強化學習是什麼東西,它好吃嗎?
當然不能(不好意思這裡不是IT美食30天XD)
你可以想像它是個連貫性決策過程,是連貫就會有個開始跟結束(有些例外假如是要用在外太空探測的無人機),電動遊戲、博弈之類,或機器手臂、無人機... 這些過程都有些目的,目的中間可能又包含無數個小目標,目標還有主要目標、次要目標。但最終我們顯然在心中可描繪出理想畫面,例如玩RPG遊戲目標是要破關、博弈目標是戰勝對手、無人機想安全落地...
話說如果明年如果來寫個alphago戰勝柯潔,標題就可以寫-完爆人類30天XDD
剛講的那幾個範例,都是可定義個明確目標,那接著我們就根據目標設計算法~ 不過在這之前,我們必須先來聊聊代理人(Agent)與環境(Environment),兩者在強化學習裏擔任什麼角色,以及他們怎麼互動的。
執行代理人,它是演算法的代稱,演算法可能有DQN、DDPG...負責接收環境的資訊(可以想像遊戲畫面或圍棋棋盤),然後輸出一個執行動作(前、後、跳躍)。
環境,負責接收動作,然後輸出資訊,資訊包含著下一步的資訊、即時獎勵、結束與否。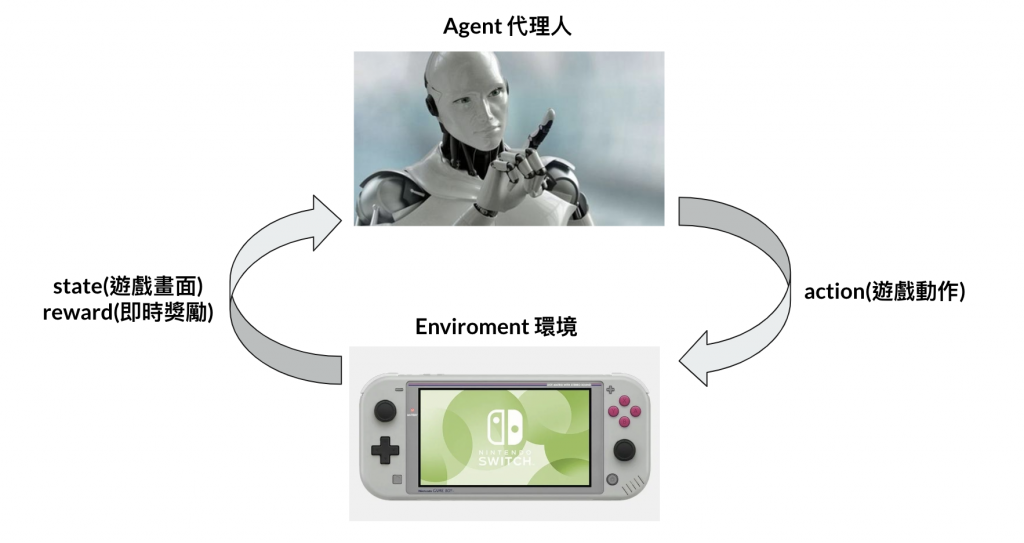
補充:即時獎懲在接下來我們都會稱做獎勵或reward,該局結束與否的變數叫terminate。如果teriminate是True,代表結束,有可能是到終點或game over,是一個回合(episode)結束,則新局即將開始。
整個互動就是Agent跟Environment交替拉,Agent接收到遊戲畫面然後輸出下步動作,Environment接收到Agent的動作後,會輸出訊息,包括畫面與獎懲值。這邊補充下,獎懲值是由環境制定,例如:
1.我們希望馬力歐跑努力跑向終點,距離終點越近給的獎勵越高。
舉例:假設起點離終點距離=x, 馬力歐離重點距離=y,則我們可以設定:reward = x - y ,越往終點移動得到越高獎勵(這樣模型就會很積極向著終點移動)
2.五子棋,平常不給reward,而是直到5顆一起才給獎勵值。
3.走迷宮遊戲,只要移動就給負的reward(不希望agent在原地滯留太久,趕快找出終點~)。
怎麼去設計獎懲值是case by case,正的獎懲值作為,負的則可以作為懲罰。正負跟值的大小都沒有明確規範,許多都可靠直覺常識再慢慢累積經驗。

希望大家能對agent與environment有個初步認識!你能想像到的遊戲理論上都可以靠強化學習解決~好了我們下一張開始來建置環境,準備些強化學習的前置作業囉!


 iThome鐵人賽
iThome鐵人賽