
如果一個迴歸模型的RMSE是0,這麼“準”的模型會是好的模型嗎?答案是否定的,這通常表示著它的泛化能力不好,也就是在沒見過的資料上它將沒辦法準確的預測其答案。
舉例來說,現在有一筆資料,使用線性迴歸模型來擬合如下圖:

這時候若使用更多參數的複雜模型,達到了每個點都準確預測,RMSE變成0,如下圖示:

然而這樣的模型我們不會認為是一個好的模型,若今天新進一筆資料,很大的可能是它沒辦法預測到正確的答案,這種現象我們稱之為過擬合(Overfitting)。
要解決這樣的問題,可以將資料分成2組:訓練組和測試組(Training and Testing sets),測試組的資料並不會用來訓練模型,使用訓練組資料訓練模型後,得到訓練組RMSE並和測試組RMSE比較,數值差不多時,這樣的模型表示泛化能力較好。
使用過多的模型參數來擬合資料會有過擬合的現象,然而太少的模型參數會造成欠擬合(Underfitting),挑選適當的模型架構、參數便是ML訓練過程中的一個重點。

那麼模型的架構,或者說超參數要怎麼選擇呢?答案是把資料多分1組出來,變成3組:訓練組、驗證組和測試組(Training, Validation and Testing sets)。新增的驗證組就是用來挑選超參數或者模型架構,當訓練完後的模型,在驗證組上算RMSE,比較不同超參數或模型架構之間驗證組RMSE的大小,挑選最好的模型後,再看看測試RMSE是否維持相近的大小,整個訓練過程如下面圖示。


不過這樣你可能會想到一個可惜的地方,就是測試組的資料好像沒有被完全利用到,只有拿來看看RMSE而已,沒錯,這樣確實有點浪費這些寶貴的資料,所以我們可以訓練完後,再重新切分訓練組、驗證組和測試組,然後再來訓練一次,如此重複多次後,便可以完整使用到全部的資料來訓練模型,這種方式我們稱之為自助法(Bootstrapping)。
在上面我們提到了訓練模型前,需要將資料切分,無論是切2或3份,接著會想到的問題是如何分割資料?當資料很巨大的時候該怎麼切分?怎麼確定每次切分的結果都一樣?
一個直觀簡單的想法就是隨機(Random)切成2份,80%訓練/20%測試這樣,但是這樣切會有個問題,就是別人無法重現你的實驗結果。那你又會說:“沒關係,我把分好的資料另外存出來,這樣其他人就可以用這個另外存出來的切分資料來跑”,這雖然是一種辦法,但是如果今天資料又要擴充、增加呢?如果資料很大,這不是又多浪費空間存這2份資料嗎?
所以,下面的實作將介紹的一種實用的切分方法,使用雜湊函式(Hash function)將資料進行分割。
在這個實作中,我們可以學到:
登入GCP,步驟可以參考Day5的文章。
在 Navigation Menu,選取 AI Platforms 裡面的 Notebooks。

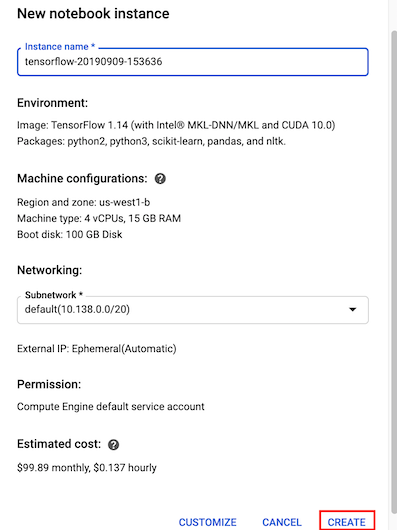


git clone https://github.com/GoogleCloudPlatform/training-data-analyst


Rand() 的時候,每次重複執行該cell都會得到不一樣的alpha值。但是透過將日期丟進雜湊函式的方式( FARM_FINGERPRINT(date) ) ,我們就實現了可重複的資料分割,每次重跑alpha的值都會是固定的了。

今天介紹了泛化和取樣的重要和1個簡單的實作,明天我們將繼續另一個實作 “探索和創造ML資料集”。

 iThome鐵人賽
iThome鐵人賽