從鐵人賽旅程的一開始到現在也經過15天,賽程的一半了。回頭看看這段時間因為寫文的關係,複習了不少特徵工程的知識。因此昨天找了一空檔時間,來進行titanic challenge的更新,僅以目前寫文涵蓋的範圍內兜在一起看看能做到什麼程度。滿驚訝的是,僅用前面涵蓋的技術加上對某些特徵的淺薄想法完成的初版模型預測,上繳後就來到了目前**Kaggle前6%**的位置,比在寫前幾篇文章時上傳的80%準確率提升了149個名次,可喜可賀!亮一下昨天上傳後的名次圖:

接著我要分享目前的特徵工程作法,而之所以說目前,是因為我打算透過這整個系列技術文的過程,僅用titanic dataset演示如何在這過程所學的知識,一步一步加強機器學習的流程。我最初的打算是在不同的章節涵蓋幾個不同的dataset,但titanic是一個很有趣的資料集,還有太多可以優化的作法(如缺漏值填補、透過EDA發現新表徵),而隨著系列文的繼續發展,將會有更多新的思維產生。如果能在鐵人賽的結尾站上titanic challenge的前2%,將會是一件很酷的事情。
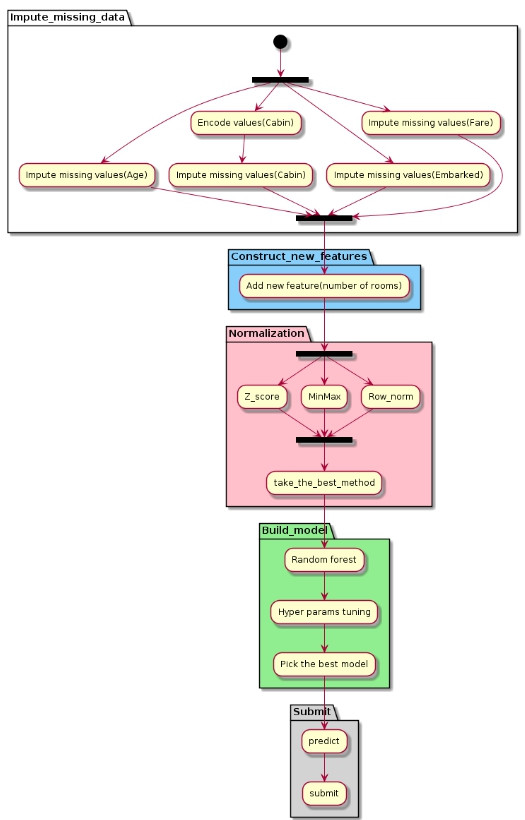
整個流程分成五個階段:
補缺值特別有趣,不論是Cabin或是Age欄位,我都用一樣的策略;使用表徵相近的乘客來做補值的依據(前些章節有提到)。
以下是在特定表徵有相同表現的乘客;這些乘客有一樣的稱謂、乘客等級、家人數量、性別等等...。在此特定表徵雷同下的乘客,年齡也非常相近,因此我用此方式來做年齡缺漏值的填補策略。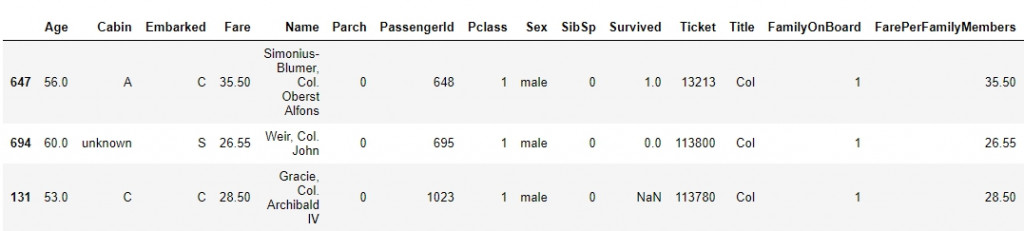
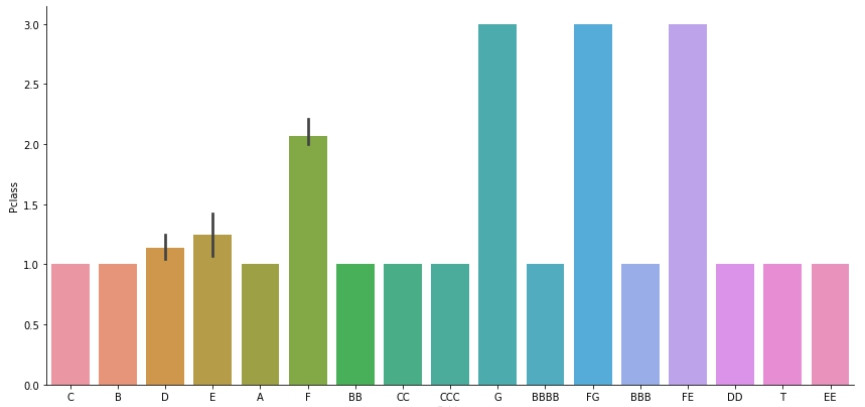
以下是各Cabin較多數的Plcass分布,可以看出Pclass也與Cabin有高度相關(最高級乘客都分布在特定的Cabin)。因此若要填補Cabin缺值,參考Pclass與Fare將會是很好的方式。當然除了這兩個表徵以外我也參考了家人數量等等的別的表徵。
先看看Cabin與生存率的關聯: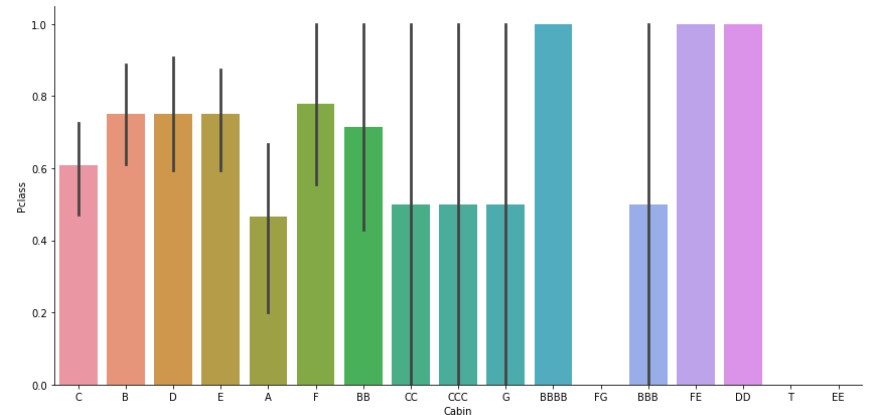
Cabin裡包含了房間數量的訊息,例如BBB、CCC可能代表乘客訂購了BC兩艙的三個房間。因此Cabin的表徵可以細化成兩個獨立表徵;船艙區域以及房間數量(船艙區域:BBB->B或AAA->A,房間數量:BBB為三間、AA為兩間...以此類推),最後從線性關係圖中可以觀察到房間數量與生存率有反比的關係。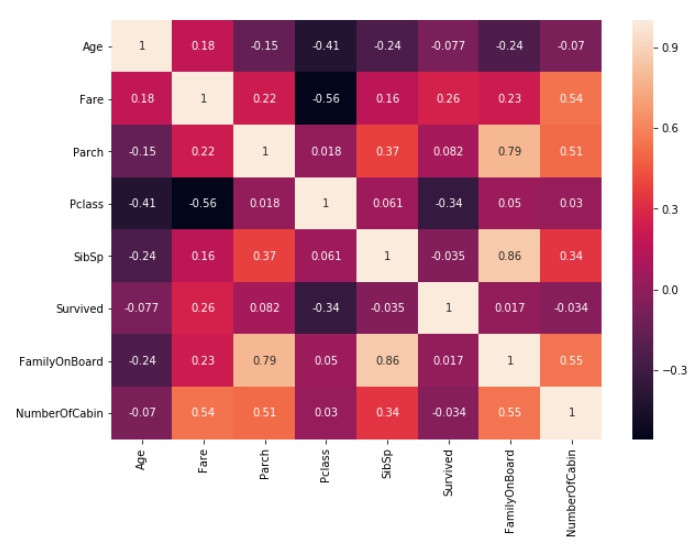
進行正規化時分別使用不同的正規化方法,以一簡單模型驗證各自的準確度後取最高者。在我的實驗中z-score表現最出色,也是最後採用的方法。
由於本系列文章注重於探討特徵工程的知識,因此其他流程在此便不贅述。
此作法流程還有許多可優化的地方,資料中有許多奧妙之處等著我們去探尋,例如幾乎所有的titanic文章都沒有提到的(至少我沒看過),ticket和name欄位其實大有文章,但大部分文章的做法是直接丟棄了此兩欄位,為什麼這麼說呢?一起往下看:
將name欄位做字串的處理,取得名字的first name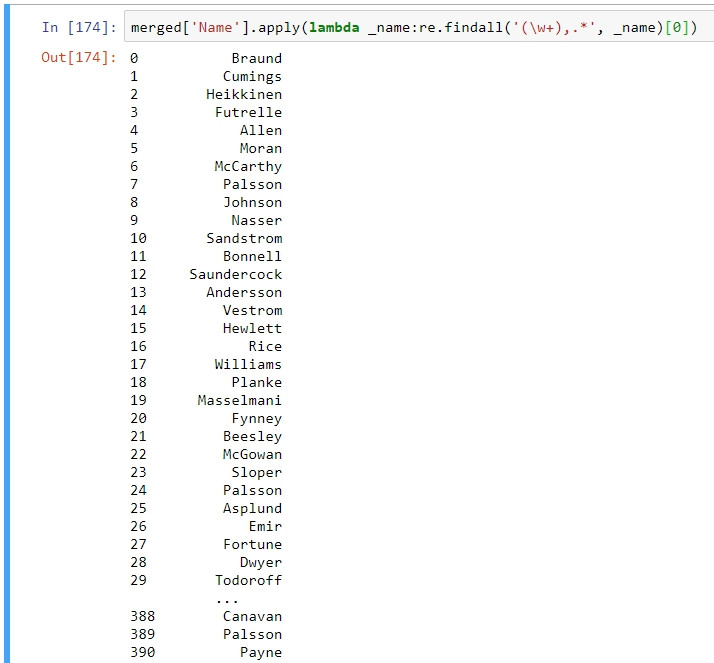
算一下first name的集合: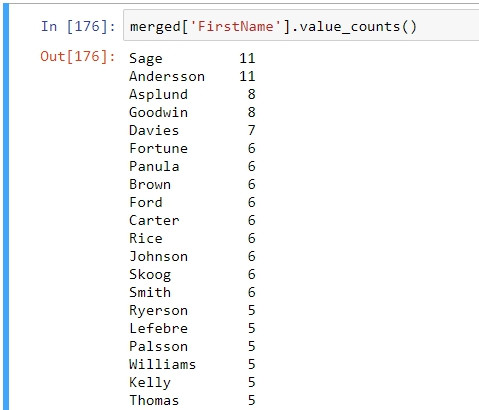
赫然發現重複的first name可真多呢,於是動念一想,會不會有著相同的first name的乘客是同一家族的人呢?
以first name為Panula的乘客來看看:
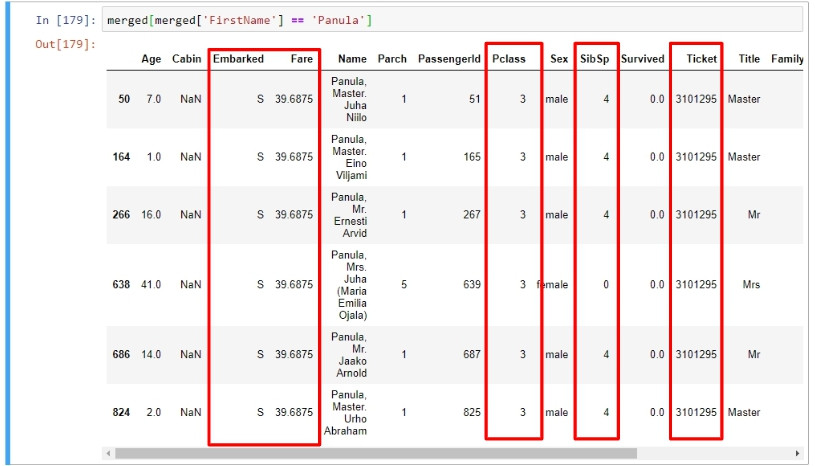
后里蟹!定睛一看這些人居然有些欄位數字完全相同,例如上船的港口、乘客等級、票價、親人數量,重點在票別完全一樣。以下的資料足可佐證這些人是出自同一個家庭,highlight部分顯示有5位乘客的手足數量皆為4,如果一次看一名乘客的話,剩下的4人正好是他手足的數量。言下之意,這五名乘客互為彼此的兄弟姊妹。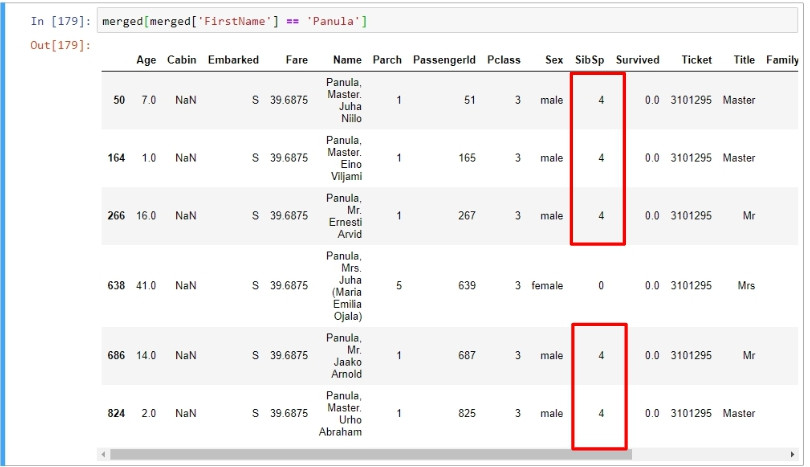
再來看看Parch欄位,此欄位代表雙親或是子嗣的數量,剛剛舉例的幾位乘客年齡都尚輕,因此不大可能有子嗣,因此parch的數量最多為2(表示雙親都在船上的情形)。而他們的parch數量都為1,表示父母只有一位在船上。藍色highlight的部分則是重點所在,表示該位乘客的父母或子女有5名在船上,很明顯這位乘客就是剛剛那五名的母親。
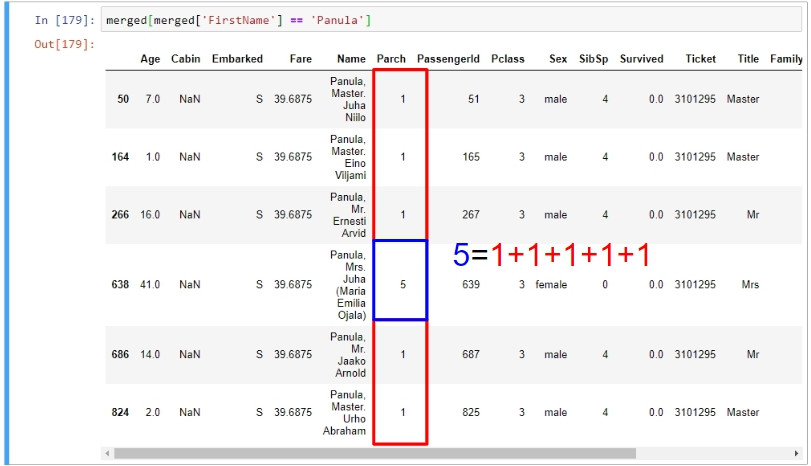
這是我今天一個很重要的觀察,基於這個觀察,有許多資料流程的對策都可能會改變,例如補值和新的特徵:
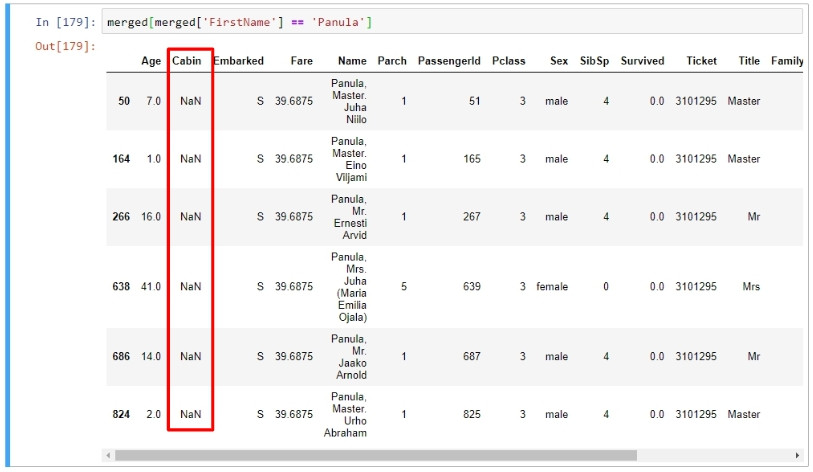
此家庭的人在Cabin方面全都有缺值,如果沒有考慮進家庭因素的話,原本的補值策略是每位乘客獨立進行,結果就是可能所有家庭成員最耗的結果都不盡相同。但事實上同一家庭的成員較可能住在同一個cabin,未來補值策略就應該要考慮進家庭的要素。
家庭要素可能也是與存活率高度關聯的特徵,例如當雙親都在的情形是否子女的存活率更高一些、女性單親與其子女是否有更高的機會存活、丈夫在的情形下是否妻子存活率更高...等等許多待探索的新特徵。
資料還有許多奧妙之處等著我去探索,由衷感到熱血沸騰呢。
待續....
您好唷~
我讀了您這一系列的文章覺得對我新人來說真的收穫良多,
只是在讀到這篇時有些嚇到, 看了原本的資料的格式姓名的部分確實是蠻奇怪的,
估計是比較古代的寫法? 真正相同的部分是姓(last name), 或稱為family name比較準確
比如看劇就會發現她們叫Ms. Elizabeth, 其實叫得是名字啊, 若拿這些名字去查也可以發現他們的順序是正常的, 只是在這個資料格式採用了不同的寫法
再次感謝好文!

