本章的目的是要回答下列問題:
先來看書上舉的例句[ 'I' , 'shot' , 'an' , 'elephant' , 'in' , 'my' , 'pajamas' ],並且整理出CFG格式
箭號->右邊是左邊的分支
>>> groucho_grammar = nltk.CFG.fromstring( """
... S -> NP VP
... PP -> P NP
... NP -> Det N | Det N PP | 'I'
... VP -> V NP | VP PP
... Det -> 'an' | 'my'
... N -> 'elephant' | 'pajamas'
... V -> 'shot'
... P -> 'in'
... """ )
這個文法允許以兩種方式分析句子,取決於介詞短語in my pajamas是描述大像還是槍擊事件。
>>> sent = [ 'I' , 'shot' , 'an' , 'elephant' , 'in' , 'my' , 'pajamas' ]
>>> parser = nltk.ChartParser(groucho_grammar)
>>> for tree in parser.parse(sent):
... print (tree)
(S
(NP I)
(VP
(VP (V shot) (NP (Det an) (N elephant)))
(PP (P in) (NP (Det my) (N pajamas)))))
(S
(NP I)
(VP
(V shot)
(NP (Det an) (N elephant) (PP (P in) (NP (Det my) (N pajamas))))))
>>> grammar1 = nltk.data.load( 'file:mygrammar.cfg' )
>>> sent = "Mary saw Bob" .split()
>>> rd_parser = nltk.RecursiveDescentParser(grammar1)
>>> for tree in rd_parser.parse(sent):
... print (tree)
確保你的文件名後綴為.cfg,並且字符串'file:mygrammar.cfg'中間沒有空格符。
當你編寫CFG在NLTK中分析時,你不能將語法類型與詞彙項目一起寫在同一個產生式的右側。
因此,產生式PP -> 'of' NP是不允許的。另外,你不得在產生式右側仿製多個詞的詞彙項。
因此,不能寫成NP -> 'New York',而要寫成類似NP -> 'New_York'這樣的。
句法詞塊有一層層的遞歸關係,使用書上的例句
grammar2 = nltk.CFG.fromstring( """
S -> NP VP
NP -> Det Nom | PropN
Nom -> Adj Nom | N
VP -> V Adj | V NP | VS | V NP PP
PP -> P NP
PropN -> 'Buster' | 'Chatterer' | 'Joe'
Det -> 'the' | 'a'
N -> 'bear' | 'squirrel' | 'tree' | 'fish' | 'log'
Adj -> 'angry ' | 'frightened' | 'little' | 'tall'
V -> 'chased' | 'saw' | 'said' | 'thought' | 'was' | 'put'
P -> 'on'
""" )
>>> rd_parser = nltk.RecursiveDescentParser(grammar1)
>>> sent = 'Mary saw a dog' .split()
>>> for tree in rd_parser.parse(sent):
... print (tree)
(S (NP Mary) (VP (V saw) (NP (Det a) (N dog))))
RecursiveDescentParser()在分析grammar2的CFG結構是由樹自上而下分析。自上而下分析器在檢查輸入之前先使用文法預測輸入將是什麼!
遞歸下降分析有三個主要的缺點。
所以有另一種由下而上的分析器
一種簡單的自下而上分析器是移進-歸約分析器。與所有自下而上的分析器一樣,移進-歸約分析器嘗試找到對應文法生產式右側的詞和短語的序列,用左側的替換它們,直到整個句子歸約為一個S。
移位-規約分析器反復將下一個輸入詞推到堆棧;這是移位操作。如果堆棧上的前n項,匹配一些產生式的右側的n個項目,那麼就把它們彈出棧,並把產生式左邊的項目壓入棧。這種替換前n項為一項的操作就是規約操作。此操作只適用於堆棧的頂部;規約棧中的項目必須在後面的項目被壓入棧之前做。當所有的輸入都使用過,堆棧中只剩餘一個項目,也就是一顆分析樹作為它的根的S節點時,分析器完成。移位-規約分析器通過上述過程建立一顆分析樹。每次彈出堆棧n個項目,它就將它們組合成部分的分析樹,然後將這壓回推棧。我們可以使用圖形化示範nltk.app.srparser()看到移位-規約分析算法步驟。
執行此分析器的六個階段,如圖所示。
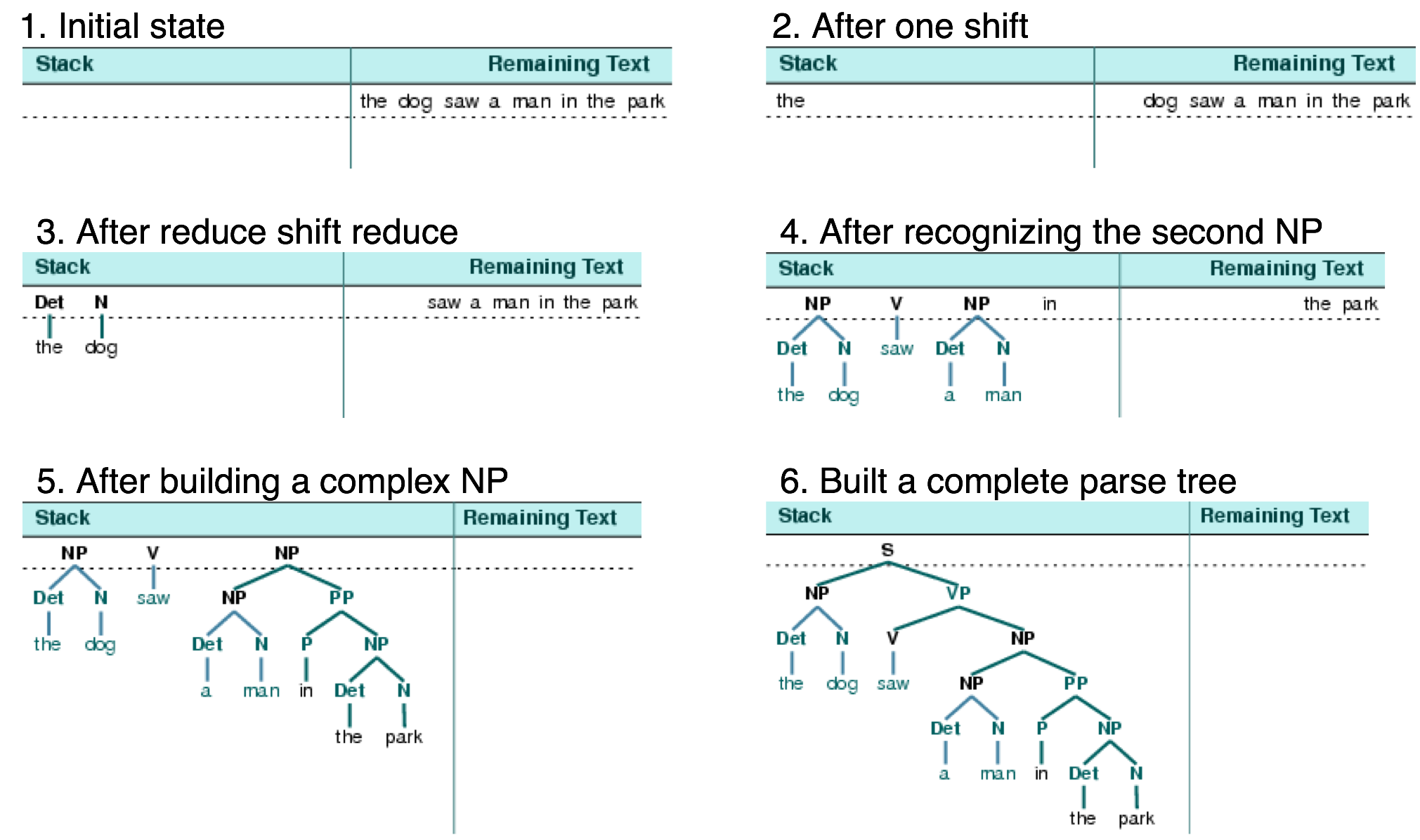
從這流程圖能看到是由單字開始組合成詞塊,由下而上可能過程在合併為更大的詞塊,直到出現樹根S完成歸約分析
還是很困惑這單元的流程是怎樣,在句法類型代碼還沒弄懂
參考資料:
Python 自然语言处理 第二版https://usyiyi.github.io/nlp-py-2e-zh/8.html


 iThome鐵人賽
iThome鐵人賽