昨天說到語言模型,今天要來介紹另一個模型--主題模型(Topic Model)。主題模型能夠幫助人們短時間理解原本幾乎不可能讀得完的大型非結構化的文集,例如科學文獻、許多的部落格等,其主要的任務就是找出大型文集中潛在的主題。主題模型有兩個假設:(i) 每個文件都混合著多個主題,(ii) 每個主題由多個字所組成。
根據不同的數學理論,主題模型的實作方法分為三:Latent Semantic Analysis (LSA)、Probabilistic Latent Semantic Analysis (pLSA) 以及Latent Dirichlet Allocation (LDA)。
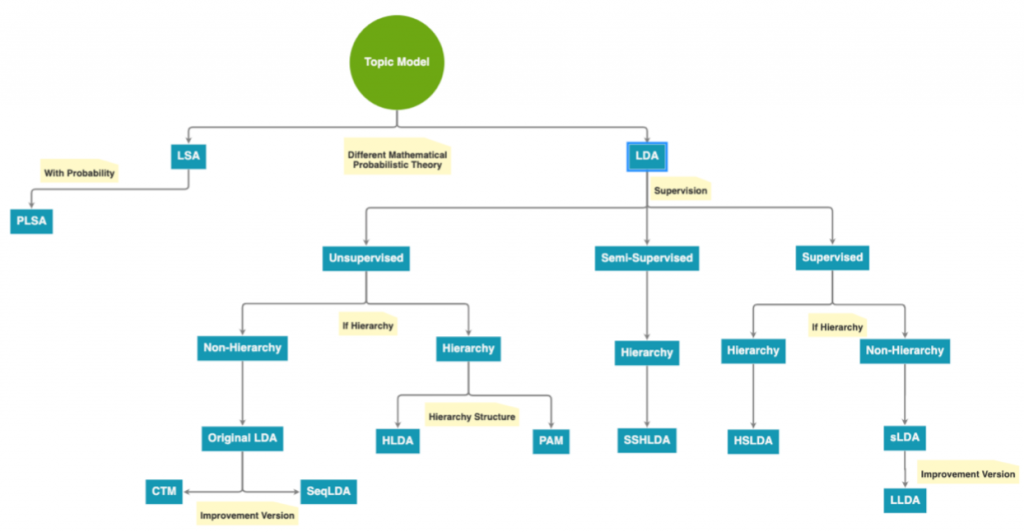
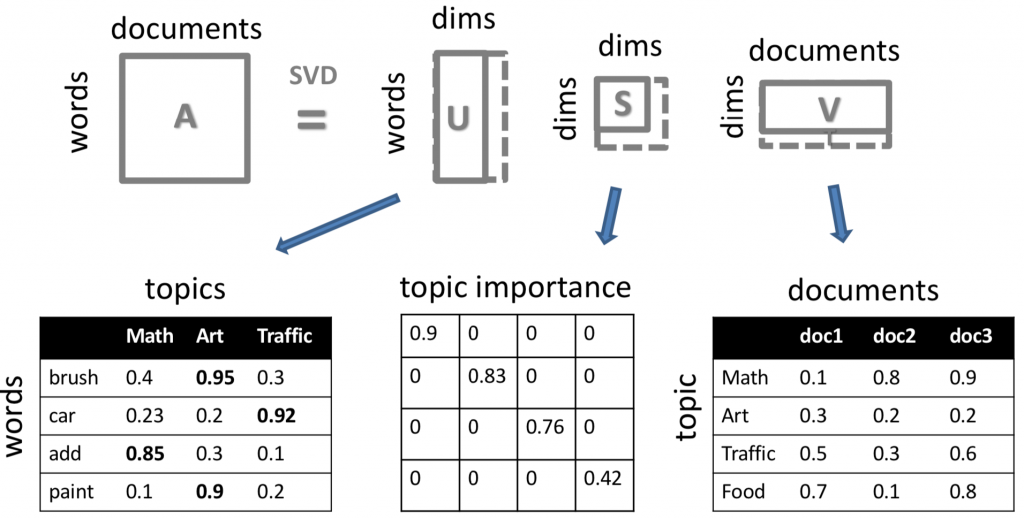
LSA主要比對了每個字與主題的關係(U)和每個主題和檔案的關係(V),如同下圖,”brush, car, add, paint”是每個曾經出現在文集中的字,”Math, Art, Traffic, Food”是可能的主題類別,而doc1, doc2, doc3則是每個文件。LSA的數學模型基於線性代數中的奇異值分解(Singular Value Decomposition),pLSA則在LSA的架構上加上了機率學,然而,pLSA容易出現過適的問題。之後,LDA在pLSA的基礎上加上貝氏定律,LDA和其演化版本們也是現在最主要主題模型的實作方法。
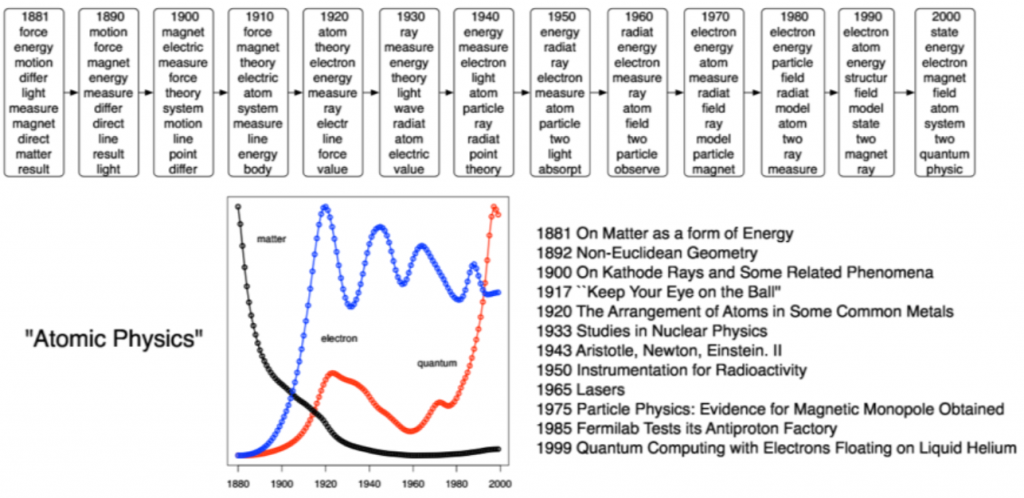
主題模型可以應用的層面非常廣,包含歷史資料(如:一百年來的報紙、十八世紀的日記等)、自然科學研究文章、社會科學研究等。針對這些應用,也有幾個重要課題像是怎麼將這些模型視覺化、如何讓非電腦科學背景的人更直觀的理解模型。
舉些實際應用上的例子:在下面這張圖中,我們可以知道隨著時間的推進,在原子物理學領域中研究主題的變化。
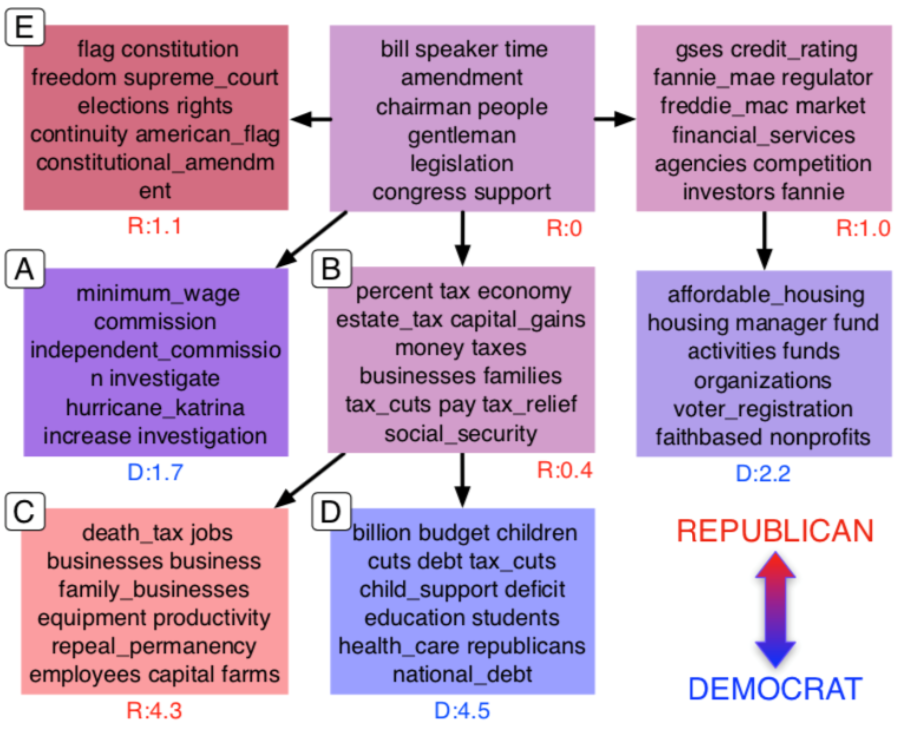
下圖中我們也能了解,美國兩大黨派對於各項議題的政治光譜。
明天我們會把重心轉到資訊檢索,也就是如Google這種搜尋引擎之基礎技術的由來~
我想請教,如果我要做50年的主題模型,我是不是非得一次針對50年的龐大資料做主題模型,而不是每次只做5年的主題模型,最後再湊起來?因為感覺前者是不是會跑好久?
有些library可以讓你把資料分割下去跑,最後再湊起來,但湊起來之後也還是要花時間。不過跑很久其實還算小事,龐大資料處理上比較怕的會是記憶體問題。之前處理幾十GB的dataset,努力壓縮跟分割資料之後,在最後階段製作模型時還是吃掉了60~70GB的RAM。那次開tmux讓研究室電腦不斷電的持續運算,整個實驗流程大概跑了一週多。


 iThome鐵人賽
iThome鐵人賽