昨天有提到,Beautiful Soup 也可以用 lxml 來作為剖析器,但在某些特殊情況還是得回頭以 lxml 來使用 XPath 定位資料。
安裝 lxml 的方式可以參考昨天的文章,今天也沿用昨天的 HTML 原始內容。
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html>
"""
| 語法 | 說明 |
|---|---|
| node-name | 選擇名稱等於 node-name 的節點 |
| / | 選擇直屬於當前節點的所有節點(子節點) |
| // | 選擇當前節點下所有節點(子孫節點) |
| . | 選擇當前節點 |
| .. | 選擇上一層節點(父節點) |
| @ | 選擇屬性 |
以我們使用的 HTML 原始內容來說:
| 查詢路徑 | 結果 |
|---|---|
| /html | 取得 html 標籤(以 / 開頭代表從根節點開始找) |
| /html/body/a | 取得 body 下所有 a 標籤(無結果,因為 a 在 p 底下) |
| //a | 取得所有 a 標籤 |
| /html/body//a | 取得 body 下所有 a 標籤 |
| //a/@href | 取得所有 a 標籤的 href 屬性 |
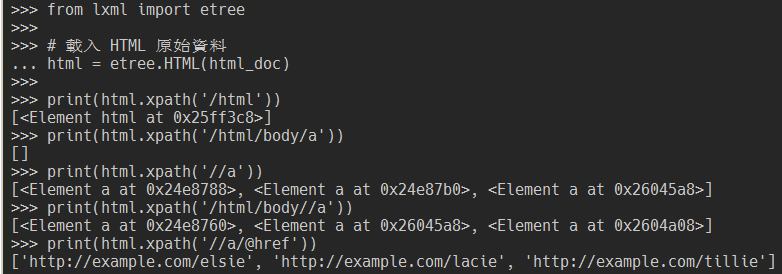
用 lxml 的 etree.HTML() 方法載入 HTML 原始資料後,可以用 .xpath() 方法來執行 XPath 查詢:
from lxml import etree
# 載入 HTML 原始資料
html = etree.HTML(html_doc)
print(html.xpath('/html'))
print(html.xpath('/html/body/a'))
print(html.xpath('//a'))
print(html.xpath('/html/body//a'))
print(html.xpath('//a/@href'))
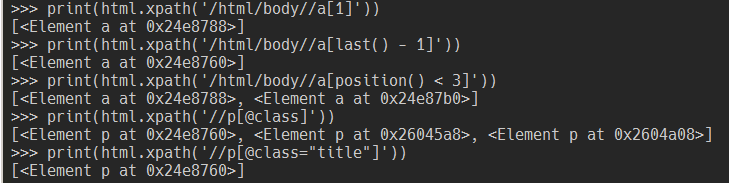
用 [ 和 ] 包起來,用來對查詢加上一些額外的限制
| 判斷式 | 結果 |
|---|---|
| /html/body//a[1] | 取得 body 下第一個 a 標籤 |
| /html/body//a[last() - 1] | 取得 body 下最後一個 a 標籤 |
| /html/body//a[position() < 3] | 取得 body 下前兩個 a 標籤 |
| //p[@class] | 取得有定義 class 屬性的 p 標籤 |
| //p[@class='title'] | 取得 class 屬性值為 title 的 p 標籤 |
print(html.xpath('/html/body//a[1]'))
print(html.xpath('/html/body//a[last() - 1]'))
print(html.xpath('/html/body//a[position() < 3]'))
print(html.xpath('//p[@class]'))
print(html.xpath('//p[@class="title"]'))
XPath 也支援萬用字元(wildcards)來選取任意節點
| 萬用字元 | 說明 |
|---|---|
| * | 任意標籤 |
| @* | 任意屬性 |
以我們使用的 HTML 原始內容來說:
| 查詢路徑 | 結果 |
|---|---|
| /html/body/* | 取得 body 標籤的全部子節點 |
| /html/body//* | 取得 body 下全部標籤 |
| //p[@*] | 取得至少有定義一個屬性的 p 標籤 |
print(html.xpath('/html/body/*'))
print(html.xpath('/html/body//*'))
print(html.xpath('//p[@*]'))

如果想要一次查詢多組路徑,可以用 | 來達成。
通常在所需資料分散多處,但不想查詢多次時會用到。(因為分次查詢會打亂資料順序)
| 查詢路徑 | 結果 |
|---|---|
| //p | //a | 一次取得全部 p 標籤和 a 標籤 |
print(html.xpath('//p | //a'))

用 Python 來剖析原始資料的方式就介紹到這邊!明天再了解怎麼在網路上取得原始資料後,後天就可以開始蒐集資料囉!


 iThome鐵人賽
iThome鐵人賽