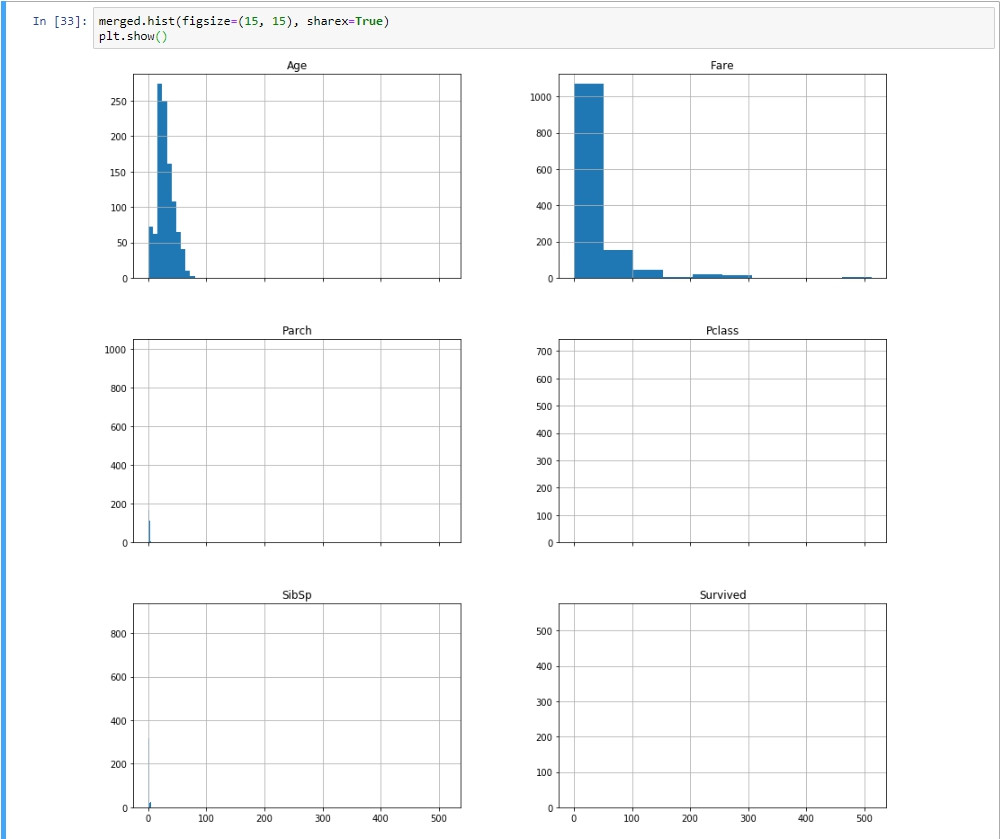
由於資料的值範圍變化很大,在一些機器學習算法中將造成問題。原因是如果其中一個表徵具有較大尺度的數值,則此表徵的影響度將大於其他小尺度的表徵。因此,應對所有表徵的尺度正規化,使每個表徵的尺度統一。例如,正規化的常見形式是將所有定量列資料轉換為0和1之間的數值,或者所有資料必須具有相同的均值和標準差。
以下是幾種標準化的方法:
接下來將會以三篇文章分開介紹上續三種正規化方法,並且對照正規畫前後的模型表現。

