開始蒐集資料前,需要拿到可以用來「剖析」的原始資料。但平常我們都是打開瀏覽器,輸入網址(甚至常常跳過這步)、可能會輸入一些關鍵字來搜尋、再點選幾個有興趣的連結。
那要怎麼用程式來做呢?首先要先了解瀏覽器是怎麼運作的。
實際上當我們在瀏覽器上輸入網址,或者點選某個連結時,瀏覽器會根據網址向對應的伺服器發送一個請求 / Request,伺服器收到請求後進行處理,產生對應的回應 / Response (通常是 HTML)後發送給瀏覽器,瀏覽器解析後才會變成我們看到的網頁內容,解析過程中可能會需要再發送額外的請求來載入其他資源(例如 CSS、JavaScript、圖片...)。整個流程簡單來說就像下圖:

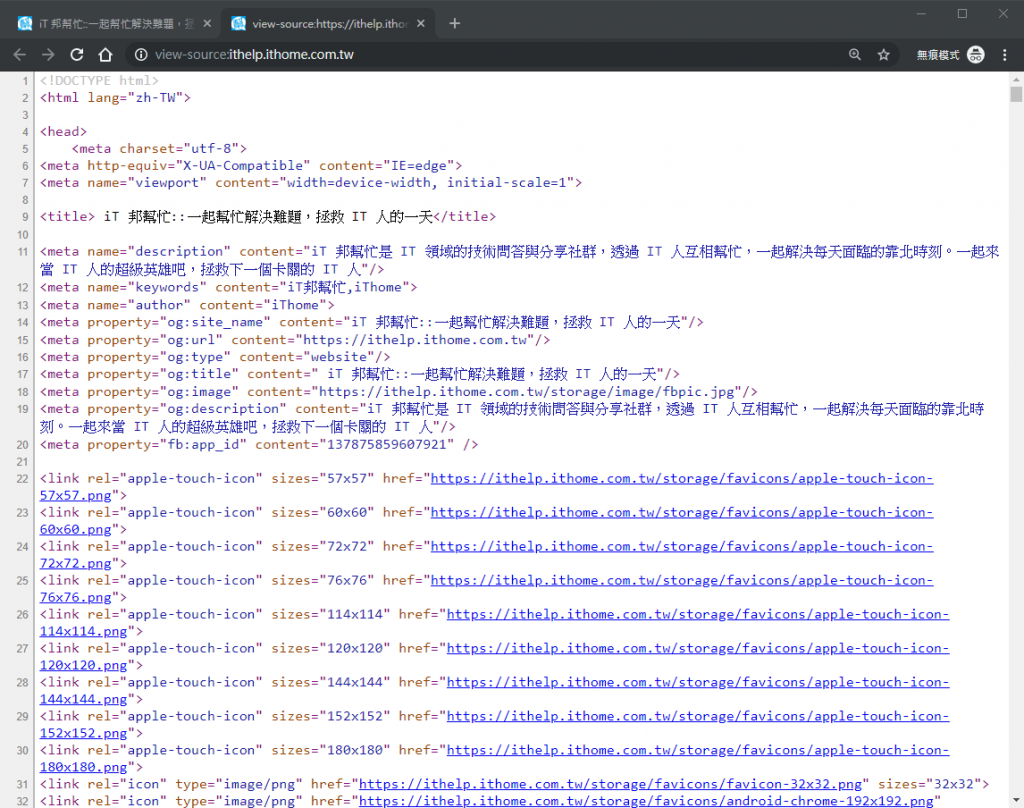
以 iT 邦幫忙的首頁來說,在網頁上按「右鍵 > 檢視原始碼」或者「Ctrl + U」,就可以看到發送請求後收到的回應了。可以看到回應是一堆 HTML 的語法,就是我們之後會拿來剖析的原始資料。
那就來寫程式吧!
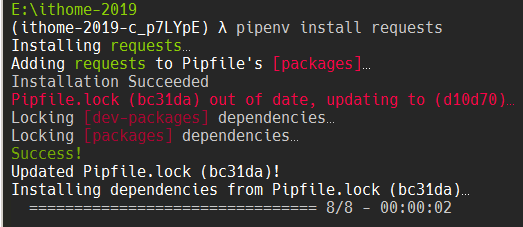
這邊我們使用 requests 這個套件來發送請求。其實後來也有找到其他好用的套件,日後如果有機會再來介紹。
pipenv --python 3.7
pipenv shell
pipenv install requests
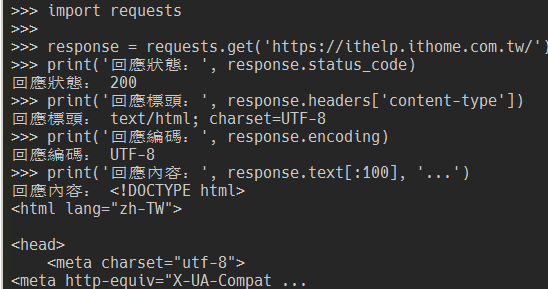
import requests
response = requests.get('https://ithelp.ithome.com.tw/')
requests.get 方法會用 HTTP 的 GET 方法來發送一個請求,並回傳一個 Response 物件。
print('回應狀態:', response.status_code)
print('回應標頭:', response.headers['content-type'])
print('回應編碼:', response.encoding)
print('回應內容:', response.text[:100], '...')
除了以不同的網址來向伺服器請求不同的回應外,也很常看到是用帶參數的方式向伺服器發送請求,雖然前面的網址相同,伺服器仍然會根據參數回傳不同的回應。
常看到的清單換頁、關鍵字查詢、送出表單內容,幾乎都是用這種方式來傳送。
而不同的請求方式,是透過不同的請求方法(HTTP request methods)來完成的,這邊介紹一下比較常用的 GET 和 POST 兩種方法,同時看一下怎麼用程式來完成。
前面看到的 requests.get('https://ithelp.ithome.com.tw/') 就是一種沒有帶參數的 GET 請求。
當我們想要在 iT 邦幫忙用關鍵字查詢相關文章的時候,就可以看到用 GET 請求帶參數的方式了。
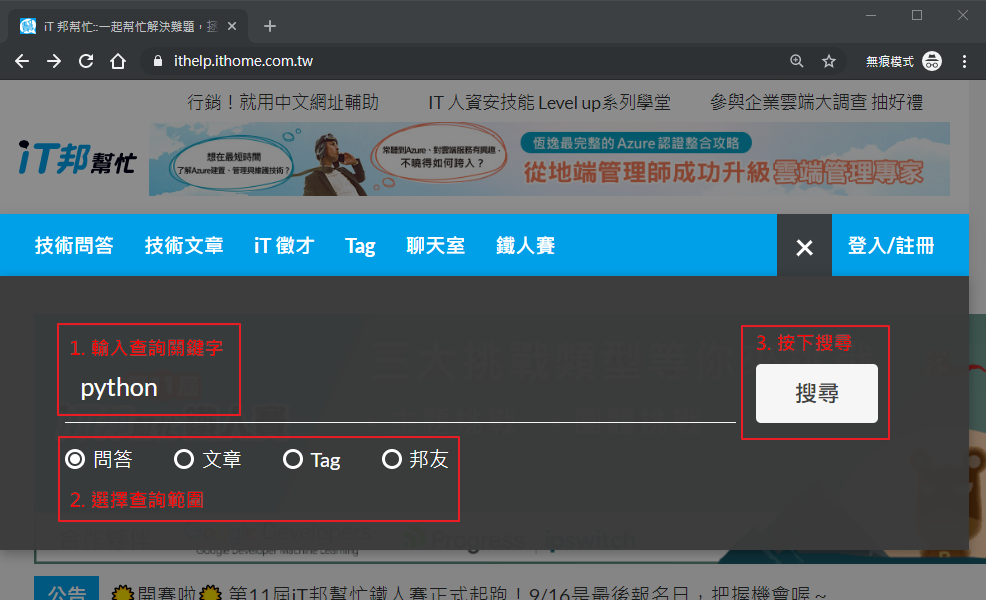
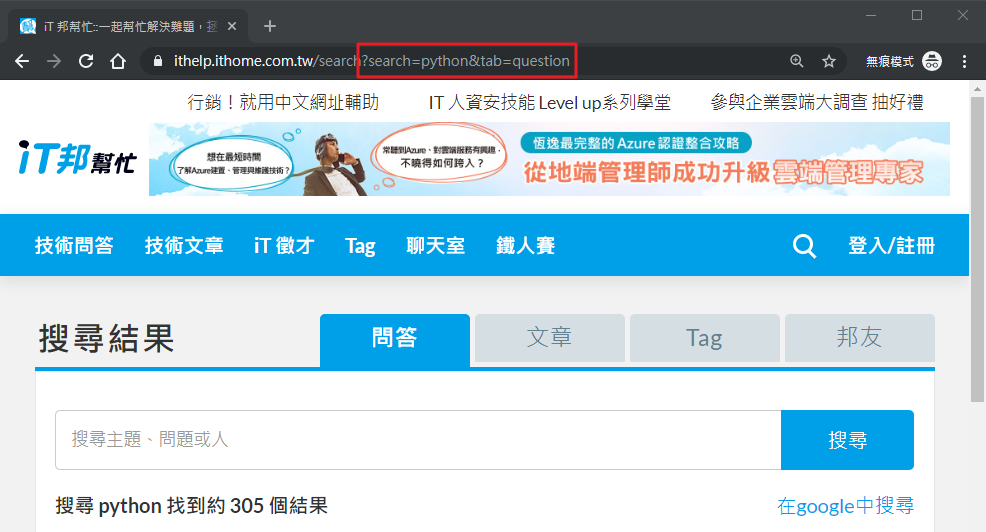
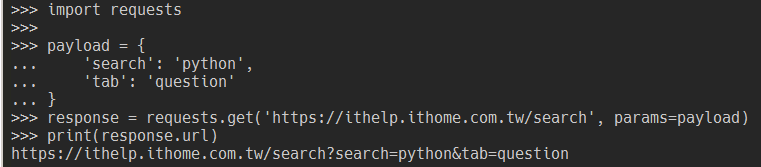
可以發現當我們依步驟做完後,網址變成「 https://ithelp.ithome.com.tw/search?search=python&tab=question 」,其中 ? 後的就是這次請求的參數(又稱查詢字串或 query string)。多組參數可以用 & 來組合;每組參數的 = 左邊是參數名稱,右邊是參數值。所以這個請求實際會帶兩個參數給伺服器:
| 參數名稱 | 值 |
|---|---|
| serach | python |
| tab | question |
用 requests 套件有兩種方式來發送 GET 請求:
import requests
response = requests.get('https://ithelp.ithome.com.tw/search?search=python&tab=question')
requests.get 方法額外的參數import requests
payload = {
'search': 'python',
'tab': 'question'
}
response = requests.get('https://ithelp.ithome.com.tw/search', params=payload)
print(response.url)
因為 GET 方法有一些限制:
所以在某些情況下會使用 POST 方法來發送請求(例如登入、上傳檔案):
為了方便說明用 requests 套件發送 POST 請求的方式,我們用 httpbin 這個網站來測試。
httpbin 會將收到的請求以特定的格式回應,可以驗證請求內容是否有符合預期
,可以找戰犯看到底是請求端還是伺服器端的問題,在需要發送外部請求但一直找不到問題時是個挺好用的工具。
requests 套件中的 requests.post 方法可以用來發送 POST 請求。
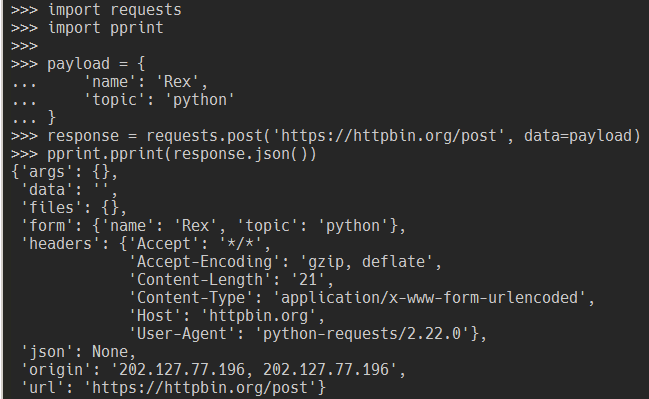
import requests
import pprint
payload = {
'name': 'Rex',
'topic': 'python'
}
response = requests.post('https://httpbin.org/post', data=payload)
pprint.pprint(response.json())
今天我們知道怎麼用 Python 來發請求了,明天就來試試怎麼爬取 iT 邦幫忙的文章吧!


 iThome鐵人賽
iThome鐵人賽