
AI是一個學門:AI是在研究如何建構一個機器,讓其行為近似於人類的學門。
ML是一個工具集:你可以使用ML來解決某部分AI的問題,但不是全部的問題。
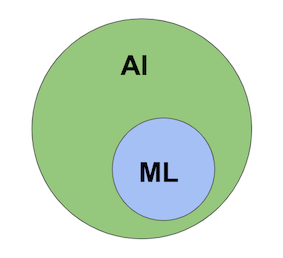
AI跟ML涵蓋的範圍集合可以簡單用下圖來表示:
第一階段(Training):使用資料來訓練模型
這邊我們指的是所謂的監督式學習(supervised learning)的方式,簡單來說是資料會有輸入(x)和對應的答案(y),模型本身是一個複雜的函數形式(function form),而學習的東西則是函數的參數(weights/parameters),這樣的學習方式就稱為監督式學習。
第二階段(Prediction):使用訓練好的模型來做預測
當模型訓練好後,便會得到一組訓練後的參數,此時給進一個新的輸入(x'),模型就可以預測或推論(prediction/inference)出一個答案(y')。這個階段在學術上是比較容易被輕忽的,若是要建構一個ML產品服務大量的使用者,那麼快速又準確的預測是必須重視的環節之一。
在建構一個ML產品的時候,必須要同時考慮這兩個階段的資料流(Data flow),意即訓練時使用處理資料的方式要和預測時的相同,這才不會造成在訓練階段,模型的效果不錯,但到了預測時,精準度變差的情況發生。
在Google的產品裡面,使用最多的ML模型就是神經網路模型,這類型的模型在近年來快速的發展,並在許多問題上如影像辨識、序列問題、推薦系統,都有著非常強大的解決問題能力。
這些模型被用在包含如YouTube 、Play、Chrome、Gmail、Hangouts...等產品上,而且一個產品內會使用多種ML模型來解決問題,舉幾個實際應用場景的例子來說:
以上這些應用例子都是每天發生在你我日常生活之中的。

ML既然可以用在這麼多地方,自然地會想問說:什麼時候適合使用ML呢?答案就是任何使用經驗法則的地方都可以。例如說在程式當中加入很多的經驗條件,往往一發現有例外的狀況就要再額外加入新的一條規則,此時若使用ML模型便可以達到自動化、規模化和個人化的解決方案。
當手上資料量很小的時候,經驗法則或許堪用,然而當資料收集到越來越多的時候,人類訂定的規則將會變得很難維護且繁雜,一切的關鍵都和資料有關!能將大量的資料轉變為知識,這就是ML強大的地方。
一個常用的比喻就是:ML若是火箭的引擎,那麼資料便是燃料。當收集的資料越多(不僅僅在數量上,而是資料種類也隨之增加),那麼建構出的ML模型將更為精準且實用。
當在建構ML產品的時候,與其慢慢地做期望達到成功,更有效率的方式是快速的失敗,藉由在短時間內完成建構模型,提供結果預測,測試市場反應的週期循環,將能快速的累積經驗並達到真正的成功。
而公司的業務大致在三個方面上,可以藉由使用ML來獲益:
今天介紹了 AI-first 的重要概念,包含了AI與ML的差別、ML的兩個階段、什麼時候該使用ML,以及使用ML的策略應該是如何,了解其代表的意義,明天我們將介紹 “Google如何使用ML”。

 iThome鐵人賽
iThome鐵人賽