在用電腦程式實作機器學習之前,
還有哪些技術前要注意的?
就以「機器學習的七大步驟」出發討論吧!
為了要讓電腦讀懂資料,
所有資料都要結構化,
不管是字串、數字和時間...等。
根據機器是怎麼從資料中「學」到東西的呢提及,
常見EDA處理
特徵萃取 (Feature Extraction) 是從資料中挖出可以用的特徵。
經過特整萃取後,特徵選擇 (Feature Selection) 根據機器學習模型學習的結果,去看什麼樣的特稱是比較重要的。
若是要分析潛在客戶的話,那麼該客戶的消費頻率、歷年消費金額…等可能都是比較重要的特徵,而性別和年齡的影響可能便不會那麼顯著。
資料科學家會根據所要解決的問題、擁有的資料類型和過適化等情況進行衡量評估,選擇性能合適的機器學習模型。

由於機器學習模型的數量與方法非常多,包括了神經網路、隨機森林、SVM、決策樹、集群….。
常見的機器學習類別
為了避免overfit的問題,我們需要區分兩塊資料,分別為Train和Test,
而切法參考訓練-測試集切分概念
若只做一次切分,有些資料會沒有被拿來訓練過,因此就有了 cross-validation 的方法,可以讓結果更為穩定,其中 K 為 fold 數,即將資料切成 K 份,將每筆資料都當過一次驗證集,所得到的結果平均當作最終結果。
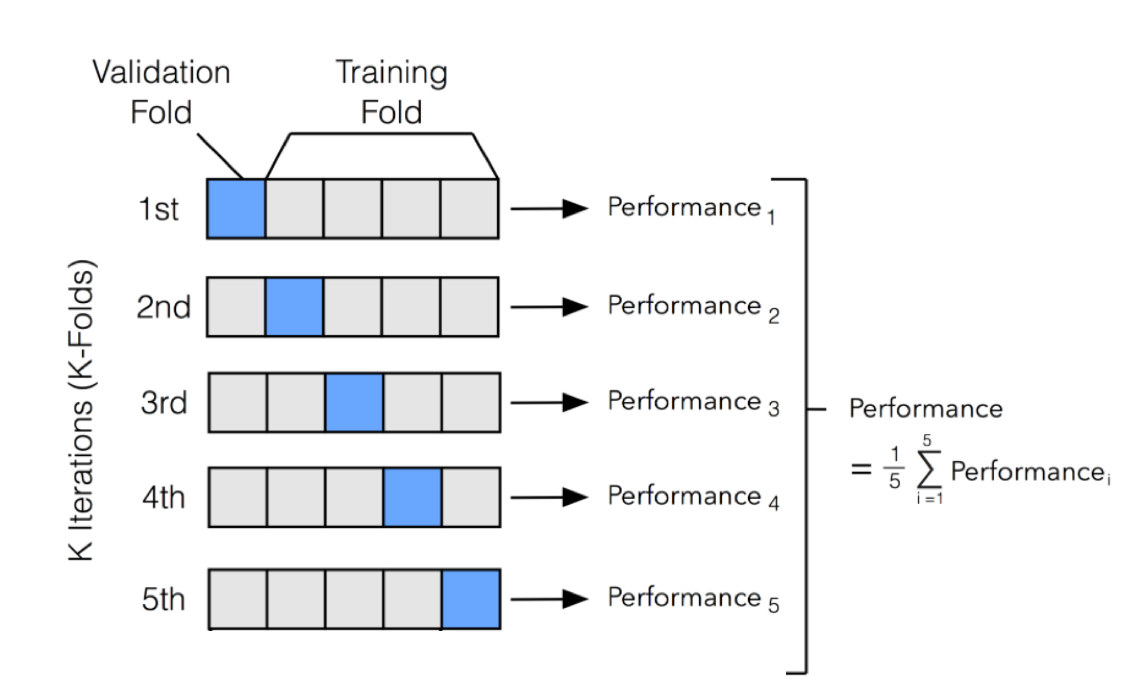
參考評估指標選定,
專案該如何選擇評估指標和常用指標,
最常見的為準確率 (Accuracy) = 正確分類樣本數 / 總樣本數,
而不同評估指標有不同的評估標準和面向,衡量的重點也不同。
觀察預測值 (Prediction) 和實際值 (Ground Truth) 的差距
觀察預測值 (Prediction) 和實際值 (Ground Truth) 的正確程度
迴歸問題可以透過 R-square 很快地了解預測的準確度。
分類問題若為二元分類 (Binary Classification),
通常使用 AUC 評估,
如特別希望哪一類別不要分錯,則可以使用 F1-Score,
觀察 Recall 值或是 Precision 值。
多分類問題可以使用 Top-k Accuracy,
k 代表模型預測前 k 個類別有包含正確類別即為正確
(ImageNet競賽通常都是比 Top-5 Accuracy)。
超參數是用來調整整個網路訓練過程的,
例如神經網路的隱藏層數量、核函數的大小和數量等。
參考超參數調整與優化,
之前所談論到的模型都有超參數需要設置
這些超參數都會影響模型的訓練結果,一般建議先使用預設值,再慢慢進行調整,
因為超參數雖然影響結果,但提升的效果有限,
資料清理和特徵工程才能最有效的提升準確率,
調整超參數只是一個加分的工具。
學習率:幫助確定梯度下降的幅度。
如果設置得太低,則梯度下降需要很長時間才能收斂。
如果設置得太高,梯度下降甚至可能會發散,並越來越增加損失。
預期可輸入多個input下,
產出一個output答案。
未來會使用Python程式語言來實作,
IDE為Jupyther Notebook,
並且import已存在的library來應用。
以上,打完收工。


 iThome鐵人賽
iThome鐵人賽