標題這不是一個專有名詞。
在電腦視覺的領域中有幾個有名的問題:
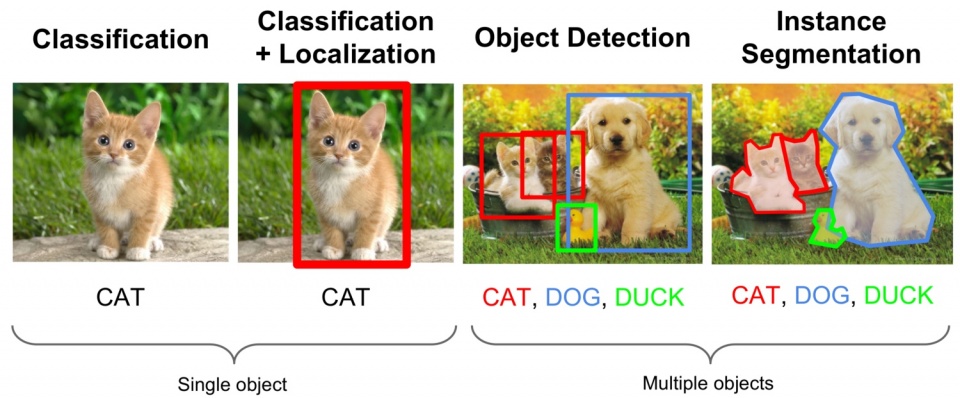
影像辨識是給一張影像,希望模型可以辨識出當中的東西是什麼。輸入模型的會是影像向量,輸出的會是類別向量。
物件辨識給的同樣是一張影像,除了需要辨識出當中的物件以外,還要給出這個物體所在的位置,輸出的除了類別向量以外,還有座標。
語意分割可能無法一眼看出當中的含意,對一個句子來說,詞本身帶有一些含意,對比到影像上,句子就是影像,而詞意就是影像中的物體。語意分割是給一張影像,需要將影像中的物件切割出來,所以必須對每個像素做分類。

三者是各自不同的任務。
不同的任務有些共通性,這些共通性讓他們可能都可以適用 CNN 的架構。不過這麼說還是太過粗糙了。
對於影像辨識來說,一般性架構會是有 convolution layer 為主的 feature extractor,接著會是以 fully-connected layer 為主的 classifier。在不同階段有不同的目的,在輸入影像之後要先對影像進一步抽取特徵,有了足夠的特徵之後才進行分類。
語意分割也有類似的架構,在前面會有 convolution layer 為主的 feature extractor,但是為了將每個樣素做分類,必須對每一個像素做預測,預測像素的類別。在後半的部份,有人提出了 Fully convolution network,試圖做像素的類別預測。
像素的類別預測這件事從另一個角度切入,會很像是一種生成的過程。也就是,我們在前面要將影像的特徵萃取出來,是一種將資訊壓縮的過程,在後半我們希望將壓縮的資訊還原到某種程度,我們需要產生器(generator)。

在語意分割這個問題,後來就一路發展到了 encoder-decoder 架構,我們又回到類似 autoencoder 的樣子,讓 encoder 跟 decoder 一起訓練的模型架構。在這邊 encoder 就是 feature extractor,decoder 就是一種 generator。


 iThome鐵人賽
iThome鐵人賽