最後一個正規化方法是按行(row)而不是逐個列(欄位)進行。此標準化技術將確保每行數據都具有一樣的範數(Norm),聽起來很艱澀拗口,但實際上Norm可以看做是在計算長度或距離,這代表著每行的向量長度都一樣(正規化每行的向量長度皆為1),而不是計算每列,均值,最小值,最大值等的統計數據。我們假設資料中的每一行為一空間中的向量:
x = (x1, x2, ..., xn)
而範數是這樣計算的:
||x|| = √(x1^2 + x2^2 + ... + xn^2)
這被稱為L-2範數,另外也存在其他類型的範數,但我們在本文中不會涉及。另外,因為範數用來計算距離與長度,在處理文本數據或聚類算法時特別有用,原因是這樣類型的任務例如Knn/Kmean/詞向量,通常仰賴歐式距離。
老樣子,從讀取TITANIC資料開始:
#各欄位的資料類型
column_types={'PassengerId':'category',
'Survived':int,
'Pclass':int,
'Name':'category',
'Sex':'category',
'Age':float,
'SibSp':int,
'Parch':int,
'Fare':float,
'Cabin':'category',
'Embarked':'category'}
#訓練集
train_set = pd.read_csv('data/train.csv', dtype=column_types)
train_set = train_set.drop(['PassengerId', 'Cabin', 'Ticket', 'Name'], axis=1)
train_set = train_set.dropna()
train_set = pd.get_dummies(train_set)
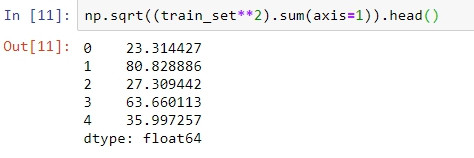
用Row normalization的公式計算每行的向量長度:
#L2 norm
np.sqrt((train_set**2).sum(axis=1))
使用sklearn的Row normalization api做行正規化:
from sklearn.preprocessing import Normalizer # our row normalizer
normalize = Normalizer()
train_set_normalized = pd.DataFrame(normalize.fit_transform(train_set))
np.sqrt((train_set_normalized**2).sum(axis=1)).mean()
#output:1.0
比對正規化前後的模型訓練差異: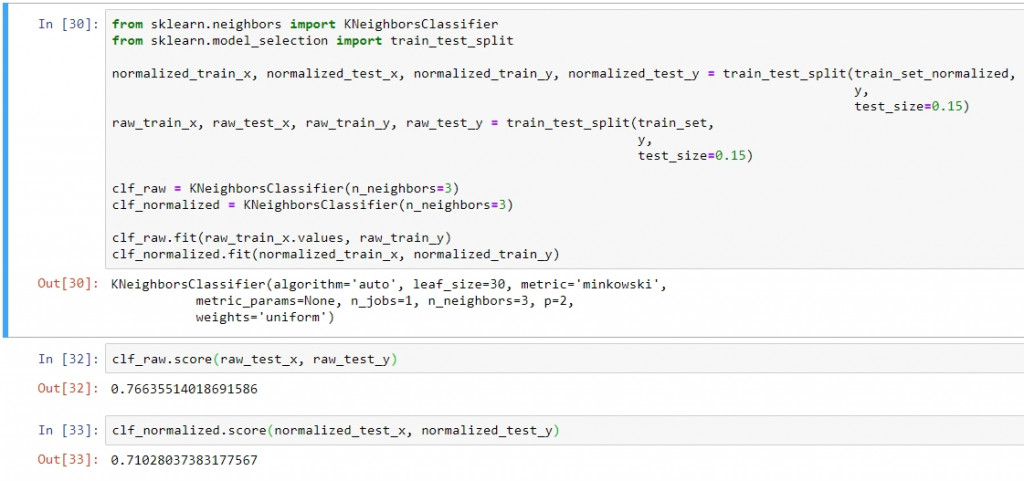
Row normalization是此三種正規化方法在titanic資料上表現最差的。但是這並非代表他總是表現最差,而是他有自己的使用情境。因此在使用正規化方法時應該多做驗證比較,找到適合自己資料集的正規化方法,才能有效優化機器學習的流程。


 iThome鐵人賽
iThome鐵人賽