在Day 6的文章中,我們說到在進行搜尋時,我們首要關心的是查詢的詞與文件間的相似度。我用一個例子作為開端:假如我們有三個檔案,分別叫做doc1, doc2以及doc3,而檔案由以下的文字組成。

為了獲取相似度,我們需要知道每一個文件裡面有哪些字,才能比較查詢與文件之間相似不相似。我們可能想知道這個文件裡面有或沒有這個字(二元,0或1),也可能想知道這個文件裡面出現該字的頻率(詞頻,0或多)。假如我們想知道詞頻,那我們就可以畫出此矩陣:
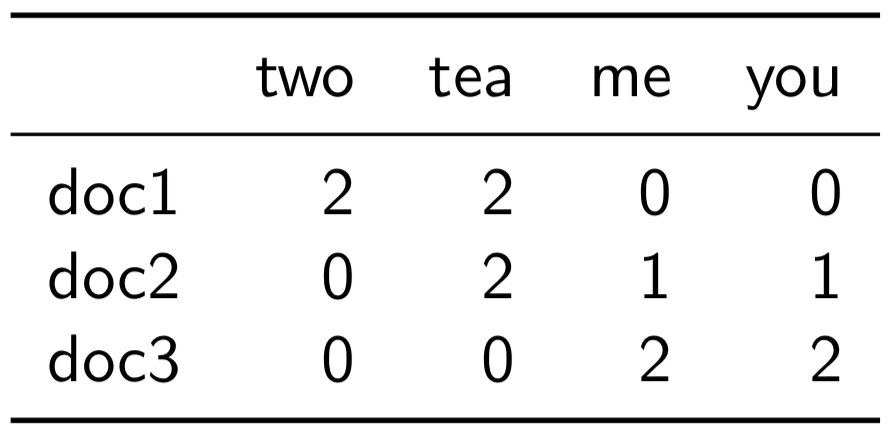
這個矩陣就稱為文件矩陣(Document Term Matrix, DTM)。在空間中,矩陣看起來像這樣:
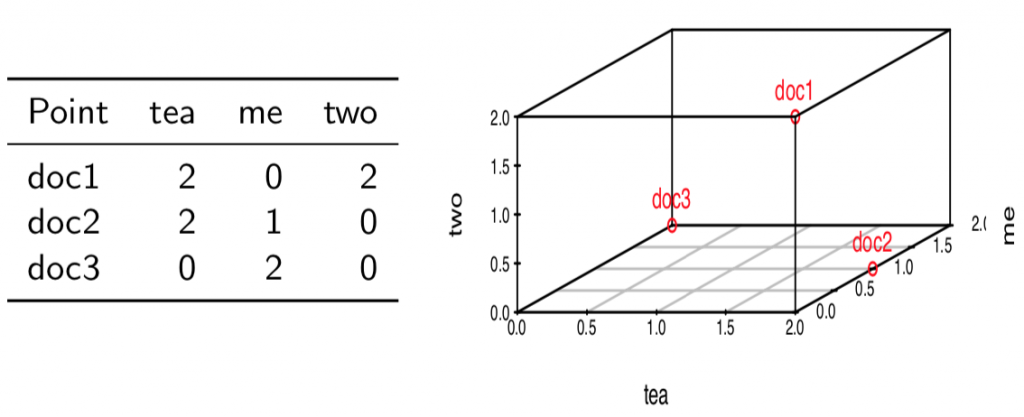
每個詞會成為一個維度,因為正常人在面對三維以上個空間頭腦會爆掉 (可以試試看這個XD),所以我只用三個詞來做出一個三維空間。接著,若要求出文件與查詢的相似度,我們會使用Cosine Similartiy。
現在要來說說DTM的缺點:DTM一個最主要的缺點就是在矩陣中會有很多0,造成多餘的空間消耗。多餘個空間消耗會產生很多問題,除了搜尋效率的本身,多餘的空間消耗也會使原本能存更多索引在記憶體中的部分,不得不存到硬碟當中,其中資料IO的速度會拖累搜尋的速度。因此,DTM被改造成倒排索引(Inverted Index)。
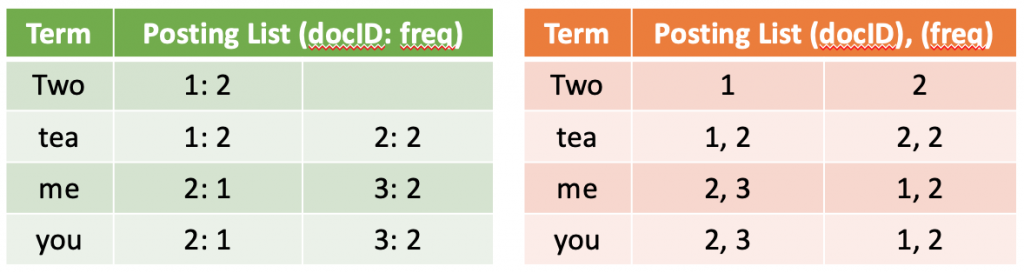
以上是兩個矩陣都是倒排索引的不同表示法。左邊將文件編號與詞頻作為一組擺在一起,右邊則將編號寫在一起,後面再接著各個文件中該詞的詞頻。
明天的文章中,我們將實作倒排索引 -- Inverted Index。


 iThome鐵人賽
iThome鐵人賽