上次的 code
from sklearn import datasets #載入 sklearn
import pandas as pd
iris = datasets.load_iris();
iris.keys()
x = pd.DataFrame(iris['data'],columns=iris['feature_names'])
y = pd.DataFrame(iris['target'], columns=['target_names'])
data = pd.concat([x,y], axis=1)
data.head(10)
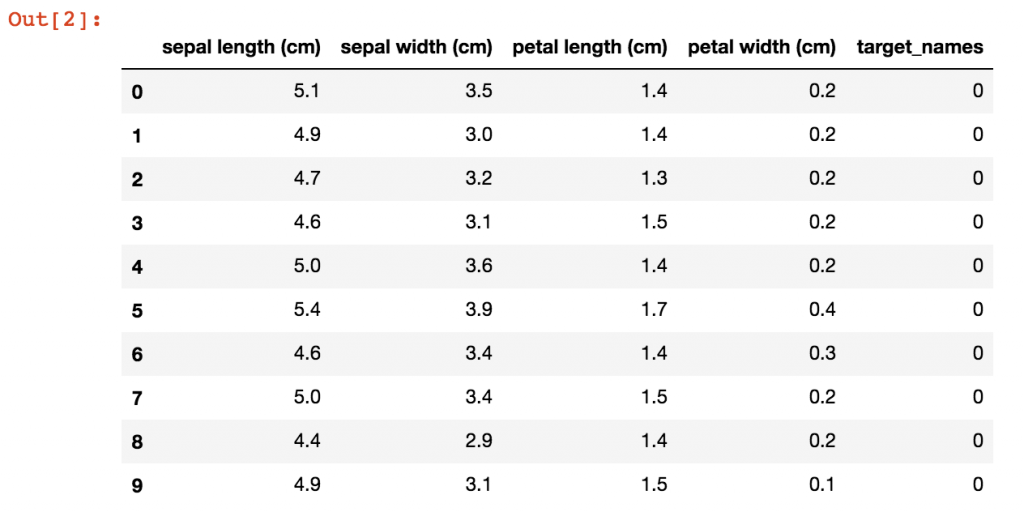
這是我們整理出來的資料。接著我們開始來作訓練分析吧
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(train_data,train_target,test_size=0.2, random_state=0)
print ("train:",len(X_train), "test:",len(X_test))
train_data:樣本特徵集
train_target:樣本的標籤集
test_size:樣本佔比,測試集佔數據集的比重,如果是整數的話就是樣本的數量
random_state:是隨機數的種子。在同一份數據集上,相同的種子產生相同的結果,不同的種子產生不同的劃分結果
X_train,y_train:構成了訓練集
X_test,y_test:構成了測試集
# 查看被劃分出的測試集
for i in range(len(X_test)):
print ("".join(X_test[i]), y_test[i])

