樣本取得方式:參考的作者說明他們在雲平臺搭建了一個IDS,通過IDS的檔案還原功能,獲取到了樣本,同時,使用靜態特徵檢測的手段對惡意樣本進行自動化標註,同時把樣本輸入到特徵碼提取自動化處理流程中。
對opcode做n-gram萃取
特徵選擇階段:測量每個特徵的資訊增益,然後濾除具有最低資訊增益的不太重要的特徵。
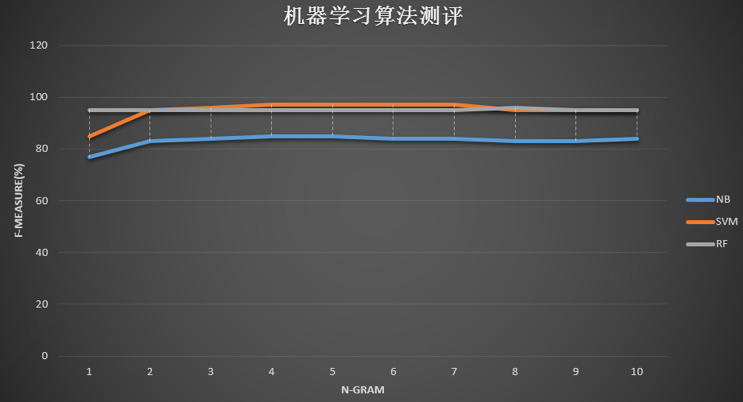
模型比較::Naïve Baye (NB),支援向量機 (SVM),隨機森林 (RF) ,利用公有雲機器學習框架評估,SVM效果較佳
用DNN分空類問題 --- 使用API呼叫序列作為神經網路的輸入CNN+LSTM模型,藉此學習特徵在空間與時間上的微細關係
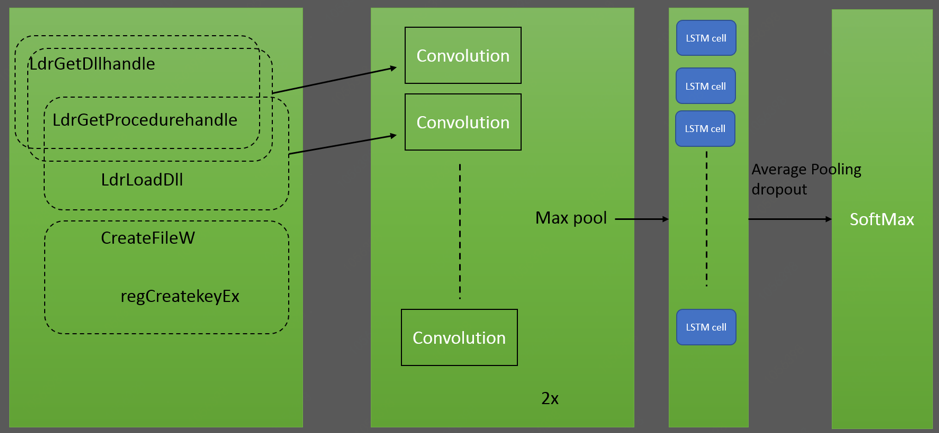
作者使用兩個大小為3×60的卷積濾波器,相當於3-gram。作為卷積的結果,採用大小的特徵向量對於每個輸入特徵,第一和第二卷積層的圖10和20示出。後每個卷積層我們使用max-pooling來減少維數資料為兩倍。接著轉發卷積的每個輸出過濾器作為一個向量,使用LSTM細胞對得到的序列進行建模。
Accuracy: 99.4%
Precision: 99.6%
Recall: 99.5%
因此CNN的convolution 以及max pooling的機制搭配RNN,適用於惡意程式API n-gram資料具有很好的分類效果
其他作法:也可以直接對binary做CNN或CNN+RNN,或是直接把binary轉換成灰階圖做CNN或CNN+RNN
參考來源
惡意軟體檢測之Deep Learning分類器
https://www.itread01.com/chkple.html


 iThome鐵人賽
iThome鐵人賽