我們在做資料學習的時候,最簡單最好理解的就是決策樹這個演算法。這個演算法就是不斷的產生 if else 下去對資料進行學習判斷。
好處是,這個邏輯非常適合拿來解釋,正常人類都會聽得懂。所以我們可以很簡單的跟其他人解釋我們在幹嘛。但是有個滿大的問題就是藉由這樣的方式推算出來的演算模式非常依賴資料來源的可靠性,如果資料內容有任何的偏差都有可能會導致正確度大幅降低。
在某些情況中,也不是資料愈多就可以讓產生出來的模式預估結果越準確,有可能會因為資料的增加或是判斷特徵的增加反而造成判斷失準。所以決策數通常我們會拿來做簡單的決策例如是非題。
import pandas as pd
from sklearn import datasets
import numpy as np
from sklearn.model_selection import train_test_split #載入資料測驗模組
from sklearn.tree import DecisionTreeClassifier #載入決策樹模組
iris = datasets.load_iris();
X=iris.data
y=iris.target
#設定 20% 的測驗資料
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2)
#開始決策樹運算
tree = DecisionTreeClassifier(criterion='entropy', max_depth=30, random_state=0)
tree.fit(X_train, y_train) #學習
pretest = tree.predict(X_test) #測驗
我們這樣基本上就已經進行學習完成了,但是是不是完全看不出來我們在幹嘛?我們接著看一下
error = 0
count = 0
for i, v in enumerate(tree.predict(X_test)):
count += 1
if v != y_test[i]:
print(i, v)
error += 1
print(count)
print(error)
這樣我們就可以印出來 有多少資料是預測錯的。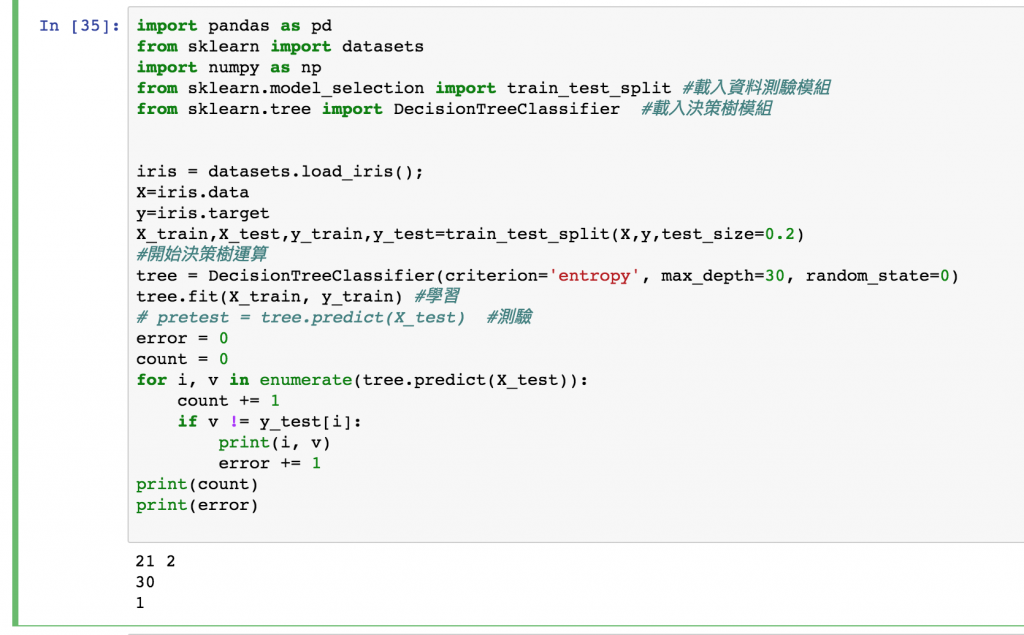
以這次的運算結果來說,總共測驗的筆數是 30 而有一筆錯誤的

