為什麼需要用 Spark?Azure 為何需要引進並整合一個基於 Spark 的服務?三大目標:「速度、通用、集群」。它最大的特徵,或者說使用時機,是「面向集群計算」。
在強調「速度」的大數據相關應用服務中,或可以考慮用 Spark,因為 Spark 可以在內存 (memory) 中進行計算,所以可以讓用戶即時、互動式地 (interactively) 使用服務。
為什麼 Spark 可以處理之前需要多個獨立的分散式系統 (Independent Distributed System) 來處理的任務?這些任務通常包括:Batch Processing Server、Interative Algorithm Server、Interative Database Server、Realtime Data Stream Server 等。主要原因是 Spark 的高度整合性,它可以用一些很簡單的 API,去存取其他大數據工具,像是 Hadoop、Cassandra 等等。Spark 可以管理多個工作機器 (即一個計算集群),在當中去調度、分發和監控這些計算任務用,就像使用 .NET library 套件一樣在一個軟件中組合他們。
其實 Spark 算是滿高階 (High-Level) 的整合應用服務平台,它的 RDD 概念 (彈性分布式數據集 Resilient Distributed Datasets),不同機器節點上取得的數據集合,然後再編程進行平行運算。
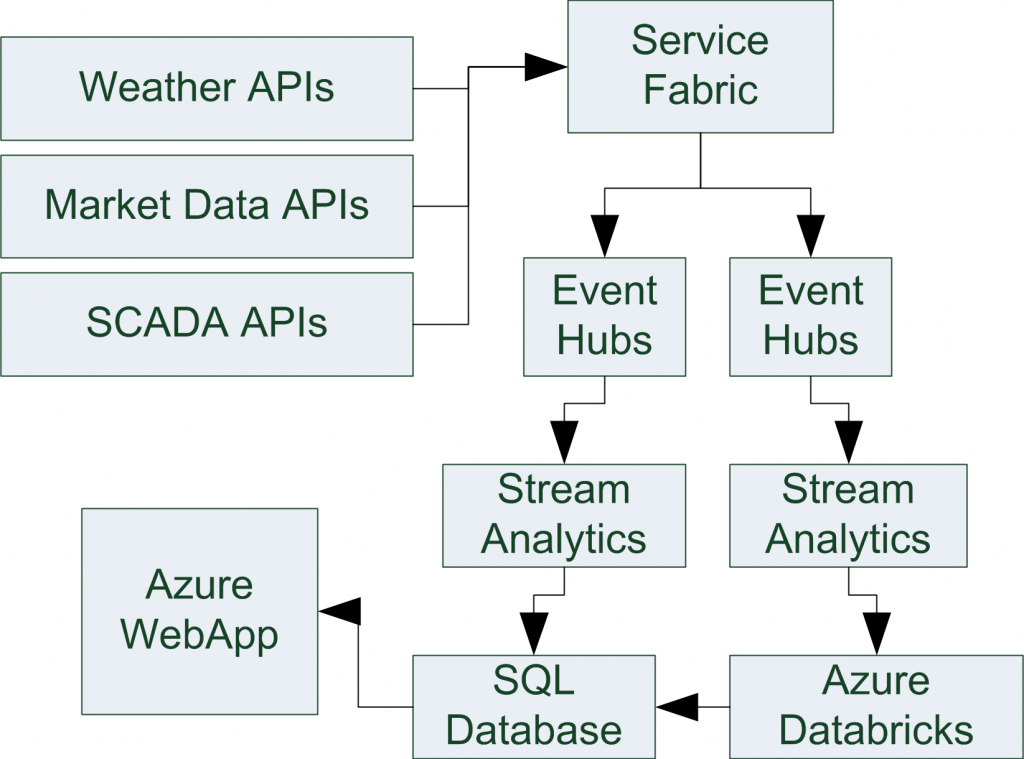
我感覺 GIS 的應用很適合使用 Spark,原因是不同地理位置的數據源,Spark 可以在高層整合後,進行內存數據、磁盤數據、實時數據的快速切換使用,在低層、中間節點則可交給 IoT Hub 服務等進行整合。進而在其上又有 GraphX 可以進行圖學 (Graph Theory) 操作與應用。
Spark 對於要「快速做數據科學實驗並知道結果」很有幫助,我們把這個需求叫作「實時互動式數據分析」。通常用 Pandas 或是其它 ML 套件一個實驗下去都要跑很久,通常是因為數據量很大的緣故,這時 Spark 環境就很適合數據科學家進行工作了。
下一個問題是:Spark 能在「商業化」或是能夠在實際「生產環境」被可靠地使用嗎?這時就進入到了 Databricks 的時代。Databricks是 Spark 的商業化公司,後來又有了 Azure Databricks 的合作。
一些比較成功的實際商業用例,包括:監控和預測舊金山灣區的交通擁堵情況,還有 Renewables.AI 用在管理太陽能場域的應用,「能源效率 Energy Efficiency」是一個關鍵字,其資料科學團隊為公司增加了 50% 的生產力。

一個使用 Azure 的好處是,我們建置一次,它可以使用在世界各地有 Azure 支援的地方,這一點很適合跨國企業轉型。