今天我們來談談 activation function 吧!
談 activation function 之前先要談談線性轉換。
有上到比較後面的線性代數的同學,應該有爬過 SVD 這座高山。
推薦可以看周老師的線代啟示錄 奇異值分解 (SVD)
我們可以知道一個矩陣可以被看成線性轉換,而矩陣這個線性轉換可以被分解成 3 個矩陣:
這 3 個矩陣分別是有意義的,U、、V 的意義分別是旋轉、伸縮、旋轉的意思。大家可以參考以下的圖:

圖來自以上提到的文章
所以我們可以知道矩陣能做的事情大概就是旋轉伸縮這些事情了。
在模型上,我們還會加上一個 bias 來達到平移的效果。
我們可以來造一些點:
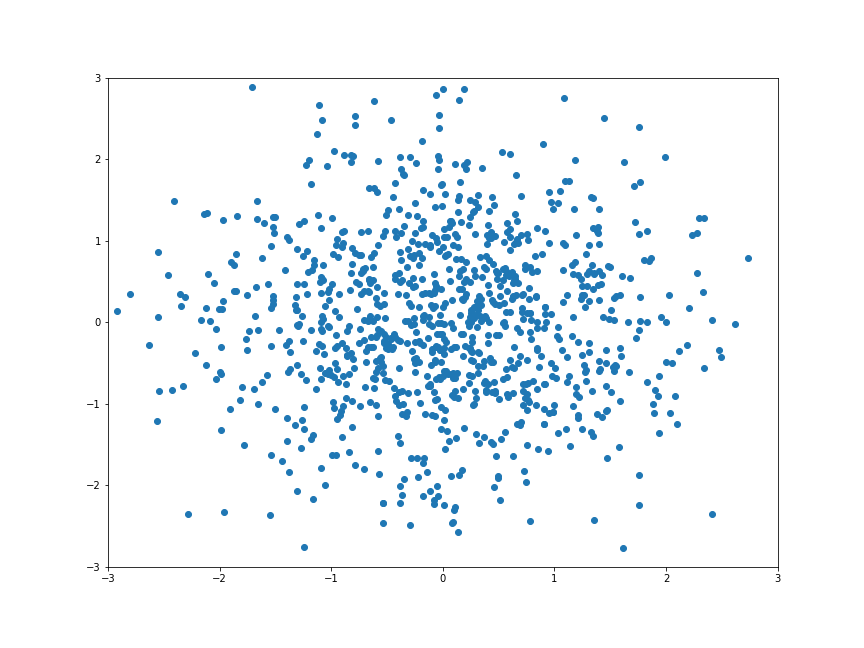
我們可以 random 造一個矩陣:
所以我們可以對每個點做運算 :
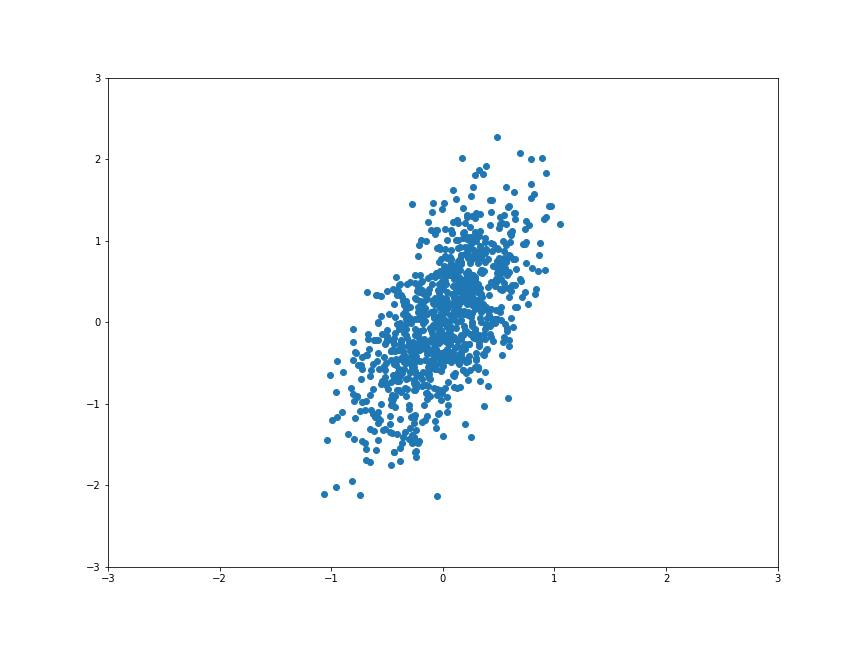
接下來我們先來試試看在 CNN 用最多的 ReLU,我們把上面的點通過 ReLU 之後會發生什麼事呢?
大家會發現只留下第一象限的點是沒有動到的,剩下的象限的點都被擠到 x 軸跟 y 軸上了。
所以在高維度的世界中,點都會保留第一象限不變,其他象限被擠壓到軸上。
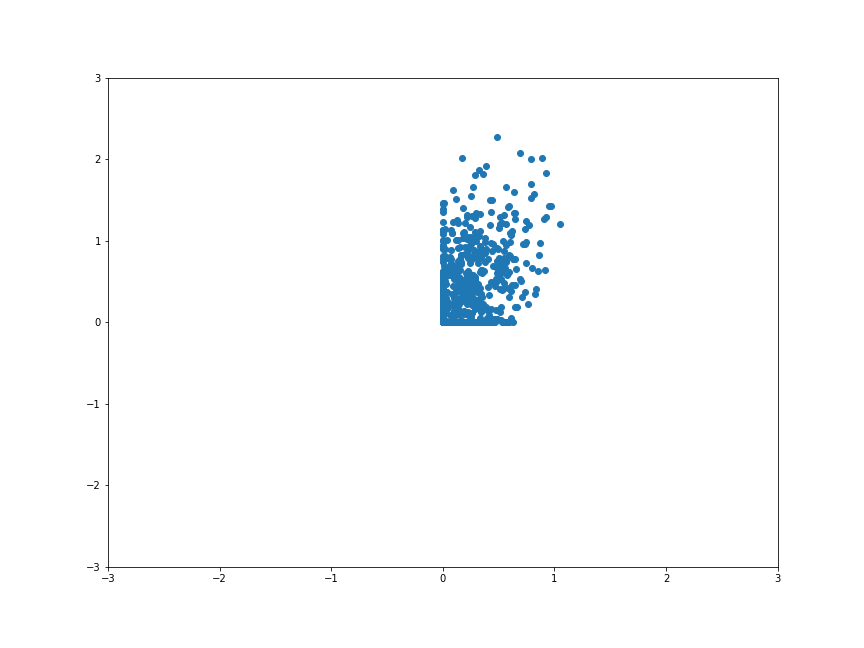
那如果是用 sigmoid 的效果呢?
他將所有的點都壓到 (0, 1) 之間,所以整個形狀就縮小很多。
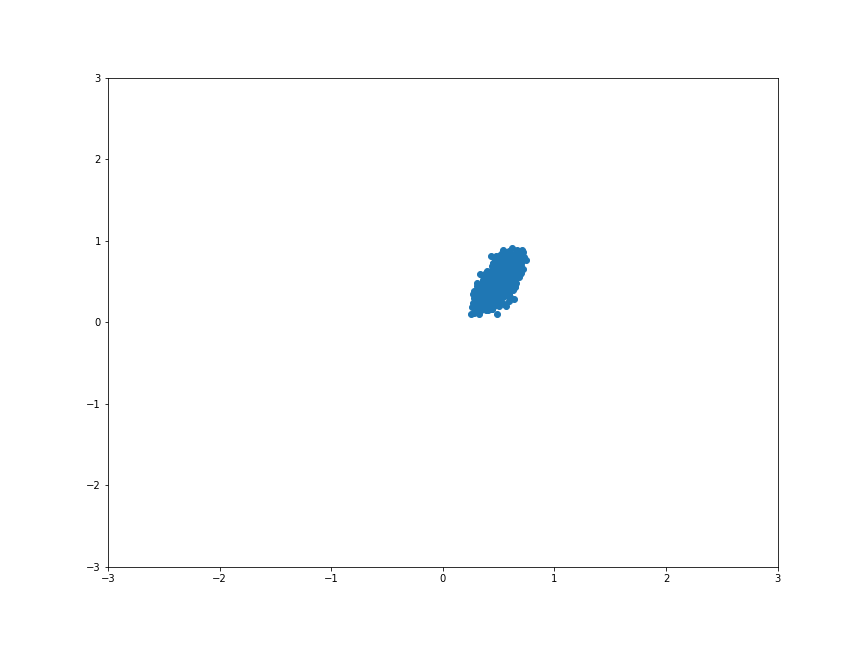
我們放大來看看他整體形狀有沒有什麼變化。
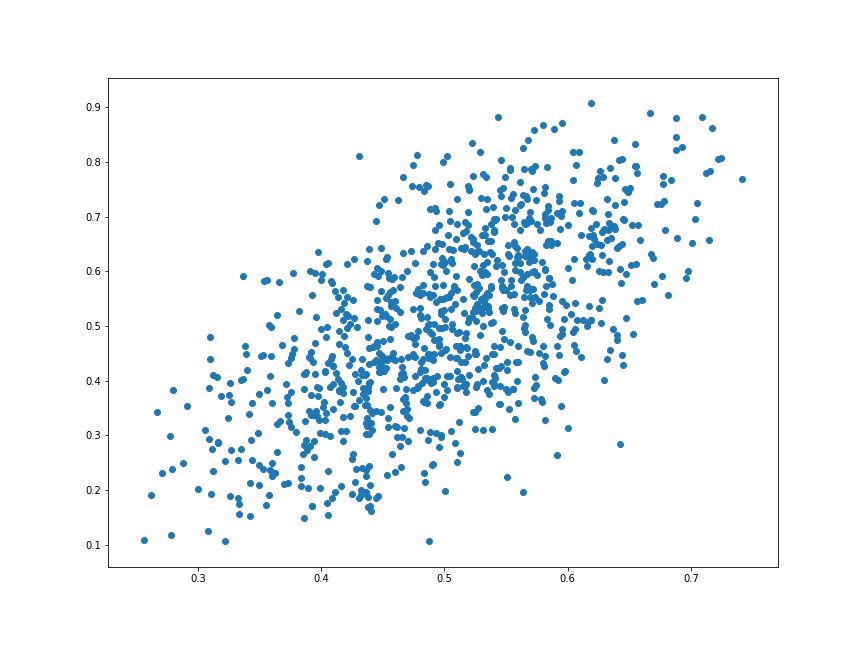
整體形狀有些微被扭曲了,不知道大家有沒有發現呢?
所以在引進 activation function 之後,模型擁有了 扭曲 的能力!
那麼 activation function 到底實際上做了什麼事呢?
以 ReLU 來說,他就像一個工匠正在雕塑一個作品。
ReLU 就是工匠手上那把彫刻刀,他會把第一象限以外的部份削掉。看起來就會像朱銘大師的作品這樣:

圖來自 漫遊‧藝術網@成大校園
原諒我私心用成大的雕塑品當範例。XD
ReLU 會將不重要的部份削掉,剩下重要的特徵接續後面的特徵萃取。
以 sigmoid 來說,他將點壓到 (0, 1) 之間看似很難以理解。
其實這個 activation function 在影像辨識當中比較不是主流的方法,可能不是那麼適用,不過在 NLP 領域算是還蠻常用的方法。
那如果放在 CNN 的話,就會發生梯度消失的問題。
在比較早期的時候,大家在影像處理上都遇到梯度消失的問題。如果直觀上看來,如果每過一次 convolution layer 就會被壓縮到 (0, 1) 一次,那麼後面再接 subsampling 的處理,又會縮小一次,並且失去某些訊息,想當然爾特徵就在不斷縮小的過程中慢慢不見了。這樣的效果讓早期的模型無法變得更深。
讓 convolution layer 去篩選哪些 feature 該留下來,讓 subsampling layer 去做縮小的動作,各自負責各自的功能,這樣看來是比較好的作法。
這是一個比較直觀的解釋方式,歡迎大家提出不同的看法。
我想蠻多人應該會有跟我一樣的問題。
我知道如果用 ReLU 可以把不要的部份削掉,那麼我怎麼知道要削哪裡?
答案是 backpropagation (gradient descent method) 會告訴你!
藉由 forward 將訊息傳遞到 output layer,backward 所回饋的 gradient 正提供一個訊息,這個訊息會告訴模型要怎麼調整線性轉換的矩陣,來讓 ReLU 可以切在對的位置。
softplus 是一個跟 ReLU 非常像的 activation function。
兩者的差別:

你可以把 softplus 看成 ReLU 的可微分版本,或是將 ReLU 看成 softplus 的簡化版本。
他在負的區域看起來跟 sigmoid function 很像,另一邊正的區域就會非常接近 identity function。
在行為上也很符合神經的特性,就是有正向的訊號就會是正向的輸出,如果是負向的訊號就不輸出。
很有趣的特性吧!
其實沒有規定 activation function 一定要長怎樣。
但是拿多項式函數或是其他函數會讓整個模型非常難以理解,而且當中的參數還不少。
所以依照 Occam's razor 的原則,我們先拿簡單的函數來用會比較好。
不同的模型跟問題其實適用不同的 activation function。
像影像辨識中,CNN 的設計是要先做 feature extraction,再進行分類。
所以在 feature extraction 的階段就需要找適用的 activation function。
那像在 NLP 領域,他們關心的是機率分佈,而 sigmoid 就很合機率分佈的調調。
這邊原諒我草率帶過 NLP 的部份,今天的主軸都擺在 CNN 上。XD
今天就到這邊告一個段落囉。


 iThome鐵人賽
iThome鐵人賽