
這大章節課程影片一堆,很多內容都和標題卻和想像中有點差異,以為會是講些觀念或理論,但大多還是介紹Google如何做?或是做了什麼?這樣的內容沒有說不行不好,可是看多了會膩。
原本前面還有一章主題是 pre-trained model,結果內容其實主要是說google有一堆各式各樣幫你訓練好的model,你可以直接調用,讓我覺得這門課想訓練出的也不過是新型態的"工人",也或許在進階課程中會有更多討論。

這章又說一堆前面已經講過的老話,反正就是 more data, more powerful,另外就是,大量的資料所建構出的簡單模型,會比在少量資料下的複雜模型更好,用碎形進行比喻真的是說不出的奇妙,可是想想也蠻符合的,畢竟這些碎形圖案的確是依循簡單的規則遞迴疊代產生。
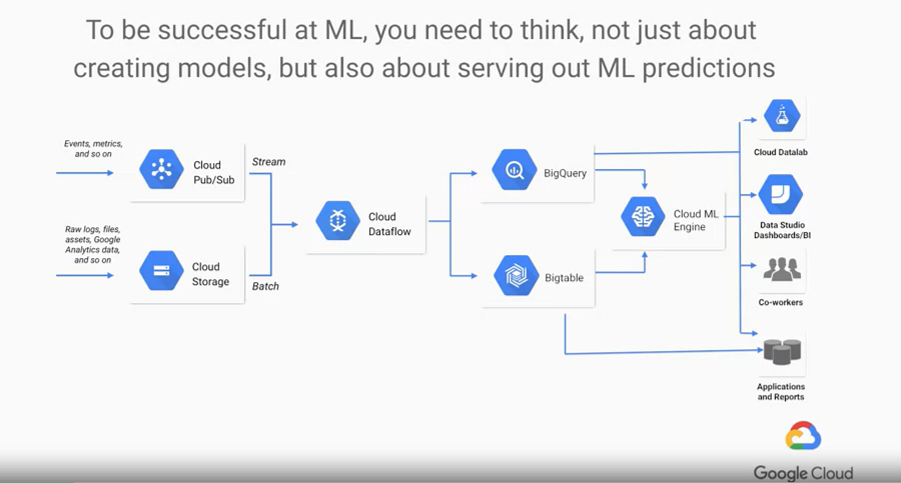
這章節則是討論,訓練模型與實際應用的差異,從學校出來的學生或研究員,的確非常缺乏對於將模型佈署到實際場域中的經驗。相較於固定的資料集,實際場域中需要對應源源不絕的原始資料,因此,首要目的就是"自動化",自動化蒐集資料、自動化解析資料(轉換成模型能夠使用的形式),另外,資料流的控制也非常重要,從最前端(edge)到雲端(cloud),如何確保資料流動的穩定、流量、安全性等,最後,資料如何被儲存、資料視覺化呈現、應用端互動等,這一套完整流程Google cloud都有相對應的服務可以使用。
這邊提出一項建構Machine Learning專案的策略,比起單一強大的模型,Machine Learning更適合被以多個簡單的模型來使用,因此,能夠不斷失敗、快速重複進行建構的環境會非常適合。
另外,這章節主打Google強大的工具就是,能輕易的將非結構化的資料經由Google的API轉換成結構化的資料,希望未來的課程能用到這項服務進行練習。

 iThome鐵人賽
iThome鐵人賽