終於進入最令人期待的環節了!(有人期待嗎QQ)接著四天會試著蒐集 iT 邦幫忙的技術文章,從列表頁開始,把每篇文章的標題、內文、回應和留言都蒐集起來。
接下來的實作都建議大家使用虛擬環境了喔!記得先執行
pipenv shell
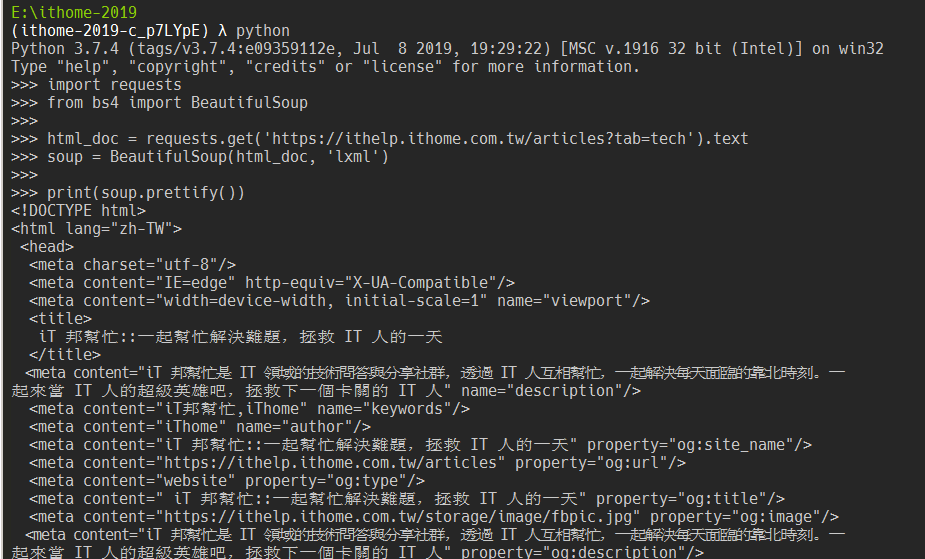
在 Day 7 中,我們有學到怎麼拿到網頁原始碼,這邊用簡單的 GET 請求即可,同時利用 Day 5 學到的 BeautifulSoup 來載入網頁原始碼。
import requests
from bs4 import BeautifulSoup
html_doc = requests.get('https://ithelp.ithome.com.tw/articles?tab=tech').text
soup = BeautifulSoup(html_doc, 'lxml')
print(soup.prettify())
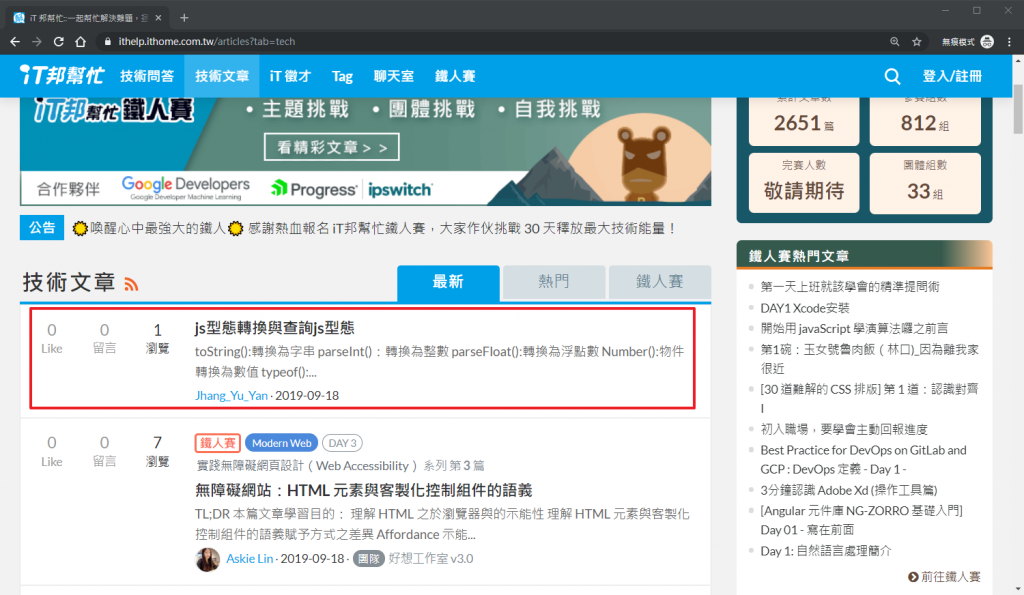
先在畫面上確認我們要蒐集的資料範圍。例如我們要抓到畫面上第一篇文章「js型態轉換與查詢js型態」:(後面截圖或執行的時候第一篇文章會一直變.....畢竟鐵人賽期間更新很快)
這時候可以用 Chrome 的開發人員工具來定位資料在原始碼中的位置,開啟開發人員工具的方式有幾種:
F12
Ctrl + Shift + I
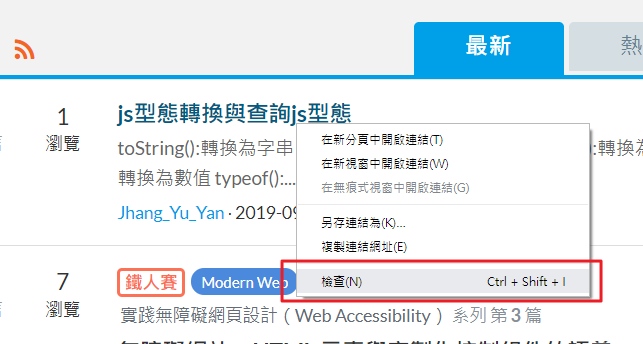
打開後就可以看到下方多出一個區塊,紅框內是目前畫面上的 HTML 原始碼,這就是爬蟲很重要的工具之一啦!
如果開發人員工具不在下方,或者想要顯示在其他位置的話,可以點選右上方三個點的圖標,在「Dock side」中選擇要顯示的位置,左到右分別為:另開視窗、靠左,置底,靠右。
這時候有兩種方式可以快速定位我們想要的資料:

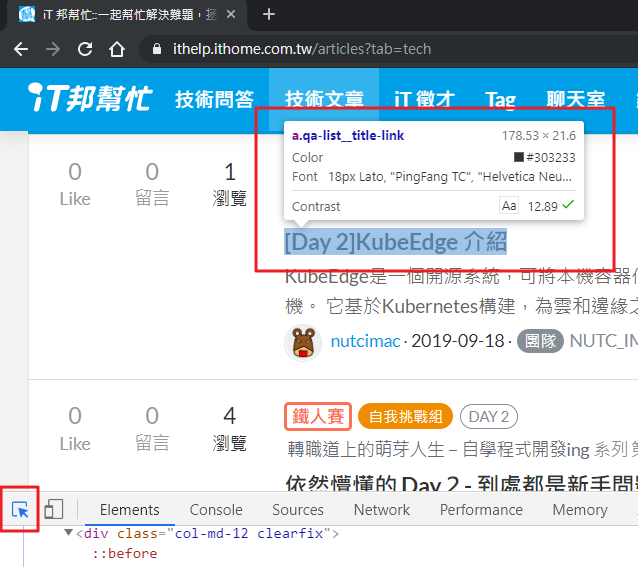
這時候就可以看到下方的原始碼中,反白灰色區塊會跳到我們定位的文章標題了。
在 Day 6 我們有學到怎麼在程式中找到目標資料,但是...現實中的 HTML 結構這麼複雜,要怎麼快速在 HTML 結構中找出文章標題呢?這時候有個偷懶的方式,就是在原始碼中文章標題的標籤上按「右鍵 > Copy > Copy selector」。
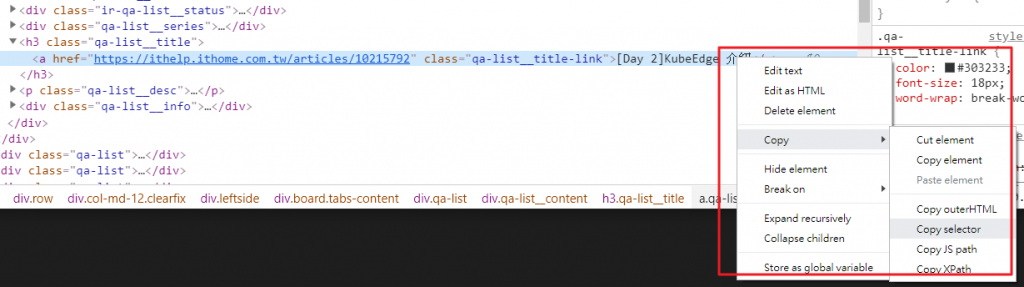
找個地方貼上,就會得到一串密密麻麻的東西:body > div.container.index-top > div > div > div.leftside > div.board.tabs-content > div:nth-child(1) > div.qa-list__content > h3 > a,這串就是第一篇文章標題的 CSS 選擇器,我們就可以拿來在程式中找到文章標題了。
title = soup.select_one('body > div.container.index-top > div > div > div.leftside > div.board.tabs-content > div:nth-child(1) > div.qa-list__content > h3 > a')
print(title.text)

再次說明,這段時間一直有新文章出來,所以每個截圖、每次執行程式的結果都不一樣是很正常的
今天的任務是要找出列表頁中所有文章標題,我們可以用剛剛的方式來取得每篇文章標題的 CSS 選擇器。
title1 = soup.select_one('body > div.container.index-top > div > div > div.leftside > div.board.tabs-content > div:nth-child(1) > div.qa-list__content > h3 > a')
title2 = soup.select_one('body > div.container.index-top > div > div > div.leftside > div.board.tabs-content > div:nth-child(2) > div.qa-list__content > h3 > a')
title3 = soup.select_one('body > div.container.index-top > div > div > div.leftside > div.board.tabs-content > div:nth-child(3) > div.qa-list__content > h3 > a')
# ...依此類推
除非是用程式行數算薪水再這樣幹
萬一網站改版了(真的常常發生!),會需要修改一大堆地方,非常不方便而且很容易漏改。人生苦短,我們可以用更有效率的方式來寫程式,把多出來的時間拿去看其他鐵人大大的文章。
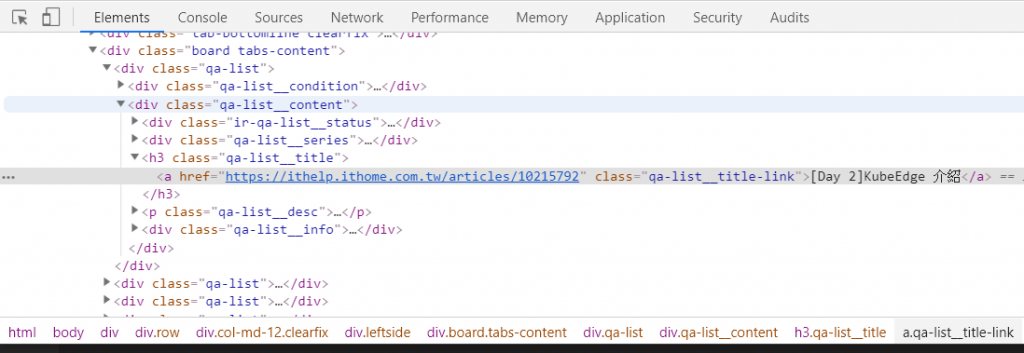
要怎麼找到適用於所有文章標題的選擇器呢?可以先參考開發人員工具下方這排,雖然很冗長但很有參考價值,就先拿來試試看吧。
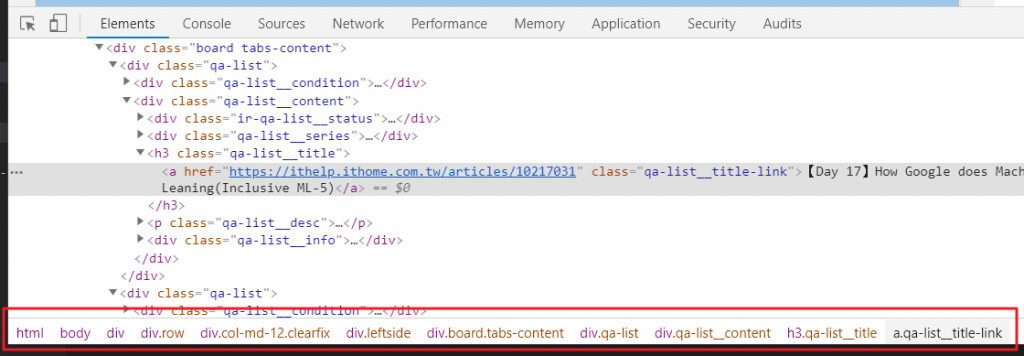
title_tags = soup.select('html > body > div > div.row > div.col-md-12.clearfix > div.leftside > div.board.tabs-content > div.qa-list > div.qa-list__content > h3.qa-list__title > a.qa-list__title-link')
for title_tag in title_tags:
print(title_tag.text)
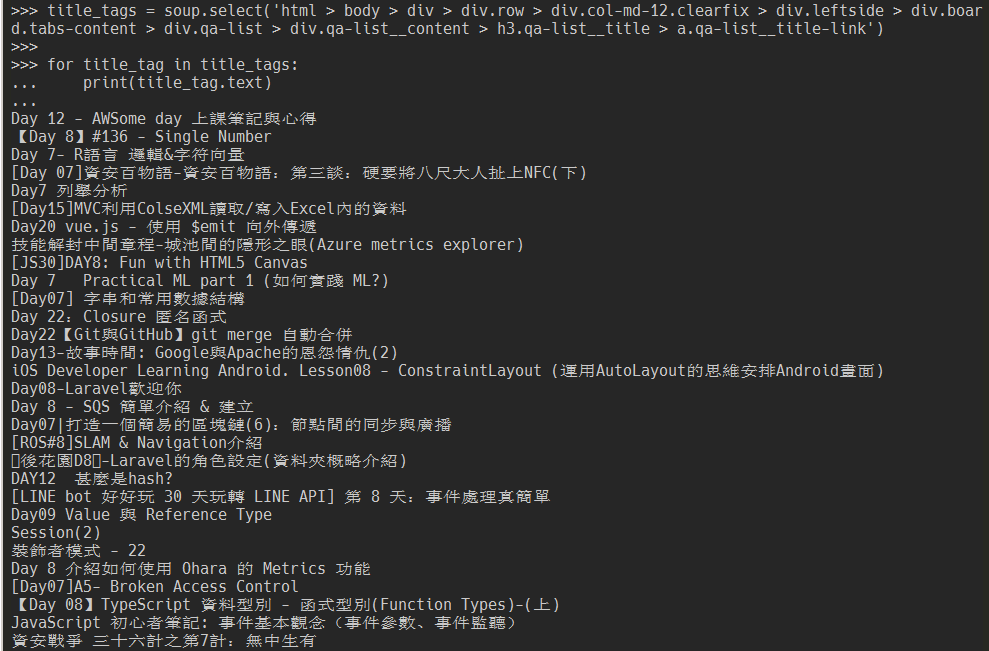
看來有成功抓到網頁上所有文章標題了,但有覺得這一長串選擇器看起來很難過嗎?其實要定位文章標題不需要這麼複雜的選擇器,詳情請待下回分解~