最常見的正規化技術,Z-score normalization,背後有著簡單的統計概念。Z-score normalization的結果是被重新縮放以具有平均為0和標準差為1的資料。經過Z-score normalization正規化,通過重新縮放我們的資料以具有均勻的算術平均數和方差(標準差的平方),因此則一些依賴歐式距離作為核心的機器學習模型模型如knn得以最佳方式學習而不傾向於單位尺度較大的資料。以下是Z-score normalization的公式:
z = (x - μ) / σ
公式中的變數:
從讀取TITANIC資料開始:
#各欄位的資料類型
column_types={'PassengerId':'category',
'Survived':int,
'Pclass':int,
'Name':'category',
'Sex':'category',
'Age':float,
'SibSp':int,
'Parch':int,
'Fare':float,
'Cabin':'category',
'Embarked':'category'}
#訓練集
train_set = pd.read_csv('data/train.csv', dtype=column_types)
train_set = train_set.drop(['Cabin'], axis=1)
train_set = train_set.dropna()
train_set = pd.get_dummies(train_set)
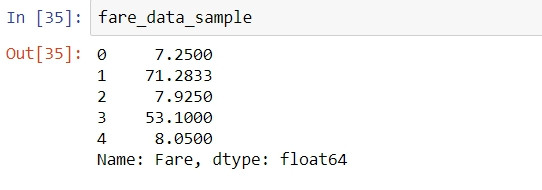
fare_data_sample = train_set.Fare.head()
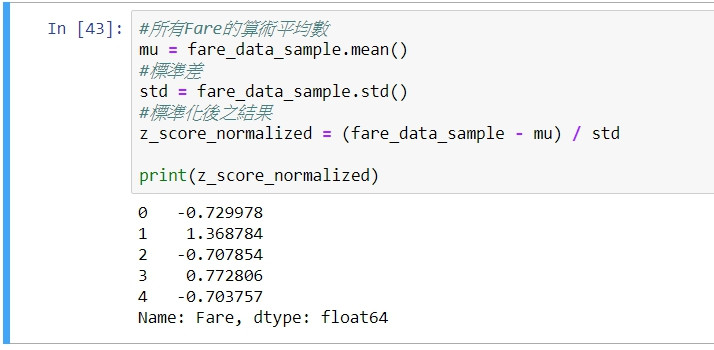
依照Z-score normalization的公式,定義所有變數,並且產生正規化後之結果:
#所有Fare的算術平均數
mu = fare_data_sample.mean()
#標準差
std = fare_data_sample.std()
#標準化後之結果
z_score_normalized = (fare_data_sample - mu) / std
print(z_score_normalized)
要對pandas Dataframe做全部欄位的正規化,必須逐一欄位進行。以下為code範例:
#z-score 函式 - pandas version
def z_score_normalization(df, cols):
"""Normalize a dataframe with specified columns
Keyword arguments:
df -- the input dataframe (pandas.DataFrame)
cols -- the specified columns to be normalized (list)
"""
train_set_normalized = train_set.copy()
for col in cols:
all_col_data = train_set_normalized[col].copy()
print(all_col_data)
mu = all_col_data.mean()
std = all_col_data.std()
z_score_normalized = (all_col_data - mu) / std
train_set_normalized[col] = z_score_normalized
return train_set_normalized
normalized = pd.DataFrame(z_score_normalization(train_set,
train_set.keys()))
當然,sklearn已經有內建的z-score方法可以使用:
#z-score 函式 - sklearn version
from sklearn.preprocessing import StandardScaler
scale = StandardScaler() #z-scaler物件
train_set_scaled = pd.DataFrame(scale.fit_transform(train_set),
columns=train_set.keys())
pandas version 以及 sklearn version產生的結果是完全一樣的,差別只在於使用sklearn api可以輕鬆寫意的做完Z-score normalization。
各表徵有截然不同的尺度: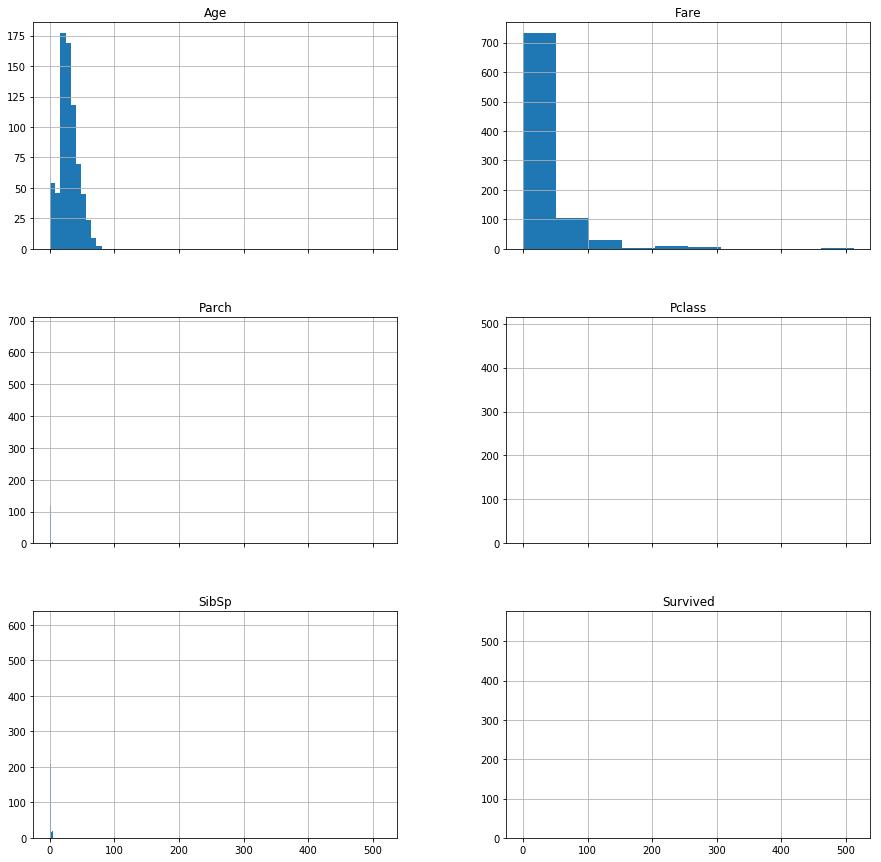
各表徵尺度已經統一: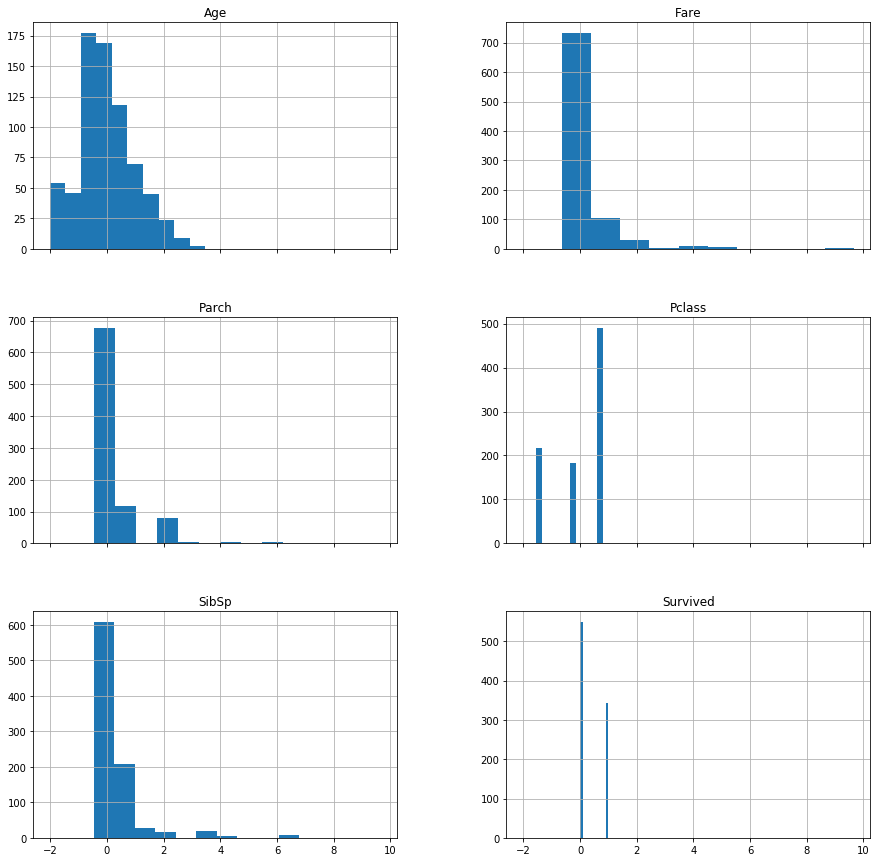
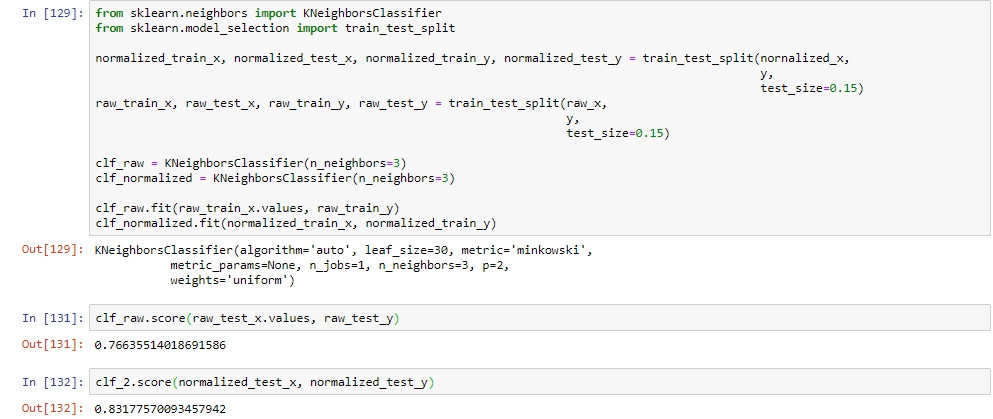
最後以KNN來做正規化前後的準確度驗證,以正規化資料訓練的模型大幅優於無正規化: