
今天來介紹第2個模組吧。
首先,講師提到許多人都會問AI與ML有什麼不同,而簡單來說,AI是理論或方法論,而ML則是工具或演算法。換言之,我們為了達成用AI來預測結果,其中會使用到ML的技術,同時也有可能會使用到不是ML的技術來達成,例如專家系統等,但ML與這些系統有一個主要的差異,ML是透過機器自行學習,其他工具則是透過蒐整過的情資來進行判斷。
在ML的第一個步驟是要利用資料來訓練出一個ML模型,也就是要開始讓ML模型學會如何判斷我們要的結果是什麼。學習方式分為兩種,監督式學習及非監督式學習,前者是利用已知的資料及標籤來訓練模型,後者則是相反。在這邊以圖形判斷作為例子,我們透過提供大量已有標籤的圖片,讓模型先去學習,並在學習後有能力透過分析圖片像素來判斷未含標籤的圖片裡是什麼動物。
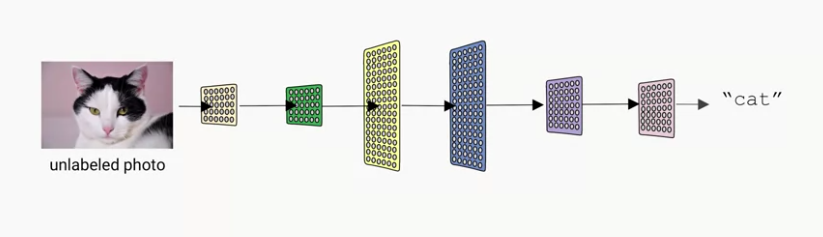
ML有兩個重要的階段,訓練及推論,許多人投入了大量的時間在執行資料訓的部分,卻忘了要讓訓練出來的模型能夠實際被應用才是最重要的事情,而ML想達成的目標並不是去猜測結果,而是透過已知的事實,去推論出應有的結果。
在訓練模型的過程中,可能不只有一個演算法在其中,通常是透過很多層的演算法才能得到最後的結果,進一步來說,要推論一個結果,也可能會應用到多個ML模型,而Google也運用這樣的概念在他們許多熱門的產品中。舉例來說,如果使用Google翻譯的相機翻譯功能,也就是利用相機照想要翻譯的文字,Google就有辦法幫你自動把文字翻譯好,接著從相機鏡頭就可以看到翻譯好的文字取代目前文字這個酷炫功能,對Google來講,要做到這件事情其實裡面包含了非常多層的模型,從判斷鏡頭中文字、判斷文字字型、得到翻譯、修改鏡頭畫面並將翻譯後之文字取代原始文字等,是透過這麼多個模型才有辦法得到最後結果的。
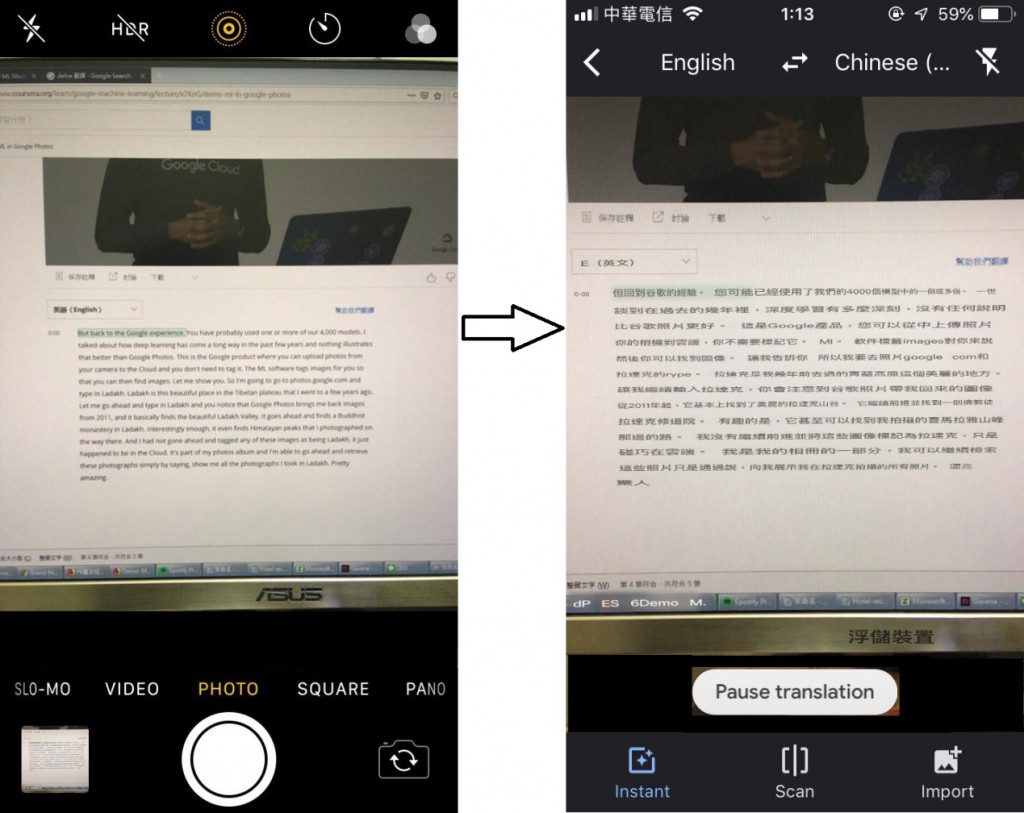
除了這個功能外,包含Gmail、Google照片等也都應用到了許多ML模型,也讓人深深感受到,這些產品能這麼成功真的不是運氣好而已,而是真的有下苦功在裡面的,順帶一提,Google目前已經開發有超過4000個ML模型可以運用,真的是非常驚人啊!
好的,今天先介紹到這邊吧,明天再繼續模組2的下半部分囉。
