https://figshare.com/articles/___/6881282/1
今天在這裡找到新的情感字典,我覺得這是我目前找到最好的
檔案是xlsx檔,有三份工作表
用pandas.read_exel打開
sentment_table = pd.read_excel('../dict/情感词典修改版.xlsx')
sentment_table.drop(['Unnamed: 10','Unnamed: 11'],inplace=True,axis=1)
pos_table = pd.read_excel('../dict/情感词典修改版.xlsx',sheet_name='Sheet2')
neg_table = pd.read_excel('../dict/情感词典修改版.xlsx',sheet_name='Sheet3')
然後我把pos、neg兩份轉成dict。再把neg轉呈負數後合併起來
pos_dict = dict(zip(list(pos_table.posword),list(pos_table.score)))
neg_dict = dict(zip(list(neg_table.negword),map(lambda a:a*(0-1),list(neg_table.score)) ))
sentment_dict={**pos_dict,**neg_dict}
將這份字典的單字加進結巴分詞
for w in sentment_dict.keys():
jieba.suggest_freq(w,True)
準備斷詞和停止詞
stop_words = [re.findall(r'\S+',w)[0] for w in open('../txt/stopwords_ch.txt',encoding='utf8').readlines() if len(re.findall(r'\S+',w))>0]
def sent2word(sentence,stop_words=stop_words):
words = jieba.cut(sentence, HMM=False)
words = [w for w in words if w not in stop_words]
return words
這時已經能做簡單的情感分析了
def get_sentment(sent):
tokens = sent2word(sent)
score = 0
countword = 0
for w in tokens:
if w in sentment_dict.keys():
score += sentment_dict[w]
countword += 1
if countword != 0:
return score/countword
else:
return 0
sent ="我覺得海豚非常聰明"
get_sentment(sent)
5.0
get_sentment()會得到一個數字,0是中間值,越高越正面,越低越負面
不過這方法就像查表一樣,沒什麼機器學習阿...我爬文看起來機器學習還是得靠分類過的語料庫才行
接著我找到一個3萬筆微博評論語料庫
wb30 = [(simple2tradition(i.split(',')[1]).strip(),i.split(',')[0])for i in wblist][1:]
print(wb30)
[('獎勵 就是 親', 'positive'),
('謝謝 妹妹 加 朋友', 'positive'),
('喜歡 吃 南浮', 'positive'),
('好 吧 小 很 強悍 怕 不', 'positive'),
('他 女朋友 旁邊 所以 不 方便 跟 說話', 'negative'),
('講 的話 真 幽默', 'positive'),
('真的 那 好 心疼', 'negative'),
('無所不能 可是 剛才 差點 要 上 百度', 'positive'),
('就是 漂亮 嘛 完美', 'positive'),
('跟 一個 低級 計算機系統 說話 要 那麽 講究', 'negative'),
('不行 必須 起', 'negative'),
('這麽 醜 還 漂亮', 'positive'),
('一點 也 不好 沒有 人 懂 知道', 'negative'),
('噢 咋 設置 美女', 'positive'),
('石家莊 五星級 酒店', 'positive'),
('機器人 怎麽 可能 忙', 'positive'),
我看著內容有些句子怪怪的,有些分類似乎也不正確
('這麽 醜 還 漂亮', 'positive')像這句我就不認為是正面的
將這份語料庫做成特徵集
def pos_feature(sent):
i = sent
feature={}
words = sent2word(sent)
for w in words:
if w in sentment_dict.keys():
# feature[w] = sentment_dict[w]
feature[w] = w in pos_dict
return feature
def get_featureset(wb30):
featureset = []
for i in wb30:
sent = ''
for w in i[0].split():
sent += w
feature = pos_feature(sent)
if len(feature.keys()) > 0:
featureset.append((feature,i[1]))
return featureset
之前提取特徵每個單字後都是接True or False
我看樸素貝葉特徵是能放簡單字串後數字的,我就嘗試把TF換成情感強度
不過這樣跑出來準確度是0,分兩類精度在爛也要在50%附近,0%一定是代碼不對了
所以我還是改回TF,回傳的準確度有90%
到這裡還沒有加進否定詞字典進來
sent='我不覺得海豚非常聰明'
classifier.classify(pos_feature(sent))
'positive'
一旦出現這種句子我想錯誤率是100%了
為了準確抓住否定詞,需要考慮到詞性
import jieba.posseg as pseg
words = pseg.cut("我不覺得海豚非常聰明")
for word, flag in words:
print('%s %s' % (word, flag))
我 N
不 ADV
覺得 Vt
海豚 N
非常 ADV
聰明 Vi
這樣看來當ADV出現在否定字典當中,就得改變句子的情感標籤
雖然還想不到什麼反例,但我想信事情一定沒有這麼簡單
"我不覺得他不在乎"像這種句子可能得先整理句子結構
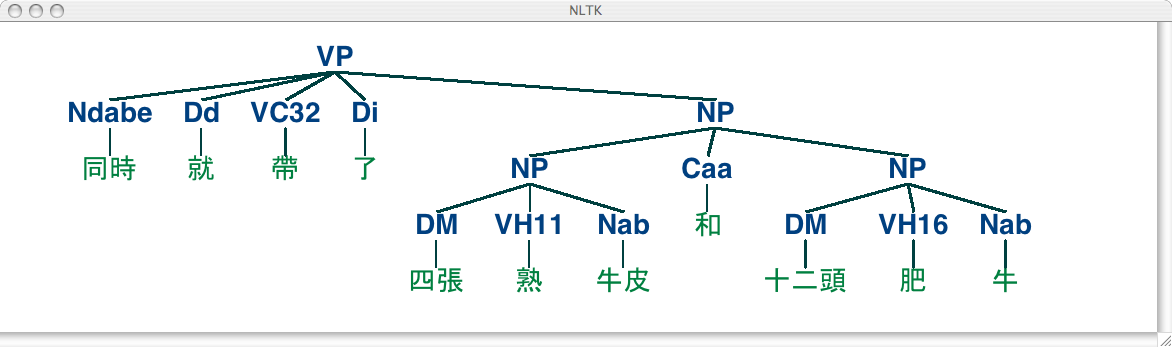
可能需要先確定否定詞位於哪裡,才能肯定對哪一區塊詞義產生反轉
但結巴標註的詞性與NLTK提供的詞性是不一樣的,需要使用前幾天寫到的nltk中文詞性標註,不過精確度只約在70%
哀...這些方法用下來,想想就能想出很多漏洞
參考資料:
结巴中文分词https://github.com/fxsjy/jieba
python实现中文字符繁体和简体中文转换https://blog.csdn.net/thomashtq/article/details/41512359
基于情感词典的情感打分https://blog.csdn.net/bcj296050240/article/details/46686797
Chinese Search Sharinghttps://blog.liang2.tw/2015Talk-Chinese-Search/#jieba-moedict
Python 自然语言处理 第二版https://usyiyi.github.io/nlp-py-2e-zh/


