「怎麼回事?你要什麼?」我問。天啊,我的聲音顫抖地跟什麼一樣。
「沒要什麼,」茉莉絲大姊說,「只要再幫我記 5 筆資料」。她們兩個人一起來,但都是茉莉絲在說話。珊妮只是站在那裏,張著嘴巴什麼的。~節錄自《賴田捕手》第十四章
這幾天我們從無到有,架設了一隻 LINE 聊天機器人,機器人不但會學我們說話、唱歌、幫我們抓圖片,甚至還會在早上的時候叫我起床、跟我問好。這麼風趣又貼心,害我每天都跟他玩到好晚,什麼煩惱都拋到九霄雲外了。其實 LINE 聊天機器人不僅會討人歡心,還可以變得更貼心,幫你整理你平時不想閱讀的資料、不想整理的表格,不想準備的報告,總之,連你工作上碰到的麻煩事,LINE 聊天機器人都願意有條不紊的幫你處理好。你不相信?
眾所周知,草泥馬是一種食量極為驚人的生物。無辜的眼睛、堅硬的牙齒、強壯的下顎、靈活的胃袋、有力的腸道系統,這些許許多多演化而來的特徵,使得這種進食機器有能力在短時間之內吃下大於本身體積的食物。與牠們體型相似的綿羊來比較,成年草泥馬的平均食量來到了綿羊的 180 倍。因此有些學者推斷,戈壁沙漠的形成原因,或許與生活在那裡的草泥馬脫不了關係。這還只是生活在自然環境下的草泥馬。在 1980 年代,科學家們發現草泥馬那原本就不可理喻的食量,居然還可以因為人為訓練而更加增長。近年來蓬勃發展的草泥馬進食擂台,則是大公司看準了這一商機:人們熱衷於觀賞草泥馬慢條斯理卻極具效率的進食方式,急切的想知道大自然所創造出來的進食機器究竟極限在哪?
這些訊息與我何干呢?有的,不瞞您說,我的工作正是草泥馬進食訓練師。我每天要督促草泥馬們進行不同類型的進食訓練,從肌力訓練、咬合訓練、腸道蠕動訓練,到模擬比賽、真槍實彈的牧草進食、蛋糕進食、漢堡進食等等。這可不是看牠們吃就了事。由於不同的訓練會對草泥馬帶來不同程度的負荷,根據本身的身體狀況、進食表現、與接受過的訓練內容,為草泥馬們規劃接下來的訓練菜單。總而言之,必須在照顧好草泥馬的健康狀況下,讓牠們的食量穩定且有效率的成長。
說了那麼多跟大家無關的廢話,究竟今天我們又希望 LINE 機器人能學些什麼,幫我分憂解勞呢?
我希望 LINE 機器人能夠幫我記錄下每一筆草泥馬的訓練資料,包括訓練內容、訓練長度、日期等等,提供往後做成表格或畫成圖表,讓我可以更有效率的替每一隻草泥馬規劃未來的訓練方式。
既然需要紀錄資料,我們就需要有一個可以跟 LINE 聊天機器人互動的資料庫(database)。既然 Heroku 有提供,那我們就試著來用一用。
Heroku 所提供的資料庫叫做 Heroku Postgres,屬於 PostgreSQL➀,是關聯性資料庫(relational database)的其中一種。若大家將來要開始處理電腦資料,或早或晚都會碰到這種資料庫。所謂的 SQL,指的是結構化查詢語言(structured query language) ➁,可以用來定義數據以及整理數據。所以說,為了能夠順利地使用 Heroku 的資料庫,我們又要多學一種語言了?這邊我可以說是,也可以說不是。因為 SQL 的世界也是博大精深,我們只是稍微背幾個關鍵字,學幾樣操作而已,難不倒各位的。那麼就先從向 Heroku 要一個資料庫開始囉!
Heroku Postgres 是掛載在 dyno 下的擴充元件(add-ons)。一個 dyno 可以掛載多個資料庫,而資料庫也可以連接到多個 dyno。不過這邊我們不討論這麼多。首先從命令提示字元登入 Heroku,然後輸入指令:
D:\alpaca_fighting>heroku addons -a 你-APP-的名字
No add-ons for app 你-APP-的名字.
利用heroku addons來查詢我們有那些掛載的擴充元件,後面的-a 你-APP-的名字是用來指定要查詢的 dyno。如果你還沒掛載任何擴充元件,那應該會看到像我一樣的畫面。
相同的,Heroku Postgres 也有按照資費提供不同的規格,如圖一➂。
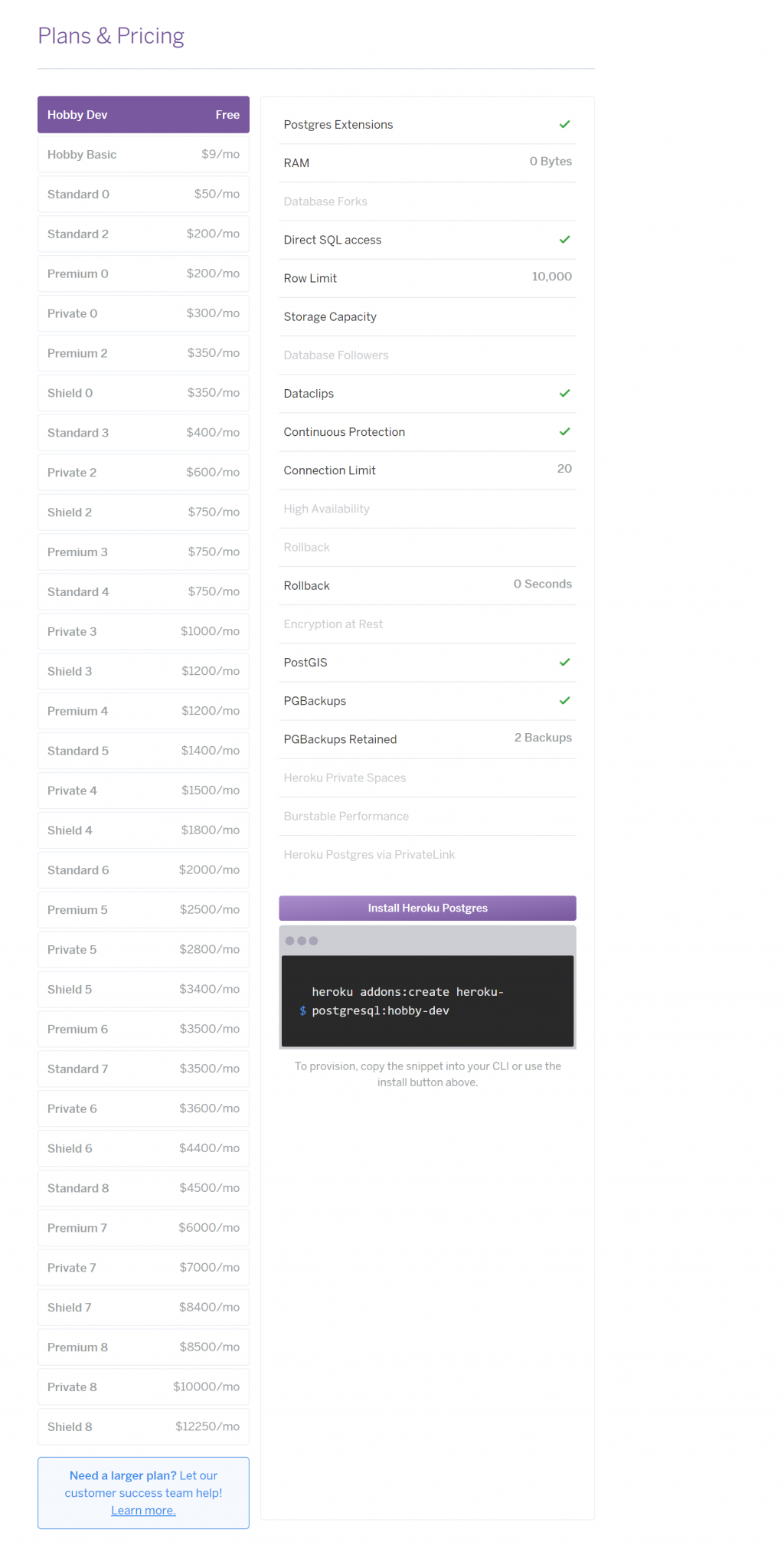
圖一、Heroku Postgres 資費方案參考
而我們要選擇的方案是hobby-dev,這是免費的方案,提供 10000 則資料的容量以及最多 20 個使用者同時連線操作。恩,目前對我來說還夠用。決定好方案之後,就可以輸入指令啦:
D:\alpaca_fighting>heroku addons:create heroku-postgresql:hobby-dev
Creating heroku-postgresql:hobby-dev on ⬢ 你-APP-的名字... free
Database has been created and is available
! This database is empty. If upgrading, you can transfer
! data from another database with pg:copy
Created postgresql-amorphous-85828 as DATABASE_URL
Use heroku addons:docs heroku-postgresql to view documentation
輸入heroku addons:create heroku-postgresql:我們選擇的方案名稱,這邊因為我只想用免費的,所以是hobby-dev。等 Heroku 幫我們創造好一個資料庫之後,我們再試著回頭查詢addons:
D:\alpaca_fighting>heroku addons -a 你-APP-的名字
Add-on Plan Price State
────────────────────────────────────────────── ───────── ───── ───────
heroku-postgresql (postgresql-amorphous-85828) hobby-dev free created
└─ as DATABASE
The table above shows add-ons and the attachments to the current app (你-APP-的名字) or other apps.
出現了,我們的第一個擴充元件!
有了可以儲存資料的資料庫,接下來就是在裡面創造一些表格,把我們希望保留的資料一筆一筆的記下來。要跟資料庫溝通,讓資料庫按照我們的指示運行,需要用到 SQL 的語法,而讓 Python 連接上指定的資料庫並執行透過 SQL 語法寫下來的指令,則需要一座橋梁,這座橋梁是 psycopg2。
這樣講可能很抽象,我直接把一段在資料庫中利用 SQL 指令創建表格的程式碼放上來,我們邊講邊理解。
不過首先,我們要在自己的環境裡安裝 psycopg2 這個套件。不安裝當然也可以,因為真正需要安裝、真正在執行程式碼的是 Heroku 那邊的伺服器。我安裝的理由是,讓我們在自己的環境先熟悉熟悉 psycopg2 吧!
打開 Anaconda Prompt,輸入conda activate 我的環境進到我們用來搭建 LINE 聊天機器人的環境裡。接著輸入 conda install -c anaconda psycopg2來安裝 psycopg2➃。有了 psycopg2,我們就可以開啟 Jupyter Notebook 來練習囉:
In [1]: import os
import psycopg2
DATABASE_URL = os.popen('heroku config:get DATABASE_URL -a 你-APP-的名字').read()[:-1]
conn = psycopg2.connect(DATABASE_URL, sslmode='require')
cursor = conn.cursor()
SQL_order = '''我們輸入 SQL 指令的位置'''
cursor.execute(SQL_order)
conn.commit()
cursor.close()
conn.close()
上面是一個常用的 psycopg2 連接資料庫並執行 SQL 指令的流程➄。前面兩行程式碼應該不困難,先引入等等需要的模組。我就從第三行開始:
DATABASE_URL = os.popen('heroku config:get DATABASE_URL -a 你-APP-的名字').read()[:-1]os.popen()是什麼意思呢?這是要 Jupyter Notebook 模仿命令提示字元去執行指令。'heroku config:get DATABASE_URL -a 你-APP-的名字'這行文字是不是讓你覺得有些懷念的味道呢?沒錯,就像我們常常在命令提示字元裡輸入的 Heroku 指令,你也可以將這行指令打在命令提示字元看看:C:\Users\MyName>heroku config:get DATABASE_URL -a 你-APP-的名字
postgres://一長串字元以下略
看到了嗎,postgres://一長串字元以下略這長長的一串就是我們要的DATABASE_URL。為什麼read()之後不是將字元數到最後,而是扣了一個-1呢?數到最後會得到postgres://一長串字元以下略\n原來是多了一個換行符號啊。
第四行:conn = psycopg2.connect(DATABASE_URL, sslmode='require')
利用前面得到的DATABASE_URL連接上 Heroku 給我們的資料庫。
第五行:cursor = conn.cursor()
初始化一個可以執行指令的cursor()。
第六行: SQL_order = '''我們輸入 SQL 指令的位置'''
先製造一個字串物件,其內容是由 SQL 語法所寫出來的指令。
第七行:cursor.execute(SQL_order)
執行 SQL 指令。
第八行:conn.commit()
SQL 的指令可分成四大類:新增(CREATE)、讀取(SELECT)、更新(UPDATE)、刪除(DELETE)。除了讀取資料之外,其他三種指令利用cursor.execute()下達之後,都需要再用conn.commit()做確認,指令才會真正被執行。執行了指令,就可以利用最後兩行程式碼來關閉cursor以及中斷連線了。
有點概念了嗎?再來一次:
In [2]: import os
import psycopg2
DATABASE_URL = os.popen('heroku config:get DATABASE_URL -a 你-APP-的名字').read()[:-1]
conn = psycopg2.connect(DATABASE_URL, sslmode='require')
cursor = conn.cursor()
創造表格的SQL指令 = '''CREATE TABLE account(
user_id serial PRIMARY KEY,
username VARCHAR (50) UNIQUE NOT NULL,
password VARCHAR (50) NOT NULL,
email VARCHAR (355) UNIQUE NOT NULL,
created_on TIMESTAMP NOT NULL,
last_login TIMESTAMP
);'''
cursor.execute(創造表格的SQL指令)
conn.commit()
cursor.close()
conn.close()
按照順序來,先用psycopg2.connect()連接到資料庫,用cursor()初始化執行指令的工具,將 SQL 指令做成字串物件,用execute()來下達指令,最後用commit()來確認執行指令,這樣就跑完一個流程了。上面的程式碼當中,我們真正的輸入了一段可以用來創造表格(table)的 SQL 指令,拿出來檢視檢視吧:
CREATE TABLE account(
user_id serial PRIMARY KEY,
username VARCHAR (50) UNIQUE NOT NULL,
password VARCHAR (50) NOT NULL,
email VARCHAR (355) UNIQUE NOT NULL,
created_on TIMESTAMP NOT NULL,
last_login TIMESTAMP
);
第一行: CREATE TABLE account(
利用CREATE跟TABLE這兩個關鍵字,說明我們要在資料庫中創造表單,而表單的名字叫account。利用一個(承上啟下,一個一個列出表單中每一個欄位(column)的格式。
第二行:user_id serial PRIMARY KEY,
user_id是第一個欄位的名稱,serial及PRIMARY KEY則是 SQL 的關鍵字,用來解釋該欄位資料的特徵跟限制。serial意指這個欄位的值會自動產生,從 1 開始一直數下去,就像編號一樣。PRIMARY KEY則給予這個欄位不能是空值(NOT NULL)以及每筆資料必須獨一無二(UNIQUE)的限制。
第三行:username VARCHAR (50) UNIQUE NOT NULL,
username是第二個欄位的名稱。VARCHAR (50)則說明這一欄資料須為字串(character)資料,且最多為 50 個字元。UNIQUE跟NOT NULL限制了這個欄位的資料必須是獨一無二以及非空值。既然這樣,為什麼不再用一次PRIMARY KEY就好了呢?因為一個表單最多只能有一個PRIMARY KEY,而我們把它給了user_id。
第四行:password VARCHAR (50) NOT NULL,
password為第三個欄位的名稱。VARCHAR (50)則以下略。相信聰明的大家應該開始對 SQL 指令有一些感覺了吧?剩下的就先不多做解釋囉。
不知道大家有沒有發現,要開始使用 SQL 語言其實不是那麼困難,雖說要用得好也沒那麼容易。不過對目前我們的需求來說,只要先熟悉幾個關鍵字,就能夠很快實作出堪用的線上表單了!我在表一列出了幾樣常用的欄位資料型態,而 SQL 還有提供更多,有興趣的可以到這裡➅或那裡➆找找。
表一、常用的欄位資料型態
| 語法 | 說明 |
|---|---|
| Boolean | 布林 |
| CHAR, VARCHAR, and TEXT | 字串 |
| NUMERIC | 數值 |
| Integer | 整數 |
| SERIAL | 序列 |
| DATE | 日期 |
| TIMESTAMP | 時間戳 |
| Interval | 間隔 |
| TIME | 時間 |
剛才忘記提到的一件事,SQL 語法並不重視大小寫,所以serial跟SERIAL對 SQL 指令來說代表相同意思。習慣上,會將 SQL 的關鍵字用大寫,而我們自己的變數用小寫,就像是CREATE TABLE account這樣。不過這也只是約定成俗的作法,並沒有強制。
另一件事,SQL 也不在意換行符號跟空白鍵的多寡,關鍵字只要按照順序擺對位置就行。所以像我剛才舉的例子:
CREATE TABLE account(
user_id serial PRIMARY KEY,
username VARCHAR (50) UNIQUE NOT NULL,
以下略
你要橫著寫:
CREATE TABLE account( user_id serial PRIMARY KEY, username VARCHAR (50) UNIQUE NOT NULL, 以下略
SQL 也都看得懂。
說了那麼多,那我們今天為了要好好照顧草泥馬而做的表格呢?
In [3]: import os
import psycopg2
DATABASE_URL = os.popen('heroku config:get DATABASE_URL -a 你-APP-的名字').read()[:-1]
conn = psycopg2.connect(DATABASE_URL, sslmode='require')
cursor = conn.cursor()
create_table_query = '''CREATE TABLE alpaca_training(
record_no serial PRIMARY KEY,
alpaca_name VARCHAR (50) NOT NULL,
training VARCHAR (50) NOT NULL,
duration INTERVAL NOT NULL,
date DATE NOT NULL
);'''
cursor.execute(create_table_query)
conn.commit()
cursor.close()
conn.close()
好了,執行完了,但是什麼事都沒有發生啊?我們的表格在哪裡?
In [4]: import os
import psycopg2
DATABASE_URL = os.popen('heroku config:get DATABASE_URL -a 你-APP-的名字').read()[:-1]
conn = psycopg2.connect(DATABASE_URL, sslmode='require')
cursor = conn.cursor()
cursor.execute("SELECT column_name, data_type FROM information_schema.columns WHERE table_name = 'alpaca_training'")
這時候就要用到 SQL 的第二種指令:讀取(SELECT)。直接來看最後一行程式碼,先別管information_schema.columns的話,其他部分大家是不是也一看就懂呢?白話翻譯一下,這段指令應該是要:「讀取欄位名稱、資料型態,從information_schema.columns,當表格的名稱是'alpaca_training'」,好像有點拗口,再一次:「請從information_schema.columns讀取表格名稱為'alpaca_training'的欄位名稱跟資料型態」。喔喔,原來如此。那讀取了以後要怎麼做呢?
In [5]: data = []
while True:
temp = cursor.fetchone()
if temp:
data.append(temp)
else:
break
print(data)
Out[5]: [('record_no', 'integer'), ('alpaca_name', 'character varying'), ('training', 'character varying'), ('duration', 'interval'), ('date', 'date')]
看到第三行程式碼,這邊利用fetchone()來將讀取到的資料一筆一筆拿出來。這種操作有點像是 Python 裡面的 generator,但什麼是 generator 啊?抱歉我前面提都沒提過,那換個方式來打比方:這種操作有點像是字串物件的pop()方法。pop()方法將字串中的字元一個一個拿出來給你看,最後原本的字串物件就會變成一個空的字串。而fetchone()也是這樣,將原本存在cursor中的資料一筆一筆拿出來給你看,所有資料都拿出來以後,我們還是可以繼續執行fetchone(),不過就什麼東西都傳不回來了。因此我上面那段程式碼的邏輯是,利用fetchone()拿出一筆資料,並丟給temp。如果temp有值,就將temp的值存放到data裡。如果temp沒有值,也就是fetchone()再也拿不出資料時,就中斷while迴圈。
看了這些證據,還想否認你剛才在 Heroku Postgres裡創造了一個表格嗎?
可惡,看來只好把表格刪掉來湮滅證據了:
In [6]: import os
import psycopg2
DATABASE_URL = os.popen('heroku config:get DATABASE_URL -a 你-APP-的名字').read()[:-1]
conn = psycopg2.connect(DATABASE_URL, sslmode='require')
cursor = conn.cursor()
delete_table_query = '''DROP TABLE IF EXISTS alpaca_training'''
cursor.execute(delete_table_query)
conn.commit()
大家可以看一下第六行程式碼: delete_table_query = '''DROP TABLE IF EXISTS alpaca_training'''
我們用DROP這個關鍵字把存在 Heroku Postgres 中的表格給刪掉。用IF EXISTS則可以避免你記錯表格名稱而導致程式碼出錯。
好啦,現在再回頭用cursor.execute("SELECT column_name, data_type FROM information_schema.columns WHERE table_name = 'alpaca_training'")檢查看看,是不是一點表格存在的蛛絲馬跡都看不出來啦。
今天就先講到這,大家可以回頭試著在 Heroku Postgres 裡新增一些符合自己需求的表格。我把今天的程式碼也上傳到 Github 了(Github 或 nbviewer),有興趣的可以參考看看。若有不清楚的地方,歡迎直接在下面留言,我會盡可能地回覆大家的。謝謝大家!
➀ Heroku Postgres 官方介紹
➁ SQL wiki
➂ Heroku 資料庫方案 [說明] (https://elements.heroku.com/addons/heroku-postgresql#hobby-dev)
➃ Anaconda Psycopg2 安裝
➄ Psycopg2 使用教學
➅ PostgreSQL 使用教學
➆ PostgreSQL 中文使用手冊
➇ Heroku Postgres 使用說明書
註:對於此系列文有興趣的讀者,歡迎參考由此系列文擴編成書的 LINE Bot by Python,以及最新的系列文《賴田捕手:追加篇》
第 31 天 初始化 LINE BOT on Heroku
第 32 天 快速回覆 QuickReply 介紹
第 33 天 妥善運用 Heroku APP 暫存空間
第 34 天 妥善運用 LINE Notify 免費推播
第 35 天 製造 Deploy to Heroku 按鈕
老師好,一路從第一天看到第十五天,目前遇到2個問題~再麻煩協助~謝謝
1.終端機使用heroku相關指令時,原先回應速度都蠻快的,接下來使用都會有延遲狀況是正常的嗎~?
2.第十五天的程式碼,本來都還正常可以執行,但現在執行都會跑出以下訊息
could not connect to server: Connection timed out (0x0000274C/10060)
Is the server running on host "ec2-52-2-82-109.compute-1.amazonaws.com" (51.2.82.110) and accepting
TCP/IP connections on port 5432?
查了 https://bbs.csdn.net/topics/391023489
搜尋電腦,沒有pg_hba.conf這文件可以修改,也不太知道怎麼操作..
您好
先說結論,您提的這兩個問題,我剛才試了一下,也不確定可能的原因是什麼。
不過我試著想了一些可能性,您可以回去嘗試看看有沒有比較改善。
C:\Users\YourName>heroku --version
heroku/7.47.5 win32-x64 node-v12.16.2
我目前的 Heroku CLI 的版本是 7.47.5。
需要更新的話,只要在命令提示字元執行時輸入以下指令即可更新:
C:\Users\YourName>heroku update
heroku login -i,接著輸入帳密,確認有登入 Heroku 帳號C:\Users\YourName>heroku login -i
heroku: Enter your login credentials
Email: 你的帳號 Email
Password: **********
Logged in as 你的帳號 Email
C:\Users\YourName>heroku addons -a 你-APP-的名字
Add-on Plan Price State
───────────────────────────── ───────── ───── ───────
heroku-postgresql(postgresql) hobby-dev free created
└─ as DATABASE
import os
import psycopg2
DATABASE_URL = os.popen('heroku config:get DATABASE_URL -a 你-APP-的名字').read()[:-1]
conn = psycopg2.connect(DATABASE_URL, sslmode='require')
cursor = conn.cursor()
query = 'SELECT table_name FROM INFORMATION_SCHEMA.TABLES'
cursor.execute(query)
cursor.fetchone()
順利的話,應該會看到你在該資料庫當中所建立的表格名稱,如下:
('YourTableName')
可以先試著檢查看看這些。若有問題歡迎再提出討論看看。
都順利解決了,感謝老師。
我將Heroku CLI 版本更新至 7.47.6,
以上2個問題都解決了,感謝!!!!
您好,
首先謝謝你寫的,我學了很多。我是新手很多不會。
我用了您寫的代碼,一直出現錯誤。
import os
import psycopg2
DATABASE_URL = os.popen('heroku config:get DATABASE_URL -a bot-all-day-long').read()[:-1]
conn = psycopg2.connect(DATABASE_URL, sslmode='require')
cursor = conn.cursor()
query = 'SELECT table_name FROM INFORMATION_SCHEMA.TABLES'
cursor.execute(query)
cursor.fetchone()
錯誤訊息是:
OperationalError Traceback (most recent call last)
<ipython-input-20-97d5072dff48> in <module>
4 DATABASE_URL = os.popen('heroku config:get DATABASE_URL -a bot-all-day-long').read()[:-1]
5
----> 6 conn = psycopg2.connect(DATABASE_URL, sslmode='require')
7 cursor = conn.cursor()
8
/srv/conda/envs/notebook/lib/python3.6/site-packages/psycopg2/__init__.py in connect(dsn, connection_factory, cursor_factory, **kwargs)
120
121 dsn = _ext.make_dsn(dsn, **kwargs)
--> 122 conn = _connect(dsn, connection_factory=connection_factory, **kwasync)
123 if cursor_factory is not None:
124 conn.cursor_factory = cursor_factory
OperationalError: could not connect to server: No such file or directory
Is the server running locally and accepting
connections on Unix domain socket "/tmp/.s.PGSQL.5432"?
不知道該怎麼辦。
我的目的是想寫一個line小機器人可以記錄聯繫人的電話號碼,然後想找人時可以輸入人名,小機器人會給你需要的電話號碼或資料。
但是我鏈接postgres一直失敗,真的無能為力了才註冊賬號發問。 有好多問題, 您寫的這些代碼都應該放在哪個文件裡面?
您第十七天寫的最後的代碼,我將問題寫在裡面希望你可以盡量解答。
import os
import psycopg2
def line_insert_record(record_list):
DATABASE_URL = os.environ['DATABASE_URL']
conn = psycopg2.connect(DATABASE_URL, sslmode='require')
cursor = conn.cursor()
table_columns = '(alpaca_name, training, duration, date)'
postgres_insert_query = f"""INSERT INTO alpaca_training {table_columns} VALUES (%s,%s,%s,%s)""" #這個是執行query的術語,我的問題是,表格是在哪裡什麼時候建立的?這個表格也是在小機器人的主文件裡創建的嗎? 那每次呼叫小機器人會不會一直重新建立新表格?
cursor.executemany(postgres_insert_query, record_list)
conn.commit()
message = f"恭喜您! {cursor.rowcount} 筆資料成功匯入 alpaca_training 表單!"
print(message) #之前小機器人回復不是都是靠“line_bot_api.reply_message(event.reply_token, message)” 來回復的嗎? 這裡print可以直接回復嗎?
cursor.close()
conn.close()
return message #這個message 最後反饋給這個function,但是又是誰叫了這個function?主要問題還是如何實現小機器人回復想要信息。
謝謝


 iThome鐵人賽
iThome鐵人賽