什麼是資訊檢索呢?大家最清楚的例子莫過於網路搜尋引擎了。當你在Google Search上輸入一段你想查詢的字,作為一個使用者通常會跟搜尋引擎有以下的互動:
(i) 在你輸入的同時,提示你有哪些可能的搜尋選項,通常是熱門字或時事提供你選擇。
(ii) 當你按下Enter後,不到半秒時間,根據排名回傳給你一些可能是你需要的文件。
(iii) 若你覺得這個文件不是你所需要的,你可能會再往下一個文件搜尋,也可能修改查詢的字後重新查詢。
事實上,從檔案的搜集、建立索引,使用者在輸入時提供查詢推薦,到根據你的查詢回傳文件索引,在使用者開始查詢之前,搜尋引擎早就已經在運作了。
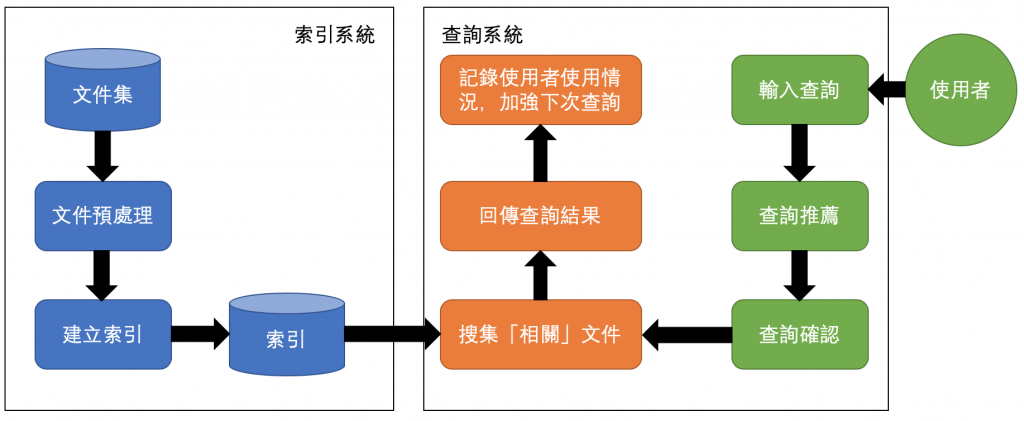
以上就是一個基礎資訊檢索系統的運作流程:
在索引的部分先將搜集來的文件進行預處理(前置處理),再來建立索引。常見的索引建立方式包含文件矩陣 (Document-Term Matrix)、倒排索引 (Inverted Index)和位置索引 (Positional Index),關於預處理和這幾種索引方式會在之後的文章中詳述。
查詢時,我們會依照使用者輸入的查詢來為文件進行相似度加權(文件和查詢之間的相似度),最常見的兩種加權方式分別為TF-IDF以及BM25,最後根據加權後的相似度總值回傳最可能「相關」的文件。
值得留意的是,資訊檢索最主要的任務是要找出使用者的「資訊需求」,而不是僅僅找出使用者所輸入的字。相信我們也都有經驗,我們腦中有一個資訊需求,但我們不確定如何表達,但再一次又一次的改進查詢之後,我們真正需要的資料就浮現在搜尋當中了,這就是搜尋引擎成功找出我們資訊需求的過程。為了幫助使用者更快找到資訊需求,搜尋引擎會用「查詢推薦(查詢完全)」、「查詢擴展」等方式來強化回傳的搜尋結果。
明天開始將有一系列圍繞在搜尋引擎技術的介紹和實作,敬請期待!
現在業界最常用的是ElasticSearch和Lucene(Python也有PyLucene,不過蠻多bug的),可以考慮寫一些教學文!
這次的系列文我會先介紹背景技術,可能寫完三十篇之後會來寫一些教學文!的確PyLucene在安裝時會很痛苦,只要環境沒設定好就要砍掉重練了,還是用Java寫Lucene就好了。


 iThome鐵人賽
iThome鐵人賽