怎麼把大象放入冰箱?
打開冰箱門、放入大象、關上冰箱門,
其實就是這麼簡單三步驟,
那怎麼進行機器學習,分為七大步驟。
The 7 Steps of Machine Learning (AI Adventures)
e.g. 假設今天想要創建一套分類系統,
來分辨此飲料,是啤酒,還是葡萄酒?
為了「訓練模型」而收集資料,
且資料都要「數據化」讓電腦能讀懂。
e.g. 先蒐集啤酒和葡萄酒的「特性(Feature)」資料,
例如泡沫量、玻璃杯形狀、顏色(光波長數據)、酒精(百分比)...等,
這個範例挑選「顏色(光波長數據)、酒精(百分比)」兩個特性來評估。
現在就到賣場買大量的飲料,並透過些檢測儀器來得到數據吧!
| 顏色(nm) | 酒精(%) | 啤酒or葡萄酒 |
|---|---|---|
| 610 | 5 | 啤酒 |
| 599 | 13 | 葡萄酒 |
| 693 | 14 | 葡萄酒 |
透過直線圖、分佈圖等「視覺化圖性」,
來看看「不同特性是否存在相關性」,
觀察是否有異常數據,例如空值、離群值、眾數,
也檢查各種資料的分佈情況使否合理。
e.g.若我們蒐集比較多「啤酒資料」,
有可能就會影響模型,比較偏重在「啤酒」上。
資料可能會被特殊調整,例如複製、正規化、糾正錯誤等。
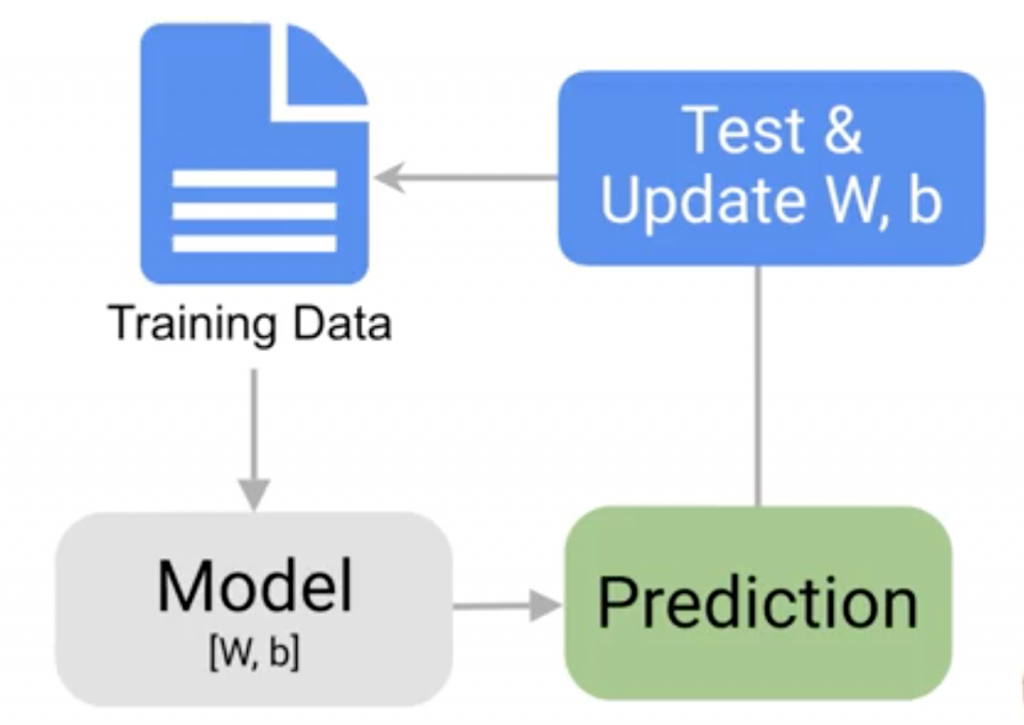
將數據分成兩群「Train Data」和「Test Data」,
「Train Data」為大群資料,用來訓練模型,
「Test Data」為小群資料,用來測試「訓練完模型」的性能。
不將所有數據都放進去訓練模型,是為了避免「記憶行為」。
有很多模型被已建立,
有些適合圖像數據,
有些適合序列資料,例如文件和音樂,
有些適合數字數據,
有些適合文件數據...等。
e.g. 這個範例,因為只有兩個特徵,故選用「小型線性模型」。
有點類似「訓練駕駛員」的一連串行為,
熟練他們的駕駛能力,在磨練他們的技能。
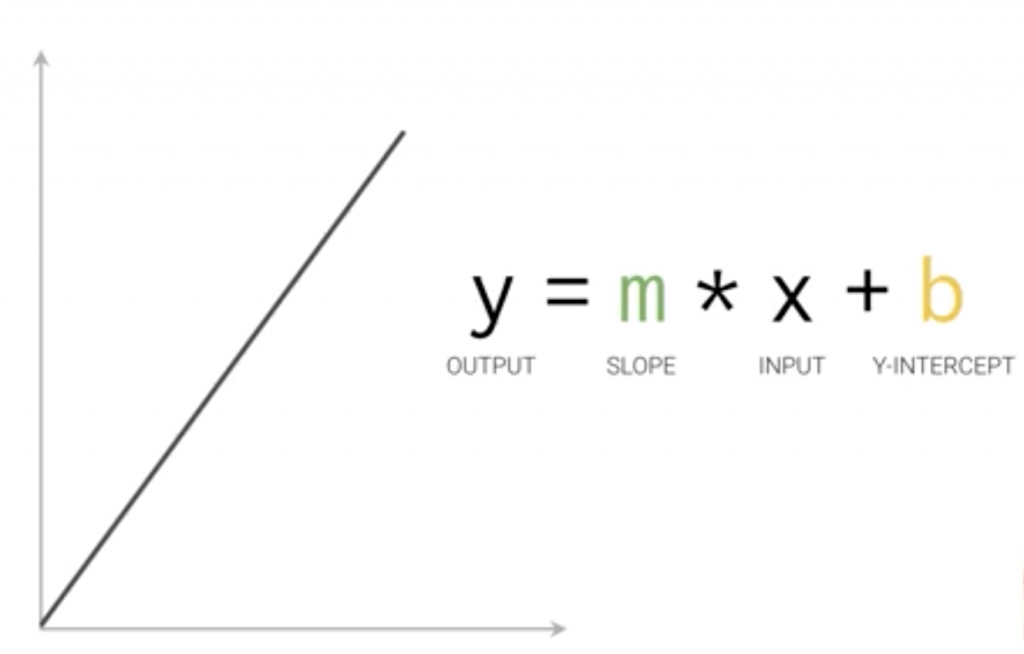
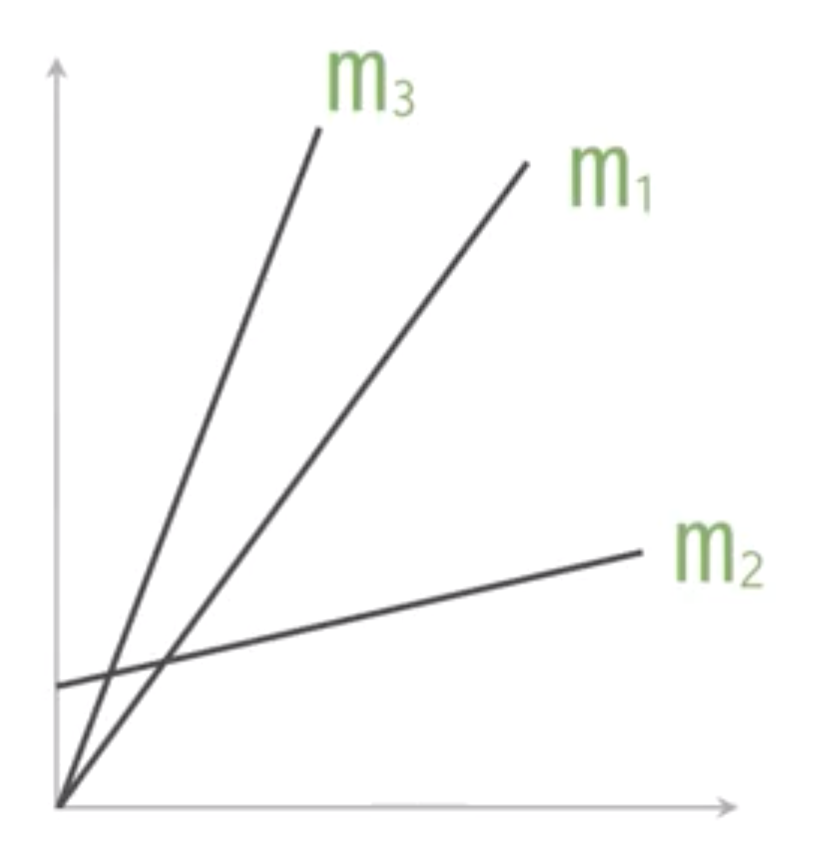
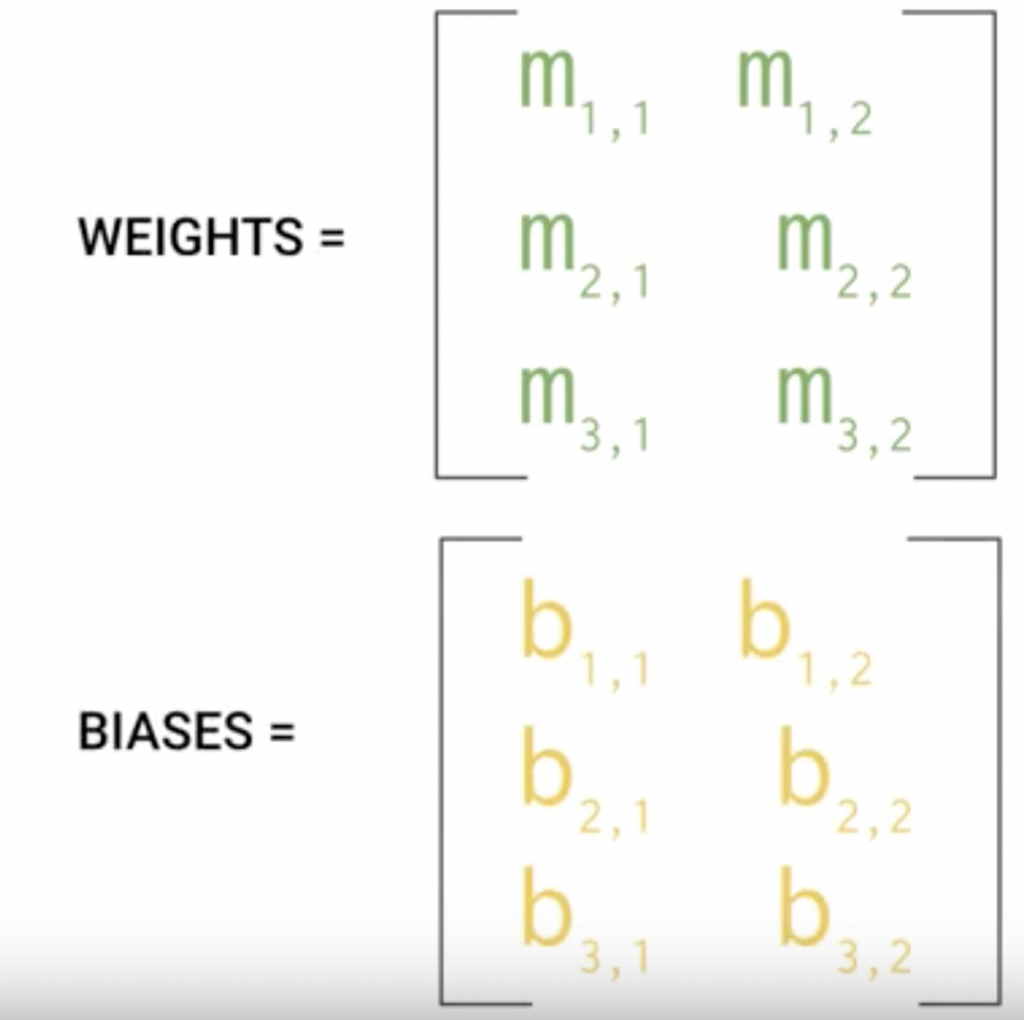
e.g. 以這個範例來說,我們畫的線性圖型,
會隨著一次一次的調整W和b,達到最適合的情況。
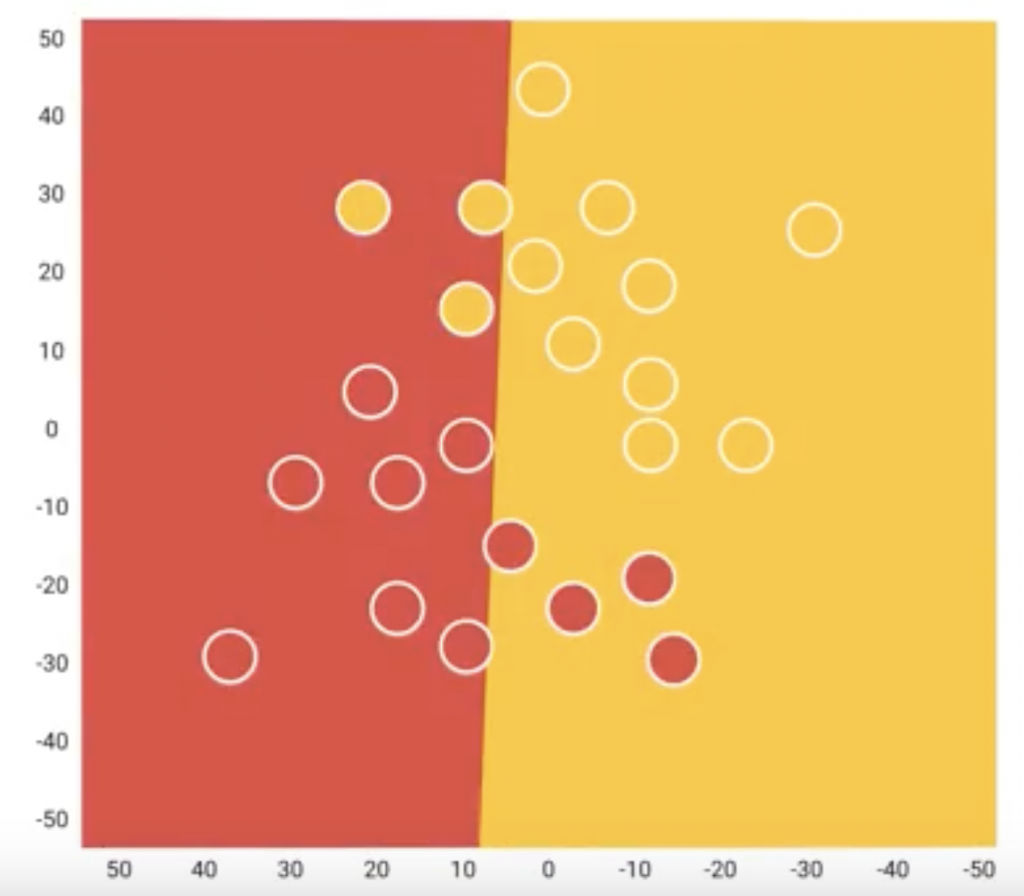
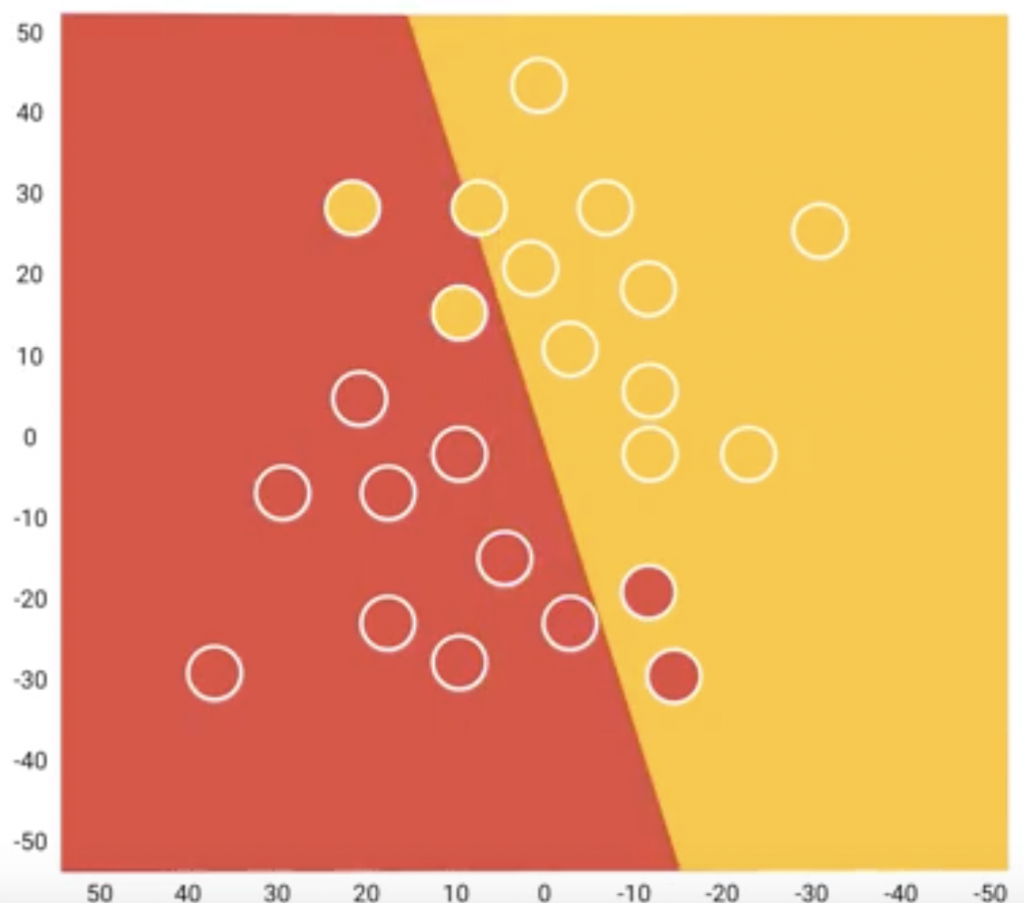
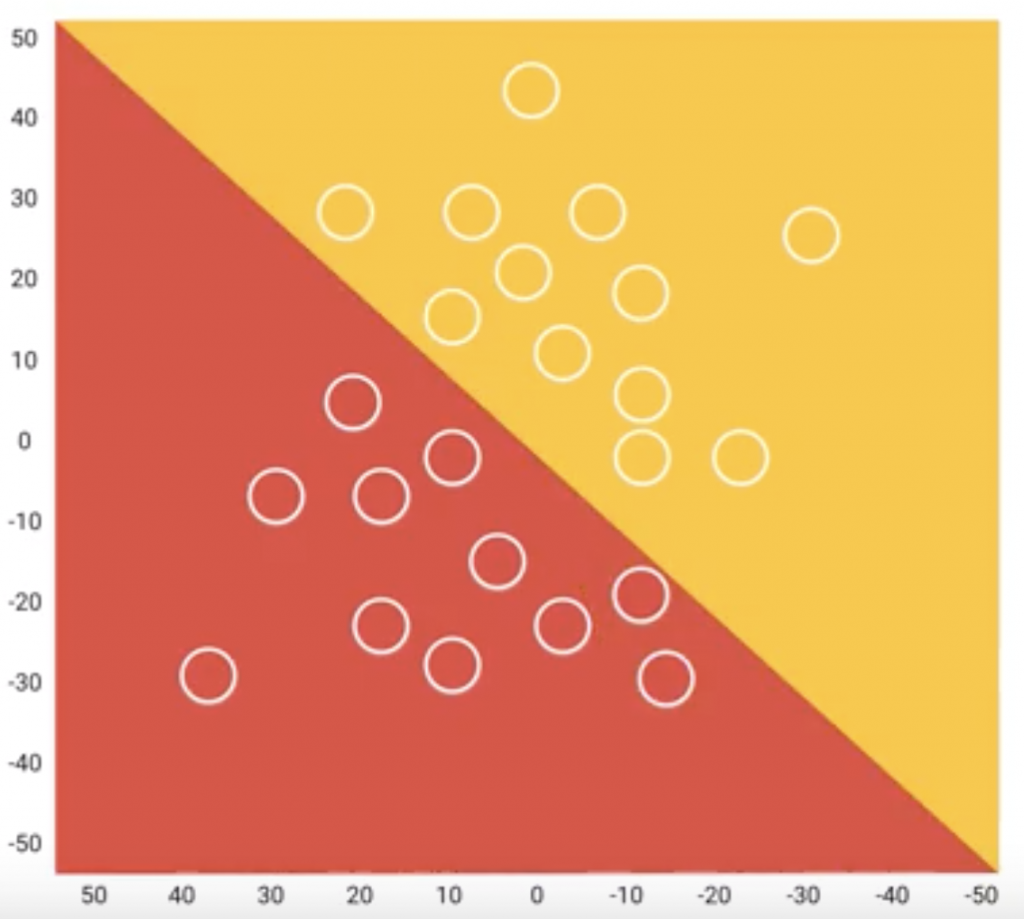
使用「Test Data」來評估我們訓練出來的模型,
讓模型試試看從未看過的資料,
通常會使用「混沌矩陣」評估。
數據分割通常為80/20或是70/30,
取決於資料量的大小。
可以解決「前提假設」,透過「參數調整」驗證這些假設。
多次的訓練中,我們可以看到很多次的訓練結果數據,
如此可以帶來更高的準確性。
「學習率」我們每次調整參數的線性移動,
根據前一個訓練步驟訊息來移動「線的距離」,
有想精準率和訓練時間。
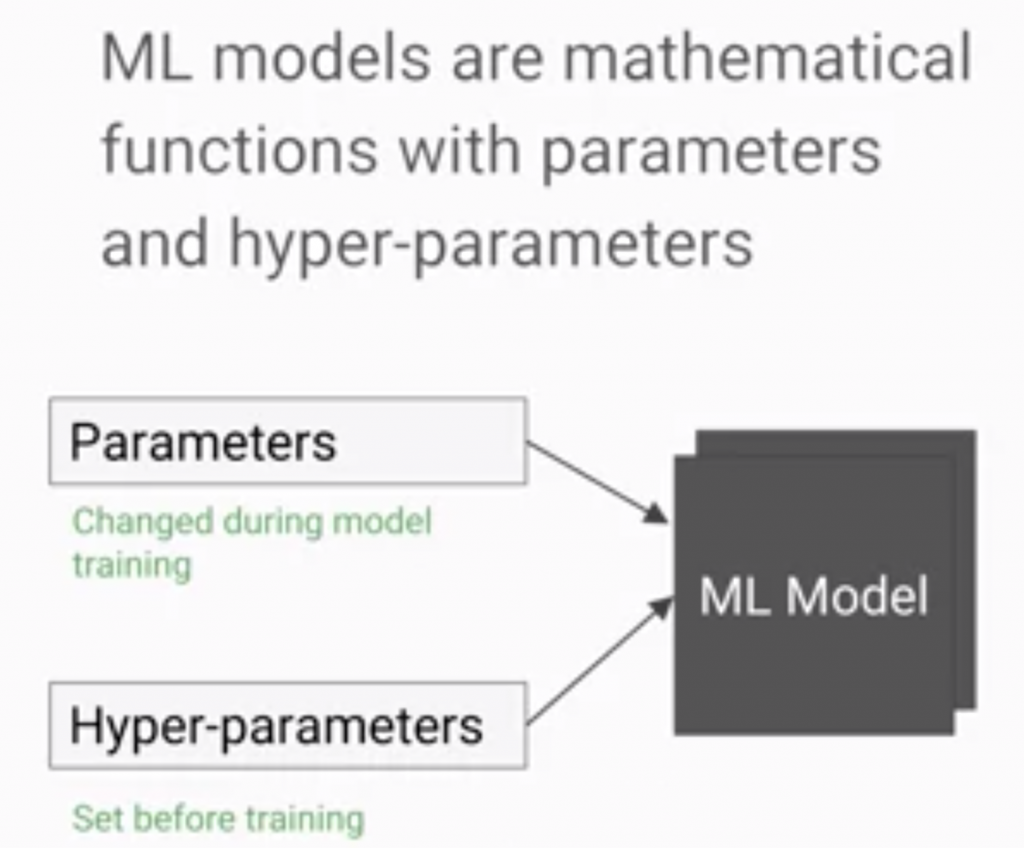
「超參數」需要通過多次實驗調整,來達到最適用的情況,
通常取決數據集和模型。
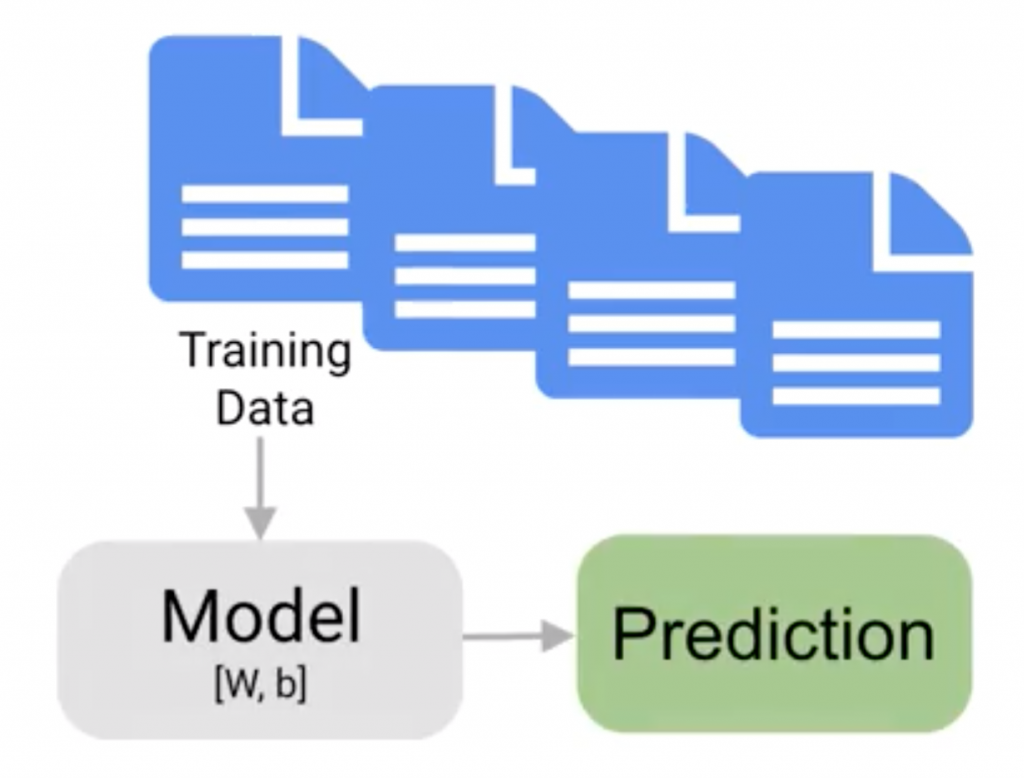
「超參數調整」不同於一般參數調整,
不管怎麼調整都不會影響「輸入」。
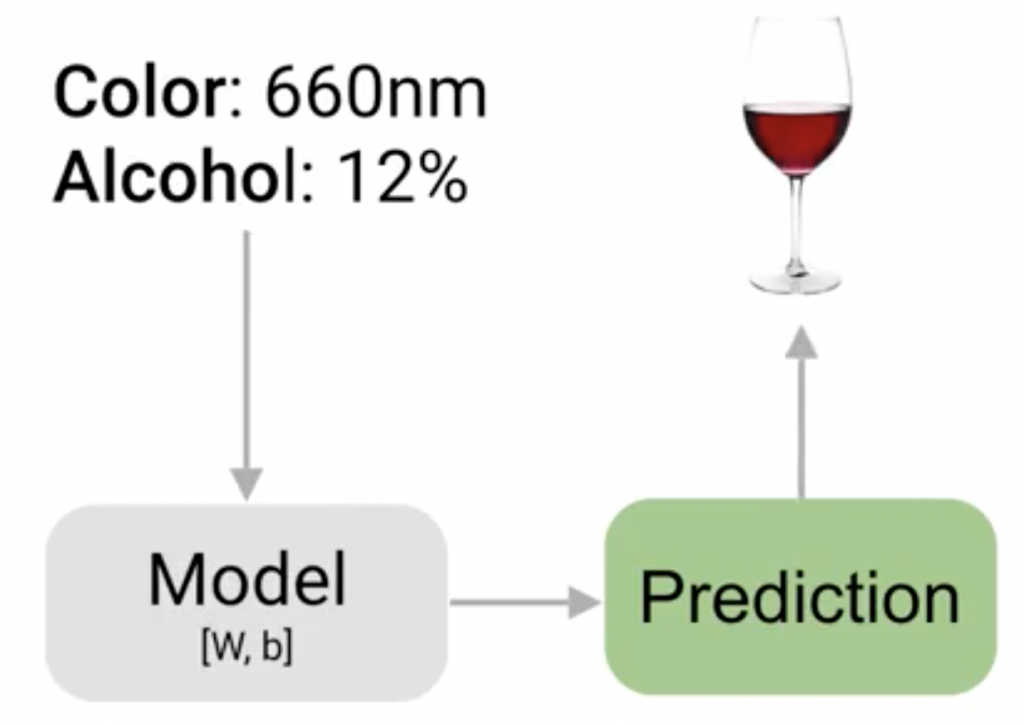
當你對你的模型感到滿意,就可以進行預測了,
透過輸入的參數,以模型計算後,預測出答案。
e.g. 例如輸入 顏色:660nm 和 酒精:12%,
我們就可以得到「葡萄酒」。
其實在進行機器學習七大步驟之前,
要先想清楚「今天我們要預測的問題」,
以及「我們能取得的資料及處理方式」。
讓電腦透過特徵值來預測結果,
而不是人工判斷和手冊規則,
相信未來可應用到更多領域上。
以上,打完收工。


 iThome鐵人賽
iThome鐵人賽