大家好,我是長風青雲。今天是第二十六天,昨天表現完敬意後,我們就要開始動手了。
現在我們面對的問題是──如何動手?
難不成我們要一個一個把影片下載下來,再將他放在static裡面嗎?
難道我們要一個一個把文案複製下來,再將他print在我們的頁面上嗎?
如果遇到不會的單字,難道我們要打開另外一個網頁查嗎?
一句話 ── 「想太多!」
我們現在可是使用python,python除了AI外最常見的用法是什麼?
Crawler!
爬蟲爬蟲大家最常講的,難道忘記了嗎?
所以這一個實例,主要做的就是爬蟲,爬完後將資料成現在頁面上。
當然如果想要有下載,像我不是說希望能列印收藏嗎?也是可以,上一個實例在最後也有說過如何寫下載的部分。
那還在等什麼~我們出發~
首先我們先來到101 Video的網址(https://video.nationalgeographic.com/video/101-videos)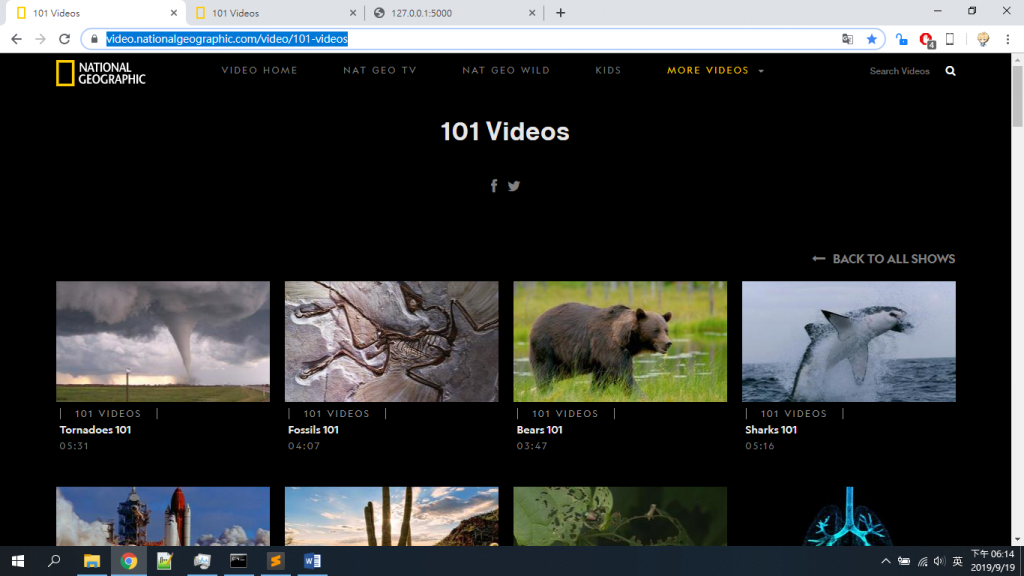
我們需要他每一個圖片連結去網站。
接下來讓我們來觀賞一下影片,使用F12大法!

看完影片我們知道我們要跑的網址有
for i in range(0,7):
url="https://video.nationalgeographic.com/video/101-videos?gs=&gp="+str(i)
懶得一個一個打XD這樣展示應該大家都看的懂
確認好所需網址後,接著讓我們開始爬吧!
知道爬蟲的人,應該都使用過這個Module。
不知道的人,去cmd打pip install beautifulsoup4
他可以讓你輕易的爬下來還幫你排版,讓你在看程式碼的時候不會眼花撩亂。
那就先讓我們嘗試把影片網址爬出來吧!
dic={}
for i in range(0,7):
url='https://video.nationalgeographic.com/video/101-videos?gs=&gp='+str(i)
page=urllib.request.urlopen(url)
soup = BeautifulSoup(page, 'html.parser')
all=soup.find_all('a', class_="load-inline")
for tag in all:
dic[tag.text.strip('\n')]='https://video.nationalgeographic.com'+tag.get('href')
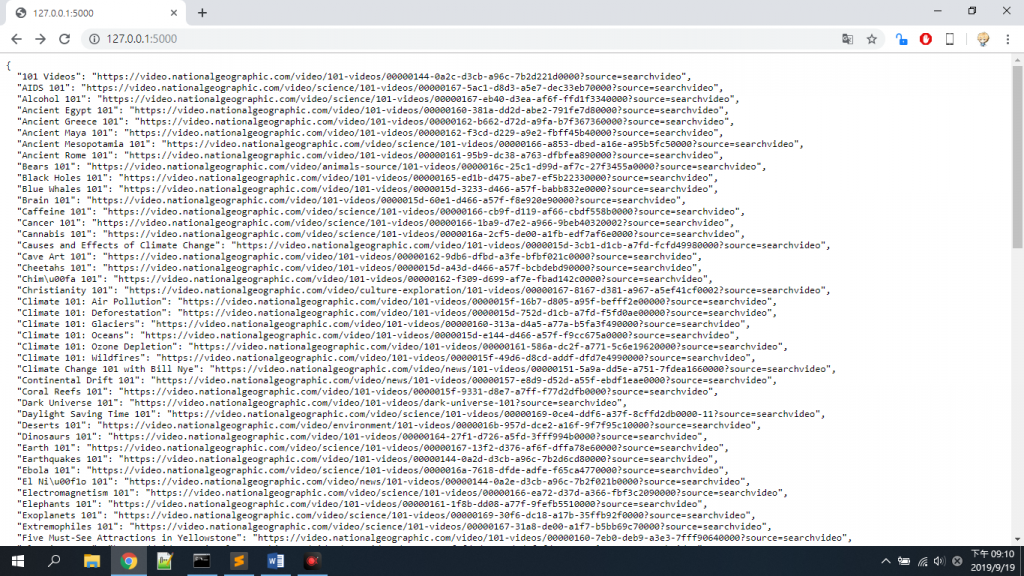
看樣子我們已經成功爬出所有的影片網址啦~
其實在101Video中他是具有分類的。
有的講環境,有的講氣候,有的講歷史……
我原先很開心的發現他的網址有標註他是屬於哪個分類……
結果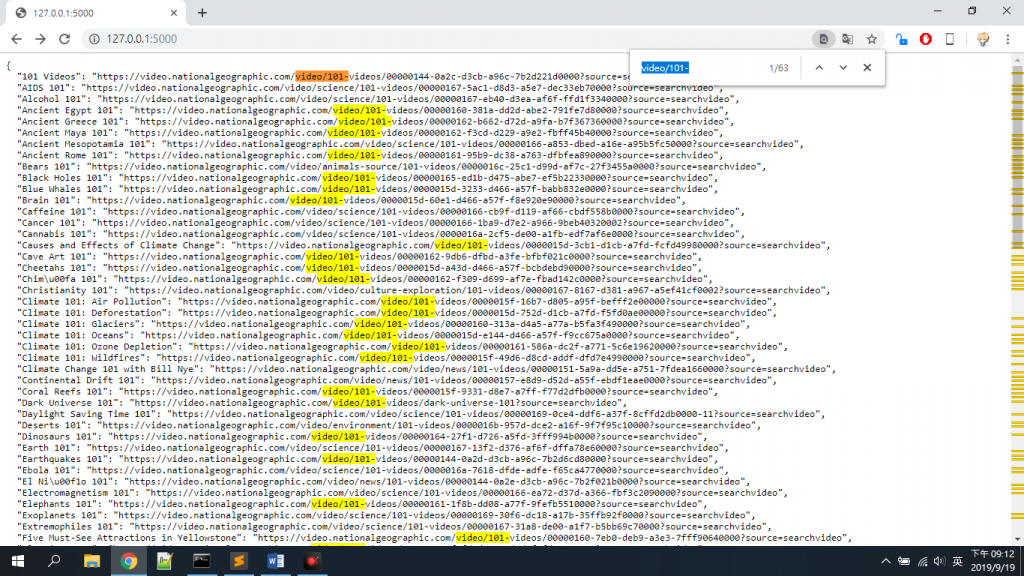
居然有63個沒分類!!!
這誰做的網站,做事做一半,拖出去打屁股!
也因為這件事……我去手動分類的大家明天見QAQ


 iThome鐵人賽
iThome鐵人賽