Graph Database(圖數據庫)顧名思義是數據庫的一種,跟一般的數據庫不一樣的是,它的核心是數據之間的關係(Relation)而不是數據的內容。在GDB中每個數據(Data item)為nodes(節點),數據之間的關係為edges(邊)。適合有高度關聯性的數據,簡單來說,如果你在用RDBMS的時候需要用很多JOIN來query的話,GDB可能會是比較適合你的選擇。
說到RDBMS,大家都統一知道可以用SQL來Query它。但是GDB不一樣的地方是,目前它沒有一個行內統一的Querying Language,因此你用的querying language很多時候取決於你用來建立GDB的平台。有些GDB更可以透過API來存取。
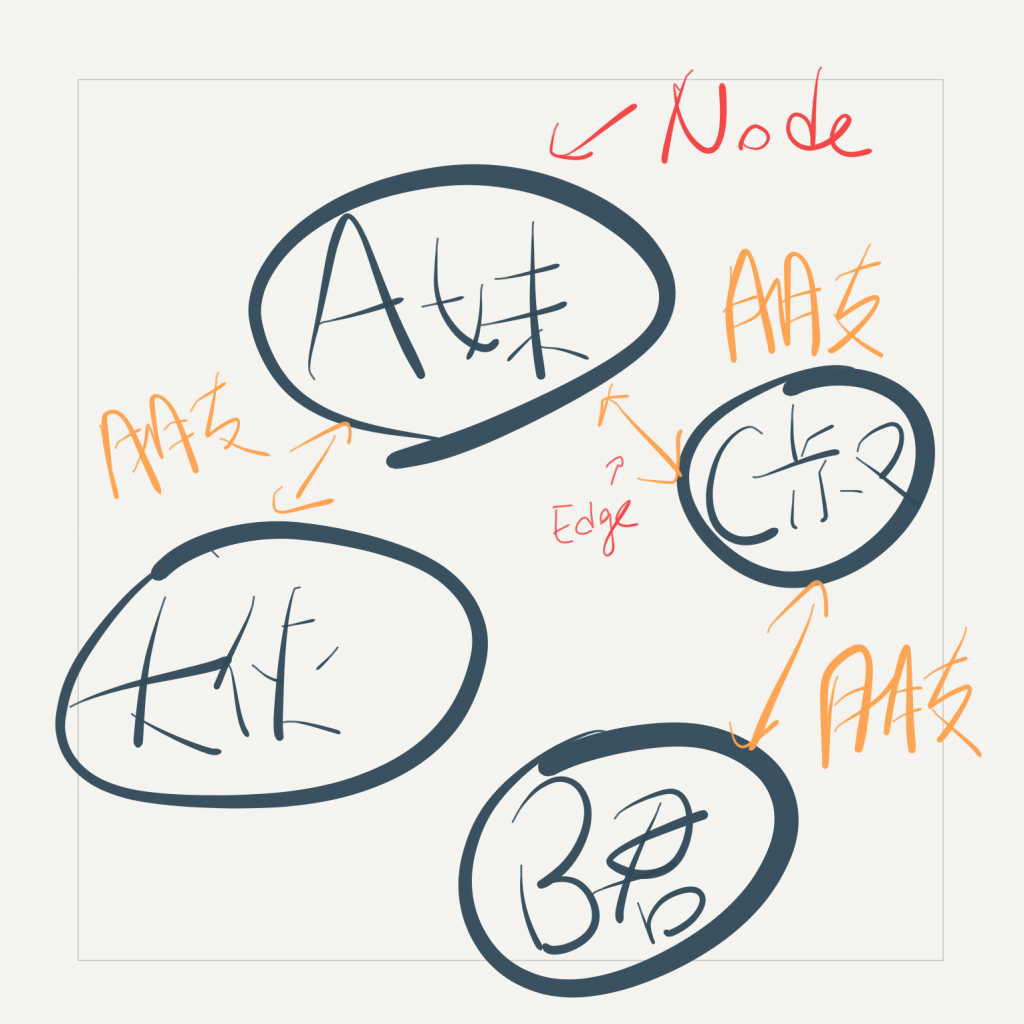
每個數據是Node,數據之間的關係為Edges,用來形容數據的Properties的格式為Key-Value Pairs。每一條Edge有兩項特質:有Start Node和End Node以及Directed(有方向)。有趣的地方是Edge也可以有屬於自己的properties。
GDB的根本概念為GRAPH(圖)。因此常用的Traverse Method就兩種:BFS(廣度優先搜尋)和DFS(深度優先搜尋)。
要找到跟一個NODE有RELATION的其他NODES,很簡單—— O(1) × Total Number Of Related Nodes
因此GDB的速度很快,但是也僅限於QUERY RELATION方面。
如果想要像SQL那樣“SELECT * FROM TABLE",就比較複雜了。
首先我們要找到NODE跟EDGE的關聯:
假設NODE的總數為N,
在一個GRAPH裡面,我們先隨意選第一個NODE A,A最多能擁有的EDGE為N-1,我們再選第二個NODE B,他能擁有的EDGE也是N-1,但N-1裡面有一條是連到A的,所以目前EDGE的總數為(N-1)+(N-2),當所有NODE能連上的EDGE加起來之後將會是:
(N-1)+(N-2)+(N-3)+...+0
=((N-1)+0)N/2
=N^2 - N / 2
= O(N^2)
SELECT * FROM TABLE代表我們需要經過所有的EDGES,
因此TIME COMPLEXITY將會是O(N^2)。
跟SQL比起來的話,可能還會更慢一點。
因此切記不能亂用GDB!用斧頭來砍樹當然是順手,但你用來切魚的話就不見得有多好用了。
比較常見的是Social Graph(社交圖?),Facebook和Twitter等等社交網站都得靠它。
一起來窺探A妹的人際關係。
下一回整體會講一下數據庫的進化史,將GDB跟普遍類型的數據庫進行比較,以分析哪種情況下才需要使用GDB。
謝謝看到最後的你。

